前の3件 | -
GoldenGateでレプリカ表に更新日付を入れる [GoldenGate]
1.はじめに
最近の案件で、GoldenGateを使ってレプリケーションする際に、更新日付を入れられないか、という問い合わせがあった。初回INSERT時と、UPDATEされたときに、それぞれ更新日付を記録したいという要件である。実現方式を調べて、OCIで動作確認したので、備忘までメモしておく。
検証はOCIで、BaseDBと、適当なコンピュート上に構成したGoldenGate(マイクロサービス)で行った。BaseDBは1台の上に、ORADBとORADBREPという2つのPDBを構成し、ORADBのEMP表をORADBREPにレプリケーションした。その際、更新日付のない通常のレプリケーション(EMP表)と更新日付のあるレプリケーション(EMPREP表)の2つのレプリカを作成した。
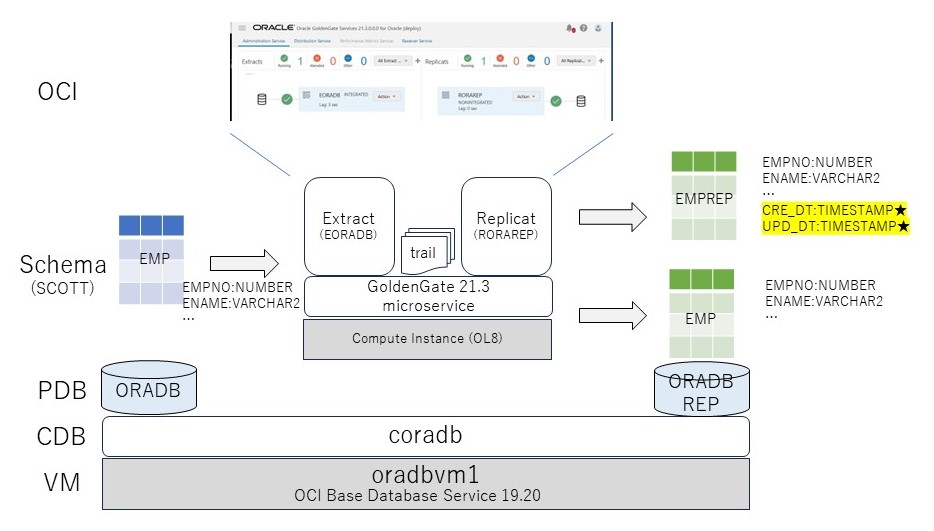
2.検証モデル
ソース側となるORADBのEMP表は以下の通り。初期データとして100万件入れておく。また、レプリカの初期同期用にダンプを作成する。
EMP表 Name Null? Type ----------------------------------------- -------- ---------------------------- EMPNO NOT NULL NUMBER(7) ENAME VARCHAR2(10) JOB VARCHAR2(9) MGR NUMBER(7) HIREDATE DATE SAL NUMBER(7,2) COMM NUMBER(7,2) DEPTNO NUMBER(7)
ターゲット側となるORADBREPのEMP表、EMPREP表は以下の通り。初期データとして100万件入れておく。EMPREP表には、CRE_DTとUPD_DTが追加されている。初期データとしてソースのダンプをインポートする。EMPREPはカラムが追加されているので、インポート時はNULLで入る。
EMP表 Name Null? Type ----------------------------------------- -------- ---------------------------- EMPNO NOT NULL NUMBER(7) ENAME VARCHAR2(10) JOB VARCHAR2(9) MGR NUMBER(7) HIREDATE DATE SAL NUMBER(7,2) COMM NUMBER(7,2) DEPTNO NUMBER(7) EMPREP表 Name Null? Type ----------------------------------------- -------- ---------------------------- EMPNO NOT NULL NUMBER(7) ENAME VARCHAR2(10) JOB VARCHAR2(9) MGR NUMBER(7) HIREDATE DATE SAL NUMBER(7,2) COMM NUMBER(7,2) DEPTNO NUMBER(7) CRE_DT TIMESTAMP(6)★作成日付 UPD_DT TIMESTAMP(6)★更新日付
次にGGの設定である。エクストラクトの設定は以下の通り。トレイルとして出力する対象として、ORADBのSCOTTスキーマのオブジェクトを指定した。
EXTRACT EORADB USERIDALIAS CORADB_ORADBVM1 DOMAIN ORADBVM1 EXTTRAIL AA TABLE ORADB.SCOTT.*;
レプリキャットの設定は以下の通り。非統合レプリキャットを使った。MAP文でEMP表とEMPREP表にレプリケートする設定としている。このうち、EMPは単純なMAP文(単純に全てのカラムをマッピング)しているが、EMPREPの方はCOLMAPでCRE_DTとUPD_DTカラムに更新日付を入れる処理を追加している。ここが今回のポイントである。
REPLICAT RORAREP
USERIDALIAS ORADBREP DOMAIN ORADBVM1
SOURCECATALOG ORADB
MAP SCOTT.EMP, TARGET SCOTT.EMP;
MAP SCOTT.EMP, TARGET SCOTT.EMPREP,
COLMAP(USEDEFAULTS,
cre_dt=@IF(@STREQ(@GETENV('GGHEADER','OPTYPE'),'INSERT'),@DATENOW(),@COLSTAT(MISSING)),
upd_dt=@IF(@VALONEOF(@GETENV('GGHEADER','OPTYPE'), 'UPDATE', 'SQL COMPUPDATE', 'PK UPDATE'), @DATENOW(), @COLSTAT(MISSING)));
少し補足すると、@GETENV('GGHEADER','OPTYPE')はDMLの種類を返す関数である。この返り値がINSERTなのかUPDATEなのかを、@STREQで文字列が一致するか、@VALONEOFでいくつかの選択肢のうち1つが一致すれば真を返す関数を利用し、@IFで切り替える。設定値は、現在時刻である@DATENOWを設定するか、何も設定しない@COLSTAT(MISSING)を設定する。なお、UPDATEとSQL COMPUPDATEの違いは、UPDATEが全てのカラムを含むのに対し、SQL COMPUPDATEは更新対象となるカラムしか含まない場合である(Oracleは通常更新対象となるカラムしかREDOに含まないが、SQL Serverなどでは全てのカラムをログに含めるものもある)。
3.動作確認
ここでは、ソース側のEMP表EMPNO=1000001のレコードをINSERT、UPDATE(2回)、DELETEを実行して、ターゲット側の状態を確認した。まず、INSERT後の状態である。正しくターゲットのEMP、EMPREP表にレコードが伝搬されている。また、EMPREPには、作成日を示すCRE_DTが入っており、UPD_DTはNULLのままである。
19:57:27 SCOTT@oradb> @insemp
Connected.
19:57:30 SCOTT@oradb> @ckemp
Connected.
★ソース:EMP
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO
---------- ---------- --------- ---------- ----------------- ---------- ---------- ----------
1000001 kazuhiro dba 1 20240408 19:57:30 1000 1000 1
Connected.
★ターゲット:EMP
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO
---------- ---------- --------- ---------- ----------------- ---------- ---------- ----------
1000001 kazuhiro dba 1 20240408 19:57:30 1000 1000 1
★ターゲット:EMPREP
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO CRE_DT UPD_DT
---------- ---------- --------- ---------- ----------------- ---------- ---------- ---------- -------------------- --------------------
1000001 kazuhiro dba 1 20240408 19:57:30 1000 1000 1 20240408 19:57:32
次にUPDATE後の状態である。正しくターゲットのEMP、EMPREP表にSAL,COMが+1されて伝搬されている。また、EMPREPには、更新日付を示すUPD_DTが入る。
19:57:35 SCOTT@oradb> @updemp
Connected.
19:57:39 SCOTT@oradb> @ckemp
Connected.
★ソース:EMP
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO
---------- ---------- --------- ---------- ----------------- ---------- ---------- ----------
1000001 kazuhiro dba 1 20240408 19:57:39 1001 1001 1
Connected.
★ターゲット:EMP
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO
---------- ---------- --------- ---------- ----------------- ---------- ---------- ----------
1000001 kazuhiro dba 1 20240408 19:57:39 1001 1001 1
★ターゲット:EMPREP
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO CRE_DT UPD_DT
---------- ---------- --------- ---------- ----------------- ---------- ---------- ---------- -------------------- --------------------
1000001 kazuhiro dba 1 20240408 19:57:39 1001 1001 1 20240408 19:57:32 20240408 19:57:42
もう一度UPDATEを実行した後の状態である。正しくターゲットのEMP、EMPREP表にSAL,COMが+1されて伝搬されている。EMPREPは、更新日付を示すUPD_DTが更新されている。
19:57:48 SCOTT@oradb> @updemp
Connected.
19:57:53 SCOTT@oradb> @ckemp
Connected.
★ソース:EMP
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO
---------- ---------- --------- ---------- ----------------- ---------- ---------- ----------
1000001 kazuhiro dba 1 20240408 19:57:53 1002 1002 1
Connected.
★ターゲット:EMP
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO
---------- ---------- --------- ---------- ----------------- ---------- ---------- ----------
1000001 kazuhiro dba 1 20240408 19:57:53 1002 1002 1
★ターゲット:EMPREP
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO CRE_DT UPD_DT
---------- ---------- --------- ---------- ----------------- ---------- ---------- ---------- -------------------- --------------------
1000001 kazuhiro dba 1 20240408 19:57:53 1002 1002 1 20240408 19:57:32 20240408 19:57:58
DELETEを実行した後は、正しくターゲットのEMP、EMPREP表がDELETEされることも確認した。
4.まとめ
本稿では、GoldenGateを使ってレプリカを作成する際に、更新日付を追加する方法について、実機検証した結果を記載した。日付を入れる処理ロジックは若干複雑であるが、このような柔軟な対応ができるのは、GoldenGateの良いところである。Goldengateの構成方法についてはまた別の機会に触れたいと思う。
参考
[1]Reference for Oracle GoldenGate, 2.18 @GETENV
2024-04-09 23:36
バインドミスマッチのSQLの特定方法の一考察 [オプティマイザ]
1.はじめに
以前の記事でバインドミスマッチによる性能遅延の問題について記載した。その中で、この問題を発生させないようにするためには、Java等のアプリケーションでバインド変数に適切な型を設定することが重要であることを述べた。そのためにはアプリケーションを開発する技術者にOracleのアーキテクチャを理解して設計することが求められると同時に、設計や実装段階でこの問題を検出する仕組みが必要である。
しかし、実際問題、アプリケーションの開発者はOracleのアーキテクチャに詳しい訳でもなく、試験において機能確認以上にバインド型の妥当性まで確認することはなかなか難しい。そもそも、その必要性を理解してもらうことすらままならないのが現実である。
そこで考えたのが、データベースに流れているSQLの中で、問題を発生させる可能性のあるSQLを一括して調査する方法である。これができれば、アプリケーションの開発や性能試験の中で、バインドミスマッチの問題が発生する可能性のあるSQLを(全てではないにしろ)検出し、開発者に修正を促すことができる。ここではそのようなSQLを考えてみたい。
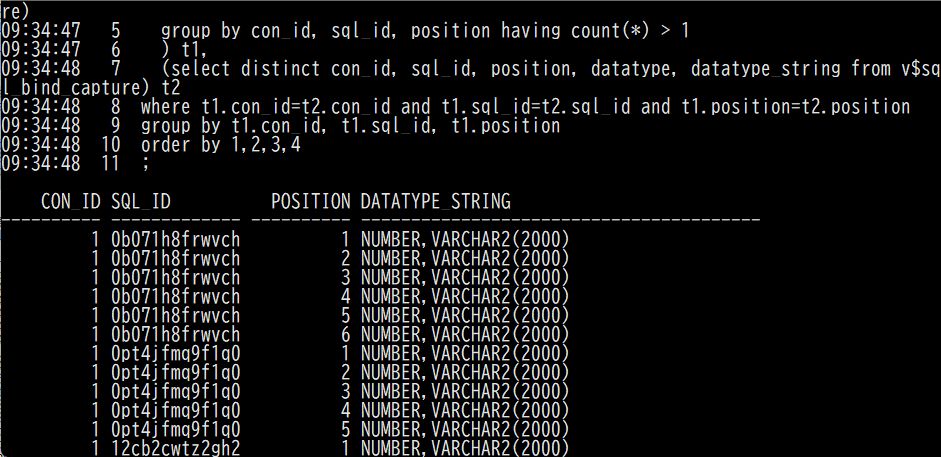
2.バインドミスマッチのSQLの特定方法
v$sql_bind_captureには、SQL_ID毎に、バインドポジションとバインド型の情報が格納されている。バインドミスマッチが発生している場合は、同じバインドポジションに異なる複数のバインド型が割り当てられるはずである。この性質を利用して、SQL_ID、バインドポジション、データ型を重複排除し、データ型を複数持つSQL_IDを抽出する。通常はSYS等のシステム系のSQLには興味がないだろうから、v$sqlareaと外部結合してユーザ情報や実行回数、バージョンカウントもあわせて表示する。
上記のアイディアのもと、以下が実際に考えてみたSQLである。バインドミスマッチを起こしていると思われるSQLID一覧を表示するSQLである。
rem (A) sql_ids that have more than one bind types for the same column, order by executions desc
col parsing_schema_name for a20
select t1.con_id, t1.sql_id, num_position, t2.parsing_schema_name, t2.executions, t2.version_count from (
select con_id, sql_id, count(*) num_position
from (
select con_id, sql_id, position, count(*)
from (select distinct con_id, sql_id, position, datatype from v$sql_bind_capture)
group by con_id, sql_id, position having count(*) > 1
)
group by con_id, sql_id
) t1,
v$sqlarea t2
where t1.con_id=t2.con_id(+) and t1.sql_id=t2.sql_id(+) order by executions desc;
SQLだけではイメージがわかないので、実際の実行結果を見てほしい。環境はOCIのADB(ATP)で19.23である。
CON_ID SQL_ID NUM_POSITION PARSING_SCHEMA_NAME EXECUTIONS VERSION_COUNT
---------- ------------- ------------ -------------------- ---------- -------------
326 4f2g5hu1c7yu3 1 SYS 40 2
326 2szhjcqs9agym 1 SYS 29 2
326 fs7h3cb49hs7s 2 SYS 8 2
326 a8ybwb4wf635t 1 SYS 5 2
326 dqdaup2z1508s 2 SYS 5 2
326 bmrrsf60dp618 1 SYS 5 2
326 3sp9hj44p632r 5 SYS 5 2
326 ch8t72tsys7vx 1 SYS 5 2
326 fu9xz9pnu520q 1 SYS 3 2
9 rows selected.
例えば、一番上の4f2g5hu1c7yu3は、1か所のバインドポジションにおいて、バインドミスマッチが発生している。このSQLはSYSで実行されており、実行回数累計40回、バージョンカウントは2であることがわかる。1か所のバインドミスマッチであれば、子カーソルが増えてもたかが知れているし、実行回数もたいして多くないため、問題ない、ということがわかる。下から3番目の3sp9hj44p632rは、5か所のバインドポジションにおいて、バインドミスマッチが発生している。仮にこのバリエーションが増えると、最大2^5=~32個程度だろうし、問題ない。
仮に上記で問題となりそうなSQLが見つかったとき、具体的にどのようなバインドミスマッチが発生しているかが気になる。バインドポジション毎にどのような型が使われているのかを表示するSQLが以下である。
rem (B) bind type names for each sql_id and bind position col datatype_string for a40 select t1.con_id, t1.sql_id, t1.position, listagg(t2.datatype_string,',') within group (order by t2.position) datatype_string from (select con_id, sql_id, position,count(*) from (select distinct con_id, sql_id, position, datatype from v$sql_bind_capture) group by con_id, sql_id, position having count(*) > 1 ) t1, (select distinct con_id, sql_id, position, datatype, datatype_string from v$sql_bind_capture) t2 where t1.con_id=t2.con_id and t1.sql_id=t2.sql_id and t1.position=t2.position group by t1.con_id, t1.sql_id, t1.position order by 1,2,3,4 ;
こちらの実行結果は以下の通り。
CON_ID SQL_ID POSITION DATATYPE_STRING
---------- ------------- ---------- ----------------------------------------
326 2szhjcqs9agym 1 NUMBER,VARCHAR2(2000)
326 3sp9hj44p632r 1 NUMBER,VARCHAR2(2000)
326 3sp9hj44p632r 2 NUMBER,VARCHAR2(2000)
326 3sp9hj44p632r 3 NUMBER,VARCHAR2(2000)
326 3sp9hj44p632r 4 NUMBER,VARCHAR2(2000)
326 3sp9hj44p632r 5 NUMBER,VARCHAR2(2000)
326 4f2g5hu1c7yu3 1 NUMBER,VARCHAR2(2000)
326 a8ybwb4wf635t 1 NUMBER,VARCHAR2(2000)
326 bmrrsf60dp618 1 NUMBER,VARCHAR2(2000)
326 ch8t72tsys7vx 1 NUMBER,VARCHAR2(2000)
326 dqdaup2z1508s 1 NUMBER,VARCHAR2(2000)
326 dqdaup2z1508s 2 NUMBER,VARCHAR2(2000)
326 fs7h3cb49hs7s 1 NUMBER,VARCHAR2(2000)
326 fs7h3cb49hs7s 2 NUMBER,VARCHAR2(2000)
326 fu9xz9pnu520q 1 NUMBER,VARCHAR2(2000)
15 rows selected.
例えば、3sp9hj44p632rを見てみると、バインドポジションが1から5について、NUMBER型とVARCHAR2(2000)でバインドミスマッチが発生していることがわかる。他のSQLについても、この例では全てNUMBERとVARCHAR2(2000)のバインドミスマッチである。
以下の例は、BaseDBの19.20であるが、DATEとVARCHAR2(2000)でバインドミスマッチが発生している。実際のアプリケーションではTIMESTAMP型やLOB型も出てくるかもしれない。
CON_ID SQL_ID POSITION DATATYPE_STRING
---------- ------------- ---------- ----------------------------------------
...
3 531x22ur6bxc1 1 NUMBER,VARCHAR2(2000)
3 531x22ur6bxc1 2 NUMBER,VARCHAR2(2000)
3 531x22ur6bxc1 4 NUMBER,VARCHAR2(2000)
3 531x22ur6bxc1 7 DATE,VARCHAR2(2000)
3 531x22ur6bxc1 10 DATE,VARCHAR2(2000)
3 59xng0tdsqw0s 1 NUMBER,VARCHAR2(2000)
3 59xng0tdsqw0s 2 NUMBER,VARCHAR2(2000)
3 59xng0tdsqw0s 4 NUMBER,VARCHAR2(2000)
3 59xng0tdsqw0s 5 DATE,VARCHAR2(2000)
...
リスクのあるSQL_IDが特定できたら、この後の流れは通常と同じである。以下のようにv$sql_bind_captureでSQL_IDを指定してバインド型の状態を確認する。
select con_id,sql_id, child_number, position, datatype, datatype_string from v$sql_bind_capture
where sql_id='3sp9hj44p632r';
CON_ID SQL_ID CHILD_NUMBER POSITION DATATYPE DATATYPE_STRING
---------- ------------- ------------ ---------- ---------- ----------------------------------------
4 3sp9hj44p632r 3 1 2 NUMBER
4 3sp9hj44p632r 3 2 2 NUMBER
4 3sp9hj44p632r 3 3 2 NUMBER
4 3sp9hj44p632r 3 4 2 NUMBER
4 3sp9hj44p632r 3 5 2 NUMBER
4 3sp9hj44p632r 2 1 1 VARCHAR2(2000)
4 3sp9hj44p632r 2 2 1 VARCHAR2(2000)
4 3sp9hj44p632r 2 3 1 VARCHAR2(2000)
4 3sp9hj44p632r 2 4 1 VARCHAR2(2000)
4 3sp9hj44p632r 2 5 1 VARCHAR2(2000)
SQL_IDのSQLはv$sqlareaで確認できるだろう。アプリケーションのスキーマとSQLが特定できれば、開発者に修正を促すことができる。
col sql_text for a60
col parsing_schema_name for a20
select sql_id, parsing_schema_name, sql_text from v$sqlarea where sql_id='3sp9hj44p632r'
SQL_ID PARSING_SCHEMA_NAME SQL_TEXT
------------- -------------------- ------------------------------------------------------------
3sp9hj44p632r SYS select 1, max(id) from wri$_adv_objects where task_id = :1
union all select 2, max(id) from wri$_adv_recommendations w
here task_id = :1 union all select 3, max(id) from wri$_adv_
actions where task_id = :1 union all select 4, max(id) from
wri$_adv_findings where task_id = :1 union all select 5, m
ax(id) from wri$_adv_rationale where task_id = :1
3.考察
この方法で検出されたSQLについてアプリケーションの修正を促すべきSQLをどう評価したらよいだろうか。バインドミスマッチはバインドポジション数に対し2のべき乗で増加する。(A)のNUM_POSITIONが10以下であるSQLは子カーソル数は最大でもたかだか1000程度であり、Oracleのデフォルトの子カーソル数の閾値(19cで8,192)に十分収まる範囲と考えられる。(A)のNUM_POSITIONが10より大きいSQLIDについてはデータのバリエーションにより子カーソル数が1000を超えるリスクがあるため、アプリケーションを修正することが望ましいだろう。ただ実際は、業務特性として(A)のEXECUTIONSが大きくならず、並列実行されないことがわかっているのであれば、アプリケーション修正なしでも問題は顕在化しない。そう考えると、やはり一番の入り口は、バインドポジションの数である。バインドポジション数が極端に大きなSQLがないか、そこで子カーソル数が多くなっていないか、このSQLは業務的に頻繁に並列に実行される特性のものか、を確認し、全てYESならアプリケーションを修正した方が良いと私は考える。
(A)や(B)のSQLをどのタイミングで利用すべきだろうか。(A)は結合試験以降である程度実際の業務に近い状態にならないと、データバリエーションや実行回数が意味のある数字にならないだろう。それでも、リスクのあるSQLを早期に特定する目的には使える。(B)は単体試験から使えるだろう。NULL値等のバリエーションを含めた機能的な試験を行うだろうから、バインドミスマッチが発生するようなコーディングを検出できる可能性がある。
4.まとめ
本記事では、バインドミスマッチが発生しているSQLを特定する方法について述べた。この方法では、SQLの実行回数、子カーソル数とあわせて、バインドミスマッチが発生しているバインドポジション数を見て評価ができる点がポイントである。思い付きのプロトタイプレベルのSQLではあるものの、今後の開発の中で利用して改善していければと思っている。
MOSのDocID 438755.1のドキュメント[1]に、子カーソルが増加しているSQLのレポートを作成するスクリプトが公開されているので、こちらとあわせて使うとよいだろう。
参考
[1] Document 438755.1 High SQL Version Counts - Script to determine reason(s)
2024-04-01 09:41
補助インスタンスを用いた表単位のリカバリ [アーキテクチャ]
1.はじめに
最近関わっている案件で、DBは遠隔の災対環境へ常時同期し、罹災時に災対環境に切り替えする、ただし特定の表(複数)だけ、前日の特定リストアポイントに復旧したい、という要件があった。いくつか検討した方式が以下であった。
(a)災対同期をGoldenGate等論理レプリケーションとし表毎に同期を制御できるようにする
(b)災対同期はDataGuardで物理レプリケーションとし、フェールオーバー後に
(b-1)前日断面のエクスポートを取得しておき、それをインポートする
(b-2)フラッシュバックテーブルで特定表を復旧
(b-3)補助インスタンスを用いた表単位のリカバリ
このうち、(a)は災対側の維持運用の負荷が高いので、(b)の方向性が望ましい。ActiveDataGuardなら(b-1)方式で、災対側でエクスポートしておくのがシンプルだ。しかし、表数やサイズが大きいと罹災時のRTOが許容できるか、ダンプファイルの置き場所やダンプ処理にかかる時間も実運用上許容されるかといった懸念がある。
(b-2)はDBオープン後にフラッシュバックテーブルで特定断面に戻す方法である。フラッシュバックテーブルは内部的にはUNDOを使ってリストアポイントまでリカバリする。母体の表サイズが大きくても更新が少なければ高速に処理が完了する。リストアポイントまでのUNDOが上書きされないよう、十分にUNDOリテンションを確保する必要がある。リストアポイントまでの間にalter table等のDDLが実行された場合はフラッシュバックテーブルは使えない(エラーとなる)という制約があり、プライマリ側で定義変更後に罹災するなど刹那なタイミングで復旧できないリスクがあるため、これだけに頼るのもリスクがある。
そこで(b-3)補助インスタンスを用いた表単位のリカバリである。これはRMANバックアップとアーカイブログを利用し、仮のインスタンスを立てて特定の(複数の)表をリカバリする機能である。災対側でもRMANのバックアップがとられていれば、そこから表の特定時点の断面を取り出すことができる。
今回、この補助インスタンスを用いた表単位のリカバリを実際に行い、補助インスタンスを利用した表リカバリについて考察してみたい。
2.検証モデル
ここでは、補助インスタンスを使った表単位のリカバリで、PDB上のSCOTT.EMPを特定のリストアポイント(=SCN)にリカバリしてみる(その他のDBは最新状態のまま)。テスト環境は手元のVirtual BoxのOracle19.11を使う。テスト準備として、アーカイブログモードとし、RMANフルバックアップを取得する。補助インスタンスリストア用に/mntをC:\Users\kazuhiro\Downloadsにマウントしておく(VirtualBoxの共有フォルダの設定)。
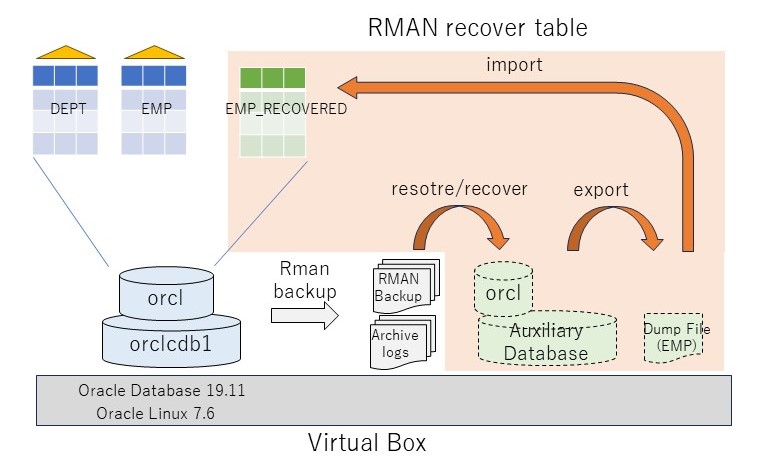
テストシナリオは以下の通り:
- PDB名ORCLのSCOTT.EMP/DEPTを作成、初期データを挿入
- リストアポイント取得
- EMPにINSERT 1件
- EMPをリストアポイントにリカバリした内容をEMP_RECOVER表に復旧
テストのコマンドは以下の通り。ポイントは★の部分のRMANコマンドで、recover tableで、EMP表をEMP_RECOVERED表に復旧するようにしている。なお、@empはemp表の作成スクリプトである。EMP表には初期データとして14件、リストアポイント作成後にempno=9999を1行を追加している。したがって、復旧した際には15件ではなく、14件となることが期待である。
rman target /
backup as compressed backupset database;
--EMP表作成
sqlplus scott/oracle@orcl
@emp
select count(*) from dept;
select count(*) from emp;
--リストアポイント(zenjitu)を作成
sqlplus sys/oracle@orcl as sysdba
create restore point zenjitu;
--リストアポイント後の更新を実行
sqlplus scott/oracle@orcl
insert into emp
values(
9999, 'KAZUHIRO', 'TAKAHASHI', 7000,
to_date('08-03-2024','dd-mm-yyyy'),
1000, null, 10
);
commit;
select count(*) from emp;
select * from emp where empno=9999;
exit
--★表のリカバリ(EMP表をEMP_RECOVERED表に復旧する)
rman target /
recover table scott.emp of pluggable database orcl until restore point ZENJITU auxiliary destination '/mnt' REMAP TABLE 'SCOTT'.'EMP':'EMP_RECOVERED' ;
select count(*) from dept;
select count(*) from emp;
select * from emp where empno=9999;
select segment_name, bytes, blocks from user_segments;
desc emp
desc emp_recovered
3.検証結果
補助インスタンスを用いた表のリカバリは、内部的に以下の動作を行っていることがわかった(検証結果のログは参考[1]を参照されたい)。ポイントとなる部分に★を付けたので、ここだけ追えば概ね流れは理解できるだろう。
SID='gicq'でインスタンスを起動 SCNをリストアポイントに設定 制御ファイルをリストア ★①補助インスタンス用制御ファイル クローンデータベースをマウント ログスイッチ SCNをリストアポイントに設定 クローンデータファイルの1,9,4,11,3,10とtempファイルの1,3に新しい名前を付与 全てのtempfileをスイッチ クローンデータファイルをリストア(1,9,4,11,3,10) ★②CDBリストア 全てのクローンデータファイルをスイッチ SCNをリストアポイントに設定 クローンデータファイルをオンライン(1,9,4,11,3,10) クローンデータベースの表領域をリカバリ ★③CDBメディアリカバリ "SYSTEM", "ORCL":"SYSTEM", "UNDOTBS1", "ORCL":"UNDOTBS1", "SYSAUX", "ORCL":"SYSAUX" クローンデータベースをリードオンリーでオープン クローンのPDBをオープン(ORCL) クローンでspfileをメモリから生成 クローンをシャットダウン クローンをnomountで起動 制御ファイルを設定(①でリストアしたファイル) クローンをシャットダウン クローンをnomountで起動 クローンをマウント SCNをリストアポイントに設定 クローンデータファイルの12に新しい名前を付与 クローンデータファイルをリストア(12) ★④PDBリストア 全てのクローンデータファイルをスイッチ SCNをリストアポイントに設定 クローンORCLのデータファイルをオンライン(12) クローンデータベースの表領域をリカバリ ★⑤PDBメディアリカバリ "ORCL":"USERS", "SYSTEM", "ORCL":"SYSTEM", "UNDOTBS1", "ORCL":"UNDOTBS1", "SYSAUX", "ORCL":"SYSAUX" delete archivelog クローンデータベースをリセットログでオープン クローンのPDBをオープン(ORCL) ORCLにディレクトリオブジェクトを作成する(TSPITR_DIROBJ_DPDIR as /mnt) クローンのORCLにディレクトリオブジェクトを作成する(TSPITR_DIROBJ_DPDIR as /mnt) 表のエクスポート(/mnt/tspitr_gicq_28603.dmp) ★⑥表エクスポート クローンデータベースをシャットダウン(abort) 表のインポート ★⑦表インポート 自動インスタンスの削除
復旧後の結果確認をしたところ、想定通りEMP_RECOVEREDが作成されている。件数は14件で、INSERTの更新前のリストアポイントに復旧していることがわかる。
[oracle@localhost ~]$ sqlplus scott/oracle@orcl
...
SQL> select table_name from user_tables;
TABLE_NAME
--------------------------------------------------------------------------------
DEPT
EMP
EMP_RECOVERED ★
SQL>
SQL> select count(*) from EMP_RECOVERED;
COUNT(*)
----------
14
SQL>
SQL> select * from emp where empno=9999;
EMPNO ENAME JOB MGR HIREDATE SAL COMM
---------- ---------- --------- ---------- --------- ---------- ----------
DEPTNO
----------
9999 KAZUHIRO TAKAHASHI 7000 08-MAR-24 1000
10
SQL> select * from EMP_RECOVERED where empno=9999;
no rows selected
セグメントの状態を確認すると、EMP_RECOVEREDにはPKの索引がない。表の定義を確認すると、EMPNOのNOT NULL制約がなくなっていた。FK制約もない。データは復旧できるが、表の制約は外れてしまうようだ。
SQL> select segment_name, bytes, blocks from user_segments; SEGMENT_NAME BYTES BLOCKS ________________ ________ _________ DEPT 65536 8 EMP 65536 8 EMP_RECOVERED 65536 8 ★対応するPK索引がない PK_DEPT 65536 8 PK_EMP 65536 8 SQL> SQL> desc emp Name Null? Type ___________ ___________ _______________ EMPNO NOT NULL NUMBER(4) ENAME VARCHAR2(10) JOB VARCHAR2(9) MGR NUMBER(4) HIREDATE DATE SAL NUMBER(7,2) COMM NUMBER(7,2) DEPTNO NUMBER(2) SQL> desc emp_recovered Name Null? Type ___________ ________ _______________ EMPNO NUMBER(4) ★NOT NULLがない ENAME VARCHAR2(10) JOB VARCHAR2(9) MGR NUMBER(4) HIREDATE DATE SAL NUMBER(7,2) COMM NUMBER(7,2) DEPTNO NUMBER(2) SQL> SQL> select index_name from user_indexes; INDEX_NAME _____________ PK_DEPT PK_EMP SQL> select constraint_name,constraint_type,table_name,status from user_constraints; CONSTRAINT_NAME CONSTRAINT_TYPE TABLE_NAME STATUS __________________ __________________ _____________ __________ FK_DEPTNO R EMP ENABLED PK_DEPT P DEPT ENABLED PK_EMP P EMP ENABLED ★EMP_RECOVEREDに対応するPK制約がない SQL>
4.考察
今回の検証を通して分かったことは以下の通り
- recover table scott.emp of pluggable database orcl until restore pointで特定の表の断面を復旧させることが可能
- 補助インスタンスに必要なメモリ(SGAのサイズ)は元のDBと同じ
- 補助インスタンスに必要な領域はSYSTEM、SYSAUX、UNDO(CDBとPDB)+復旧したい表の格納されている表領域を構成するデータファイルの合計サイズ+TEMP(CDBとPDB)+REDO+リストアが必要なアーカイブログ
- 復旧時間は上記ファイルのリストアおよびSCNまでのリカバリ時間+エクスポート+インポートの時間
- 復旧した表は制約が外れる
今回の検証結果を踏まえると、データの内容は復旧できるが、表の制約や関連する索引は復旧できない。元表をドロップして、recover tableで戻したとしても、その状態から制約や索引を付与する対処をすることは、運用上結構厳しいかもしれない。それならば、今回のように別名で一度復旧させて、元表をトランケートし、insert into selectでコピー、リストアした表をドロップが良いだろう。一時的にこの表の領域が2倍必要となるが、表毎の個別対応をするよりはシンプルに復旧できる。
SQL> truncate table emp; Table EMP truncated. SQL> insert /*+ append */ into emp select * from emp_recovered; 14 rows inserted. SQL> commit; Commit complete. SQL> drop table emp_recovered; Table EMP_RECOVERED dropped. SQL>
もう一つ考えられるのは、RESTOREコマンドにNOTABLEIMPORT句をつけて、ダンプの出力で留めておく方法である。インポートする際にトランケートモード、DATA_ONLYでインポートすれば、索引を維持したままデータを復旧できるし、DB領域は余計にかからないだろう。
22.1.3.4 リカバリされた表および表パーティションのターゲット・データベースへのインポートについて デフォルトでは、RMANは、リカバリされた表または表パーティション(エクスポート・ダンプ・ファイルに格納される)をターゲット・データベースにインポートします。ただし、RESTOREコマンドのNOTABLEIMPORT句を使用すると、リカバリされた表または表パーティションをインポートしないように選択できます。
もしリストアポイント後に定義変更がされていた場合、元表と復旧した表とで定義が異なることになる。この場合はやはり表は再作成(必要な索引も含め)した上で、上記いずれかの対応を取ることになるのだろう。データやオブジェクトの依存関係を考えなければならないという点で、オブジェクトレベルのリカバリは本質的に難易度が高くなるのは仕方がない。
5.まとめ
本稿では補助インスタンスを用いた表のリカバリについて、実機検証した結果を踏まえ活用方法について考察した。総じて言えるのは、バックアップから特定の表の特定の状態のダンプファイルを生成することができる、という点は極めて有用である。本質的には複雑な処理をRMANの1つのコマンドで実現できてしまうのは非常に有難い。
ただ、使いどころという観点では、あまり大量の表に対して実行するケースには向いておらず、特定、あるいはいくつかの表について復旧したい場合に限られるだろう。補助インスタンスは復旧に関連する表領域(を構成するデータファイル)をリストアするため、復旧範囲が広がれば広がるほど、元のデータベースと同じ領域が補助インスタンスに必要となってしまうし、ダンプファイルも大きくなってしまう。
今回の結果を踏まえると、フラッシュバックテーブルが使えるなら、多くの場合でその方が復旧はシンプルで速いだろう。UNDOを大きくとる必要はあるが、バックアップ運用が回れば副作用はないように思う。それでもUNDOが不足した場合(ギャランティでない場合は上書きされてしまう)は復旧できないというリスクがあるし、定義変更の影響もあるので、そういった表についてはこの方法で個別にリカバリすればよいだろう。
今回調べている中で、TSPITRを使った表領域のリカバリもできることが気が付いた。リカバリしたい表(+関連する索引)を表領域にまとめられれば、有効な復旧方法になるかもしれない。この点については、別途検証してみたい。Oracleは様々なリカバリ方法が用意されているので、ユーザ側が要件に対してどこまで使い方をイマジネーションできるかが重要である。
参考
[1]補助インスタンスを用いた表のリカバリ検証のログ20240311_recovertable.txt
[2]バックアップおよびリカバリ・ユーザーズ・ガイド 19c, 22 表および表パーティションのリカバリ
2024-03-16 20:58
前の3件 | -


