ExadataのI/O統計を整理する [アーキテクチャ]
#2019/2/27変更:図を追加
#2021/2/10変更:図を清書
花粉が飛び始めて春の気配を感じる今日この頃である。
先月、性能TmからExadata特有の統計(AWRから確認できるv$sysstatの統計)について問い合わせがあり、smart scanやflash cacheについて取得すべき統計を洗い出した。知っているつもりではあったが、1つ1つの統計を改めて眺めてみると、その示す意味が意外とよくわかっていないことに気がついたた。マニュアルとExpert Exadataを読みながら、1つ1つの統計の意味を調べてみたので、備忘までここに記しておく。
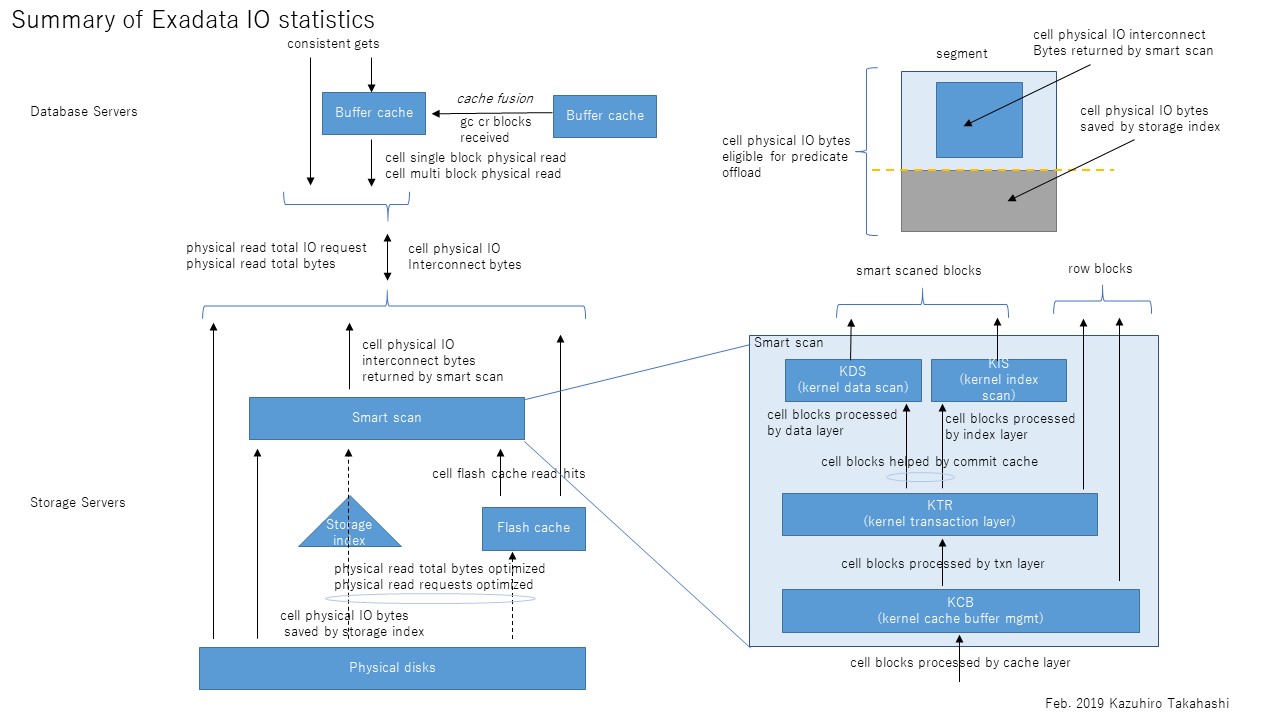
まずExadataのI/Oの全体のアーキテクチャをおさらいしておく。たぶん大体正しい図を書いてみたので、上から順に説明していく。
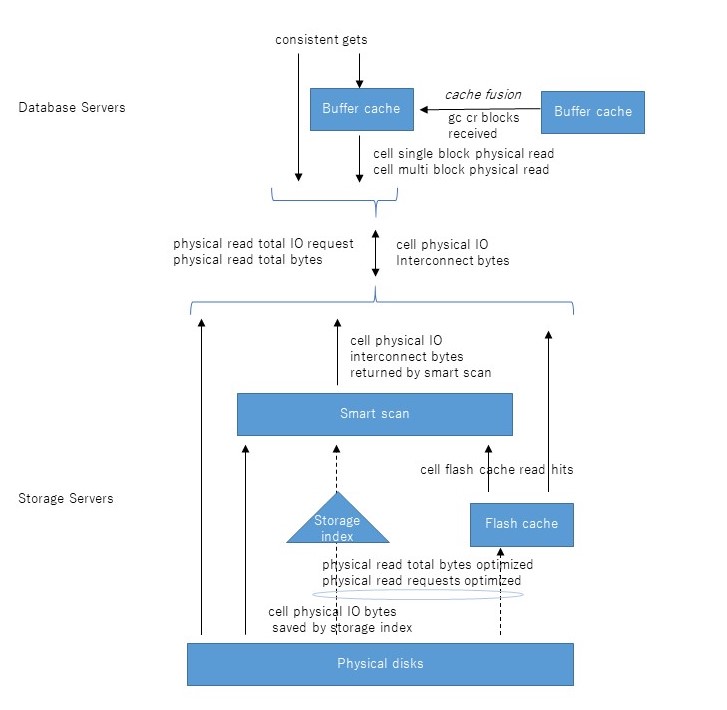
DBサーバでSELECT文を発行するとconsistent gets、すなわち読み取り一貫性を保障するブロック読み込みが発生する。これはローカルDBサーバのバッファキャッシュ上にそのブロックが存在していれば当然そこから読み取られるが、ない場合はcache fusionで他のDBサーバから転送される(gc cr received)。そこにもなければ初めて物理読み込み(physical read bytes等)が発生することとなる。一方、ダイレクトパスリードの場合はバッファキャッシュをバイパスするので、上記の流れはスキップして直接物理読み込みが発生することとなる。
さて、物理読み込みの先は複数のストレージサーバであるが、ここから先がちょっと複雑になる。まず、DBサーバとストレージサーバの間のI/Oを示すのが、cell physical IO interconnect bytesである。これは読み込みだけでなく書き込みも含む、すべてのI/Oのやりとり量を示す統計である。このうち、スマートスキャンにより返却されたI/O量がcell physical IO interconnect bytes returned by smart scanである。これはストレージインデックスやpredicate filtering、column projection等によって削減された後の量である。これらの削減される前のI/O量を示すのがcell physical IO bytes eligible for predicate offloadである。端的には、スマートスキャンがなければDBサーバに返却されたであろうセグメントの全ブロックサイズを示す。従ってスマートスキャンのI/O削減率は以下のように求めることができると考える。
スマートスキャンによるI/O削減率=1- cell physical IO interconnect bytes returned by smart scan / cell physical IO bytes eligible for predicate
これも図にするとイメージし易いだろう。
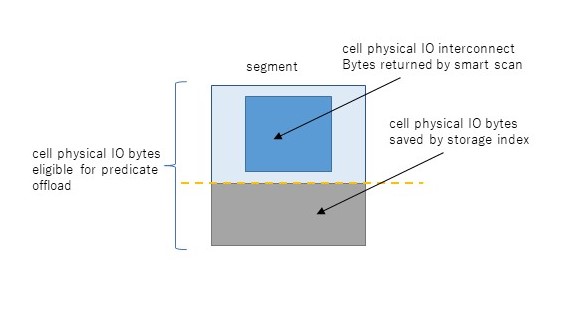
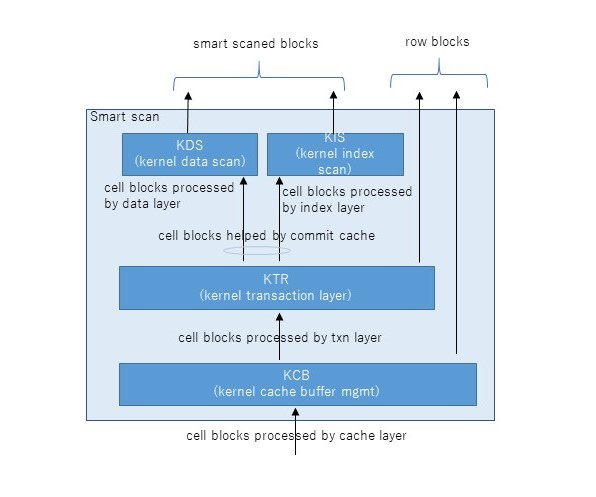
ちなみに話はそれるが、cell physical IO bytes eligible for predicate offloadが0の場合はそもそもスマートスキャンが発生していない状況であることを示す。逆に上記I/O削減率が0の場合はどう考えればよいのだろうか。実はスマートスキャンの3条件が揃っていてスマートスキャンが発生していても、スマートスキャンができずブロックをそのままDBサーバに返却することがある。これはスマートスキャンは読み取り一貫性を保障しつつ、単一ストレージサーバで処理を独立して完結しなければならないこととに関連している。例えば、読み取り一貫性を保障するためにUNDOブロックを読まなければならない場合、ストレージサーバ(cellsrv)はスマートスキャンをあきらめブロックをそのままDBサーバに返却する。同様のことが行連鎖(複数ブロックにレコードがまたがった状態)した表へのアクセスでも発生する。連鎖した先のブロックはASMによる分散で同じストレージサーバ上にある保障はないためである。これらDBサーバへブロックがそのまま返却された場合、スマートスキャンによるI/O削減率が悪化し、DBサーバから大量のsingle block physical readが発生するということが発生する。以下の図はスマートスキャンの部分の内部の流れを示したものだが、右側2つの流れがスマートスキャンにならず、DBサーバへブロックをそのまま返却する流れである。
フラッシュキャッシュにヒットしたI/O数はcell flash cache read hitsで確認できる。physical read total IO requestsに対してどの程度キャッシュヒットしたかがわかる。なお、このtotalの意味はアプリケーション(SQL)だけでなく、バックアップ、リカバリおよびその他のユーティリティを含むIOを示している。totalのないphysical read IO requestsはアプリケーション(SQL)のみのI/Oを示す。従って、フラッシュキャッシュのヒット率は以下の式で求められると考える。
フラッシュキャッシュのヒット率=cell flash cache read hits / physical read total IO requests
フラッシュキャッシュおよびストレージ索引により削減されたI/O量はphysical read total bytes optimizedで確認できる。うち、ストレージインデックス分はcell physical IO bytes saved by storage indexである。ストレージインデックスはスマートスキャンのときだけ使われるが、フラッシュキャッシュは通常のブロックI/Oでも使われる点に留意したい。
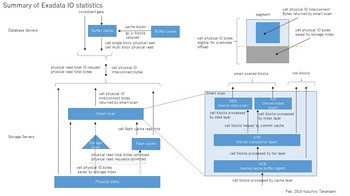
なお、上記多くの内容は以下の参考文献に記載されたものをベースに自らの考察を加えたものなので、正確性は保障できないのであしからず。下図はリファレンスとして使うために上記全体を1枚にまとめてみたものである。
参考文献

#2021/2/10変更:図を清書
花粉が飛び始めて春の気配を感じる今日この頃である。
先月、性能TmからExadata特有の統計(AWRから確認できるv$sysstatの統計)について問い合わせがあり、smart scanやflash cacheについて取得すべき統計を洗い出した。知っているつもりではあったが、1つ1つの統計を改めて眺めてみると、その示す意味が意外とよくわかっていないことに気がついたた。マニュアルとExpert Exadataを読みながら、1つ1つの統計の意味を調べてみたので、備忘までここに記しておく。
まずExadataのI/Oの全体のアーキテクチャをおさらいしておく。たぶん大体正しい図を書いてみたので、上から順に説明していく。
DBサーバでSELECT文を発行するとconsistent gets、すなわち読み取り一貫性を保障するブロック読み込みが発生する。これはローカルDBサーバのバッファキャッシュ上にそのブロックが存在していれば当然そこから読み取られるが、ない場合はcache fusionで他のDBサーバから転送される(gc cr received)。そこにもなければ初めて物理読み込み(physical read bytes等)が発生することとなる。一方、ダイレクトパスリードの場合はバッファキャッシュをバイパスするので、上記の流れはスキップして直接物理読み込みが発生することとなる。
さて、物理読み込みの先は複数のストレージサーバであるが、ここから先がちょっと複雑になる。まず、DBサーバとストレージサーバの間のI/Oを示すのが、cell physical IO interconnect bytesである。これは読み込みだけでなく書き込みも含む、すべてのI/Oのやりとり量を示す統計である。このうち、スマートスキャンにより返却されたI/O量がcell physical IO interconnect bytes returned by smart scanである。これはストレージインデックスやpredicate filtering、column projection等によって削減された後の量である。これらの削減される前のI/O量を示すのがcell physical IO bytes eligible for predicate offloadである。端的には、スマートスキャンがなければDBサーバに返却されたであろうセグメントの全ブロックサイズを示す。従ってスマートスキャンのI/O削減率は以下のように求めることができると考える。
スマートスキャンによるI/O削減率=1- cell physical IO interconnect bytes returned by smart scan / cell physical IO bytes eligible for predicate
これも図にするとイメージし易いだろう。
ちなみに話はそれるが、cell physical IO bytes eligible for predicate offloadが0の場合はそもそもスマートスキャンが発生していない状況であることを示す。逆に上記I/O削減率が0の場合はどう考えればよいのだろうか。実はスマートスキャンの3条件が揃っていてスマートスキャンが発生していても、スマートスキャンができずブロックをそのままDBサーバに返却することがある。これはスマートスキャンは読み取り一貫性を保障しつつ、単一ストレージサーバで処理を独立して完結しなければならないこととに関連している。例えば、読み取り一貫性を保障するためにUNDOブロックを読まなければならない場合、ストレージサーバ(cellsrv)はスマートスキャンをあきらめブロックをそのままDBサーバに返却する。同様のことが行連鎖(複数ブロックにレコードがまたがった状態)した表へのアクセスでも発生する。連鎖した先のブロックはASMによる分散で同じストレージサーバ上にある保障はないためである。これらDBサーバへブロックがそのまま返却された場合、スマートスキャンによるI/O削減率が悪化し、DBサーバから大量のsingle block physical readが発生するということが発生する。以下の図はスマートスキャンの部分の内部の流れを示したものだが、右側2つの流れがスマートスキャンにならず、DBサーバへブロックをそのまま返却する流れである。
フラッシュキャッシュにヒットしたI/O数はcell flash cache read hitsで確認できる。physical read total IO requestsに対してどの程度キャッシュヒットしたかがわかる。なお、このtotalの意味はアプリケーション(SQL)だけでなく、バックアップ、リカバリおよびその他のユーティリティを含むIOを示している。totalのないphysical read IO requestsはアプリケーション(SQL)のみのI/Oを示す。従って、フラッシュキャッシュのヒット率は以下の式で求められると考える。
フラッシュキャッシュのヒット率=cell flash cache read hits / physical read total IO requests
フラッシュキャッシュおよびストレージ索引により削減されたI/O量はphysical read total bytes optimizedで確認できる。うち、ストレージインデックス分はcell physical IO bytes saved by storage indexである。ストレージインデックスはスマートスキャンのときだけ使われるが、フラッシュキャッシュは通常のブロックI/Oでも使われる点に留意したい。
なお、上記多くの内容は以下の参考文献に記載されたものをベースに自らの考察を加えたものなので、正確性は保障できないのであしからず。下図はリファレンスとして使うために上記全体を1枚にまとめてみたものである。
参考文献
- 作者: Martin Bach
- 出版社/メーカー: Apress
- 発売日: 2015/08/13
- メディア: ペーパーバック
2019-02-26 23:47
nice!(0)
コメント(0)



コメント 0