ブロックチェンジトラッキングでDB遅延発生 [アーキテクチャ]
今年のお正月はStay Homeで家でゆっくりするかと思っていたら、夜に電話がかかってきてそのまま出社、翌朝までに何とか収束できたのは良かったものの、とても平和なお正月とは言えなかった。このときは収束に向けてに集中していたので全く考える余裕はなかったが、振り返ってそもそも何故平和なお正月を過ごせなかったのかを考えると、結局一つの結論、つまりlarge_pool_sizeに値を設定せず自動チューニングに任せていたのが敗因だったのではないか、という考えに至った。ということで、今年初の投稿は、年始早々対応したこのトラブルの備忘である。
ブロックチェンジトラッキング(BCT)とは、RMANの高速増分バックアップを取得する際に、どのブロックが前回バックアップから更新されたかを記録する仕組みである。この機能により、RMANは更新されたブロックだけを読み込み、バックアップを取得することができるため、バックアップ時間を短縮するために一般的に使われている機能である。
しかし、バックアップを取得することで、業務のSQL(フォアグラウンドプロセス)に遅延を発生させ得ることがあるのだろうか。alertログに出ていたpublic DBA bufferが不足したメッセージがあることから、少なくともRMANバックアップが引き金となりこのメモリ領域が枯渇し、それによりCKPTに待機が発生し、そこから業務に遅延が波及した可能性はあると考えた。また、状況からDBインスタンス再起動後の初めてのRMANバックアップであったことから、public DBA bufferが不足した原因はDBインスタンス再起動と何等かの関連があるのではないか、という仮説は立てられた。
その後、サポートと解析を進めたところ、少しずつブロックチェンジトラッキングの仕組みが分かってきた。Oracle Ace DirectorのAlexander Gorbachev氏の記事(参考1)の関連部分を要約すると概ね以下のような内容である(原文はBCTファイルのブロック構造を詳細に記載しており、理解が難しいが、より正確に理解する必要があれば読んでみるとよいだろう。ここまで解析できるものなのかと驚きを禁じ得ない)。
---参考[1]の抜粋(日本語訳)
データファイルブロックへの変更はREDOエントリを生成する。より具体的には、REDOチェンジベクターを生成し、それをブロックに適用する。この適用はディスク上のブロックに直接適用される訳ではなく、バッファキャッシュにまずブロックを読み込み、それからブロックの内容に変更を適用する(ダイレクトパスライトはこの限りではない)。バッファキャッシュ上のブロックは「ダーティ」となり、DBWRが非同期にディスクへフラッシュする。
ダーティとなったブロック(チャンク)をBCTファイルへ書き込むのは、CTWRの役目である。サーバプロセスがREDOエントリをログバッファに書き込むのと同時に、SGA上の特別なバッファにどのブロックが変更されたかを記録する。のちにCTWRはこの情報を用いてBCTファイルを更新する。CTWRがBCTファイルを書き込むタイミングはチェックポイントである。CKPTプロセスはCTWRプロセスへシグナルを送り、このバッファの内容をBCTファイルにフラッシュするよう促す。CKPTはCTWRの書き込みを待たず、CTWRがシグナルを受け取ったことを確認したら、後続のデータファイルヘッダと制御ファイルを更新しチェックポイントを完了する。これと並行して、CTWRはBCTファイルへの更新を行う。
RMAN増分バックアップが開始されるとき、RMANのシャドープロセスはBCTファイルを読み、BCTファイルヘッダを更新する(X$KRCCDR経由で確認できるblock 2176情報もあわせて)。次に、RMANはCTWRプロセスにシグナルを送り、新しい(バックアップの)バージョンを作る必要があることを知らせる。CTWRはBCTに新しいバージョンを作成し、新しいエクステントを作り、必要なら古いビットマップをパージする。その後、CTWRはRMANに制御を返す。
これで初めてRMANのシャドープロセスは必要な過去のすべてのビットマップを読み込み、どのチャンクがバックアップに必要なのかを識別できる。最後にメインの処理である、ダーティなチャンクを読み、変更されたブロックをバックアップピースに書き込む処理を行う。
---
上記の「SGA上の特別なバッファ」とは、まさにpublic DBA bufferのことではないかと考えられる。ここには明記されていないが、public DBA bufferとはCTWRがLarge Pool上に確保するバッファであり、public DBA bufferが不足した場合はサイズが自動拡張されるものらしい。私の手元の環境でBCTを有効にしてLarge Poolのメモリを確認すると、CTWR dba bufferが確認できる。
SQL> select * from v$sgastat where POOL ='large pool';
POOL NAME BYTES CON_ID
-------------- -------------------------- ---------- ----------
large pool free memory 745472 0
large pool PX msg pool 491520 1
large pool CTWR dba buffer 880640 1★
large pool krcc extent chunk 2076672 1
AWRのSGA breakdown differnce by Pool and NameDB/Instのセクションに上記メモリサイズが記録されている。今回の事象では、DB再起動によりpublic DBA bufferが初期値になっていたことがAWRから確認できた。
(1)年末年始のメンテナンス作業でDBインスタンスを再起動した。このとき、CTWRが使うパブリックDBAバッファがクリアされ、初期値のサイズになった。このサイズが小さかったのでLarge Poolも小さくなった(large_pool_sizeは指定せず自動調整としていたため)
(2)オンライン業務が開始され、更新のDMLが発行されると、サーバプロセスはREDO(チェンジベクター)を生成するとともに、CTWRへ更新ブロック情報を連携する。CTWRからBCTファイルへの書き込みは非同期なので、CTWRはIOを待つことなくサーバプロセスへACKを返す。CTWRはCKPTからチェックポイントのタイミングで書き込み要求を受け取り、BCTファイルへパブリックDBAバッファの内容をBCTへ書き込む
(3)RMANバックアップが開始される。このとき、BCTに新しいバージョンを作成する等の更新が発生するため、パブリックDBAバッファに書き込む(a)。このとき、パブリックDBAバッファが不足したため、CTWRは自動拡張を試みる(b)。拡張中はパブリックDBAバッファは排他ロックを獲得し、サーバプロセスからのパブリックDBAバッファへのアクセスは待たされる(e)
(4)CKPTは定期的にCTWRへ書き込み要求を出すが、自動拡張中はパブリックDBAバッファの排他ロックによりCTWRが要求を返却できず、待たされる(f)
(5)パブリックDBAバッファを拡張するため、Large Pool内に空きメモリを確保しようとする。ここで、Large Poolが不足したため、動的に拡張(GLOW/IMMEDIATE)しようと試みる。具体的にはバッファキャッシュから256MBを減らし(c)、Large Poolに同サイズを追加する(d)。これに要する時間が1分程度かかる
(6)Large Poolの拡張が完了し、パブリックDBAバッファの拡張が完了する。CTWRはパブリックDBAバッファへのロックを解放し、サーバプロセスやCKPTからの書き込み要求を受け付けるようになり、待機が解消する
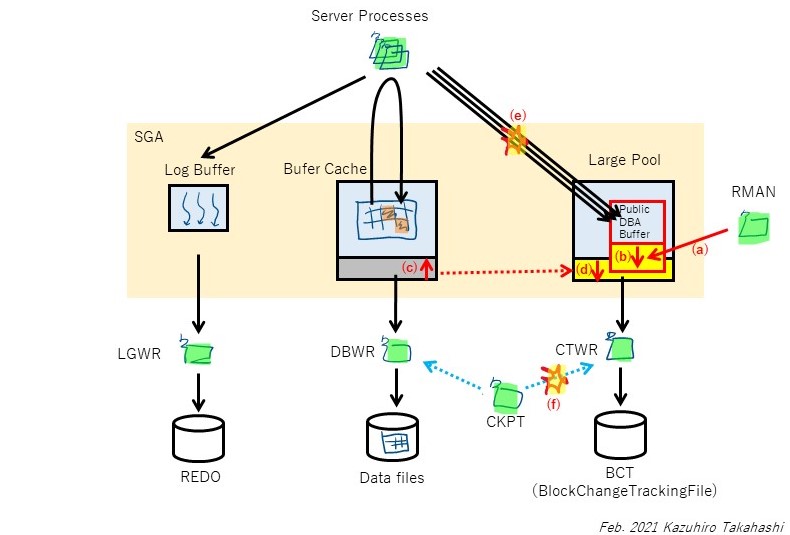
発生した状況からは概ねこのようなメカニズムで今回の事象は発生したのではないかと思っている。もちろん内部の動きは公開されておらず想像込みであるので、これで全容を把握できているとは思っていないし、正しさも保証できない。それでも、パブリックDBAバッファ、およびLarge Poolの動的拡張に時間がかかると、その間、更新を伴うトランザクションおよびCKPTがハングのような状態に陥るという関連性は理解できる。また、自動拡張で時間がかかったのは恐らく(c)(d)の動きとみている。(b)だけであれば、すでに確保されたプール内での拡張なので、目に見える待機が生じるとは思えない。
BCTを使っている場合は、インスタンス再起動後にLarge Poolが小さくならないように、再起動前にAWR等でサイズを確認しておき、large_pool_sizeに設定しておくとよい。large_pool_sizeは最低値を設定するものなので、再起動後にpublic DBA bufferが小さくなったとしても、Large Poolは少なくとも再起動前のサイズを維持しているので、初回RMANバックアップでpublic DBA bufferが自動調整され拡張されたとしても、Large Poolの自動拡張までに及ぶことはなく、遅延の影響は限定的にすることができると考える。large_pool_sizeはオンラインで変更できるし、運用中の現在の値に設定するだけなので、何らリスクはないはずである。
上記に加えpublic DBA bufferのサイズを固定化することも対策として有効である。これは隠しパラメータ(_bct_public_dba_buffer_size)で制御できるため、サポートに確認の上、対処することが望ましい。固定化すると自動調整が効かなくなるデメリットはあるものの、不足した場合はCTWRがBCTへ書き込みが追い付かず、block change tracking buffer space待機が出る可能性があるが、エラーとなるような状況にはならないはずである。AWRからこの待機が顕著に表れるようになれば、このパラメータをチューニングすればよいだけの話である。
また、そもそもインスタンス再起動でpublic DBA bufferのサイズが維持されないのは不具合らしく、すでにパッチ(BUG 30289516 BCT BUNDLED FIXES FOR EASE OF BACK PORTING)が出ているため、12c~19cでこれから対処が可能であれば、要否を含めサポートに確認するとよい。
本記事が、OracleのDBAにとって少しでも平和な正月を迎える一助になれば幸いである。
2021/8/19追記
発生メカニズムの図の(a)の矢印は、RMANから直接Public DBA Bufferを指しているが、これは正確ではない。参考[1]によれば、RMANが直接public DBA bufferへ書き込むのではなく、RMANがCTWRへシグナルを送信し、CTWRがバッファを必要に応じて確保(拡張)する動きとなるので、より正確にはRMAN→CTWR→Public DBA Bufferと記載すべきであった。いずれ図を書き換えたいが、ここに訂正しておく。
1.発生事象
オンラインが一時的(約1分程度)滞留し、これによるAPのタイムアウトエラーが発生。切り分けの結果、DBで遅延が発生していたことが判明した。AWRを見ると、該当時間帯に、顕著なCTWRの待機(enq: CT - CTWR process start/stop)が発生していた。ASHからも、該当時間帯、上記待機でSQLが待たされていることが分かった。また、alert.logにはCKPTが上記待機で1分程度待たされたログと、public dba bufferがあふれた旨のメッセージが記録されていた。2.解析
CTWRの待機(enq: CT - CTWR process start/stop)は、マニュアルに明確な記載はない。しかし、CTWR(Change Tracking Writer Process)はRMANのブロックチェンジトラッキング(BCT)のバックグラウンドプロセスであることから、これに関連した待機であることは想像できる。確かに遅延が発生した時間は、日次のRMANのバックアップ取得ジョブの実行開始時間であったため、RMANバックアップが直接的な引き金として、フォアグラウンドプロセスにブロックチェンジトラッキングの待機が発生したのだろう。ブロックチェンジトラッキング(BCT)とは、RMANの高速増分バックアップを取得する際に、どのブロックが前回バックアップから更新されたかを記録する仕組みである。この機能により、RMANは更新されたブロックだけを読み込み、バックアップを取得することができるため、バックアップ時間を短縮するために一般的に使われている機能である。
しかし、バックアップを取得することで、業務のSQL(フォアグラウンドプロセス)に遅延を発生させ得ることがあるのだろうか。alertログに出ていたpublic DBA bufferが不足したメッセージがあることから、少なくともRMANバックアップが引き金となりこのメモリ領域が枯渇し、それによりCKPTに待機が発生し、そこから業務に遅延が波及した可能性はあると考えた。また、状況からDBインスタンス再起動後の初めてのRMANバックアップであったことから、public DBA bufferが不足した原因はDBインスタンス再起動と何等かの関連があるのではないか、という仮説は立てられた。
その後、サポートと解析を進めたところ、少しずつブロックチェンジトラッキングの仕組みが分かってきた。Oracle Ace DirectorのAlexander Gorbachev氏の記事(参考1)の関連部分を要約すると概ね以下のような内容である(原文はBCTファイルのブロック構造を詳細に記載しており、理解が難しいが、より正確に理解する必要があれば読んでみるとよいだろう。ここまで解析できるものなのかと驚きを禁じ得ない)。
---参考[1]の抜粋(日本語訳)
データファイルブロックへの変更はREDOエントリを生成する。より具体的には、REDOチェンジベクターを生成し、それをブロックに適用する。この適用はディスク上のブロックに直接適用される訳ではなく、バッファキャッシュにまずブロックを読み込み、それからブロックの内容に変更を適用する(ダイレクトパスライトはこの限りではない)。バッファキャッシュ上のブロックは「ダーティ」となり、DBWRが非同期にディスクへフラッシュする。
ダーティとなったブロック(チャンク)をBCTファイルへ書き込むのは、CTWRの役目である。サーバプロセスがREDOエントリをログバッファに書き込むのと同時に、SGA上の特別なバッファにどのブロックが変更されたかを記録する。のちにCTWRはこの情報を用いてBCTファイルを更新する。CTWRがBCTファイルを書き込むタイミングはチェックポイントである。CKPTプロセスはCTWRプロセスへシグナルを送り、このバッファの内容をBCTファイルにフラッシュするよう促す。CKPTはCTWRの書き込みを待たず、CTWRがシグナルを受け取ったことを確認したら、後続のデータファイルヘッダと制御ファイルを更新しチェックポイントを完了する。これと並行して、CTWRはBCTファイルへの更新を行う。
RMAN増分バックアップが開始されるとき、RMANのシャドープロセスはBCTファイルを読み、BCTファイルヘッダを更新する(X$KRCCDR経由で確認できるblock 2176情報もあわせて)。次に、RMANはCTWRプロセスにシグナルを送り、新しい(バックアップの)バージョンを作る必要があることを知らせる。CTWRはBCTに新しいバージョンを作成し、新しいエクステントを作り、必要なら古いビットマップをパージする。その後、CTWRはRMANに制御を返す。
これで初めてRMANのシャドープロセスは必要な過去のすべてのビットマップを読み込み、どのチャンクがバックアップに必要なのかを識別できる。最後にメインの処理である、ダーティなチャンクを読み、変更されたブロックをバックアップピースに書き込む処理を行う。
---
上記の「SGA上の特別なバッファ」とは、まさにpublic DBA bufferのことではないかと考えられる。ここには明記されていないが、public DBA bufferとはCTWRがLarge Pool上に確保するバッファであり、public DBA bufferが不足した場合はサイズが自動拡張されるものらしい。私の手元の環境でBCTを有効にしてLarge Poolのメモリを確認すると、CTWR dba bufferが確認できる。
SQL> select * from v$sgastat where POOL ='large pool';
POOL NAME BYTES CON_ID
-------------- -------------------------- ---------- ----------
large pool free memory 745472 0
large pool PX msg pool 491520 1
large pool CTWR dba buffer 880640 1★
large pool krcc extent chunk 2076672 1
AWRのSGA breakdown differnce by Pool and NameDB/Instのセクションに上記メモリサイズが記録されている。今回の事象では、DB再起動によりpublic DBA bufferが初期値になっていたことがAWRから確認できた。
3.DB遅延発生メカニズム
上記から、本事象の遅延発生メカニズムは以下のようなものと考えられる。(1)年末年始のメンテナンス作業でDBインスタンスを再起動した。このとき、CTWRが使うパブリックDBAバッファがクリアされ、初期値のサイズになった。このサイズが小さかったのでLarge Poolも小さくなった(large_pool_sizeは指定せず自動調整としていたため)
(2)オンライン業務が開始され、更新のDMLが発行されると、サーバプロセスはREDO(チェンジベクター)を生成するとともに、CTWRへ更新ブロック情報を連携する。CTWRからBCTファイルへの書き込みは非同期なので、CTWRはIOを待つことなくサーバプロセスへACKを返す。CTWRはCKPTからチェックポイントのタイミングで書き込み要求を受け取り、BCTファイルへパブリックDBAバッファの内容をBCTへ書き込む
(3)RMANバックアップが開始される。このとき、BCTに新しいバージョンを作成する等の更新が発生するため、パブリックDBAバッファに書き込む(a)。このとき、パブリックDBAバッファが不足したため、CTWRは自動拡張を試みる(b)。拡張中はパブリックDBAバッファは排他ロックを獲得し、サーバプロセスからのパブリックDBAバッファへのアクセスは待たされる(e)
(4)CKPTは定期的にCTWRへ書き込み要求を出すが、自動拡張中はパブリックDBAバッファの排他ロックによりCTWRが要求を返却できず、待たされる(f)
(5)パブリックDBAバッファを拡張するため、Large Pool内に空きメモリを確保しようとする。ここで、Large Poolが不足したため、動的に拡張(GLOW/IMMEDIATE)しようと試みる。具体的にはバッファキャッシュから256MBを減らし(c)、Large Poolに同サイズを追加する(d)。これに要する時間が1分程度かかる
(6)Large Poolの拡張が完了し、パブリックDBAバッファの拡張が完了する。CTWRはパブリックDBAバッファへのロックを解放し、サーバプロセスやCKPTからの書き込み要求を受け付けるようになり、待機が解消する
発生した状況からは概ねこのようなメカニズムで今回の事象は発生したのではないかと思っている。もちろん内部の動きは公開されておらず想像込みであるので、これで全容を把握できているとは思っていないし、正しさも保証できない。それでも、パブリックDBAバッファ、およびLarge Poolの動的拡張に時間がかかると、その間、更新を伴うトランザクションおよびCKPTがハングのような状態に陥るという関連性は理解できる。また、自動拡張で時間がかかったのは恐らく(c)(d)の動きとみている。(b)だけであれば、すでに確保されたプール内での拡張なので、目に見える待機が生じるとは思えない。
4.教訓
RMANでBCTを使っていても、オンライン処理と重ならなければ、1分程度の待機は気づくことないかもしれない。本事象はクリティカルなオンライン処理において、BCTを使っており、large_pool_sizeを設定していないシステムに限定されるだろう。言うまでもなく、バックアップでRMANを使っていなければ、BCTを使う必要はない。ストレージのスナップショット機能等を使ってバックアップをしているなら関係ない。BCTを使っている場合は、インスタンス再起動後にLarge Poolが小さくならないように、再起動前にAWR等でサイズを確認しておき、large_pool_sizeに設定しておくとよい。large_pool_sizeは最低値を設定するものなので、再起動後にpublic DBA bufferが小さくなったとしても、Large Poolは少なくとも再起動前のサイズを維持しているので、初回RMANバックアップでpublic DBA bufferが自動調整され拡張されたとしても、Large Poolの自動拡張までに及ぶことはなく、遅延の影響は限定的にすることができると考える。large_pool_sizeはオンラインで変更できるし、運用中の現在の値に設定するだけなので、何らリスクはないはずである。
上記に加えpublic DBA bufferのサイズを固定化することも対策として有効である。これは隠しパラメータ(_bct_public_dba_buffer_size)で制御できるため、サポートに確認の上、対処することが望ましい。固定化すると自動調整が効かなくなるデメリットはあるものの、不足した場合はCTWRがBCTへ書き込みが追い付かず、block change tracking buffer space待機が出る可能性があるが、エラーとなるような状況にはならないはずである。AWRからこの待機が顕著に表れるようになれば、このパラメータをチューニングすればよいだけの話である。
また、そもそもインスタンス再起動でpublic DBA bufferのサイズが維持されないのは不具合らしく、すでにパッチ(BUG 30289516 BCT BUNDLED FIXES FOR EASE OF BACK PORTING)が出ているため、12c~19cでこれから対処が可能であれば、要否を含めサポートに確認するとよい。
本記事が、OracleのDBAにとって少しでも平和な正月を迎える一助になれば幸いである。
◆参考文献
[1]ORACLE 10G BLOCK CHANGE TRACKING INSIDE OUT (Doc ID 1528510.1)2021/8/19追記
発生メカニズムの図の(a)の矢印は、RMANから直接Public DBA Bufferを指しているが、これは正確ではない。参考[1]によれば、RMANが直接public DBA bufferへ書き込むのではなく、RMANがCTWRへシグナルを送信し、CTWRがバッファを必要に応じて確保(拡張)する動きとなるので、より正確にはRMAN→CTWR→Public DBA Bufferと記載すべきであった。いずれ図を書き換えたいが、ここに訂正しておく。
2021-02-04 07:26


