12cR2のローカルUNDOがローカルになりきれない疑惑 [アーキテクチャ]
12cR2の新機能であるローカルUNDOであるが、どうやらローカルになりきっていない疑惑がある。
業務AP実行中にORA-1555が発生したため、v$undostatsでUNDOの生成量を確認したところ、どう考えてもPDBのローカルUNDO表領域の20%にも満たない量しかUNDO_RETENTION間に生成されていない。通常、tuned_undo_retentionにより、UNDO表領域が85%程度を超えると、UNDO_RETENTIONが短く自動調整され、UNEXPIREDのものもEXPIREされてUNDO表領域あふれが発生しないように調整される。そのため、UNDO生成量がUNDO表領域のサイズに対して大きくなるとORA-1555が発生しやすくなるのは理解できる。しかし、今回は20%に満たないのはおかしい。
調べているうちに気がついたのは、CDB$ROOTのUNDO表領域のサイズに影響されたのではないか、という仮説である。CDB$ROOTのUNDO表領域は特に業務APを動かす訳ではないため、PDBより小さめに設定していた。このサイズに対し、上記UNDO生成量を計算すると、ちょうど85%程度になり、つじつまが合う。おそらく、PDBのtuned_undo_retentionの動作ロジックは、CDBのUNDOのサイズを見ているままになっている可能性がある。
MOSを見ると、機知の不具合として、CDB$ROOTのUNDO表領域のAUTOEXTENDのON・OFFが、PDBのローカルUNDOのtuned_undo_retentionの挙動に影響を与えるというものがあった。少し事象は異なるが、CDBのUNDOの設定がPDBのローカルUNDOに影響を与えてしまう、という点では似ている。
業務AP実行中にORA-1555が発生したため、v$undostatsでUNDOの生成量を確認したところ、どう考えてもPDBのローカルUNDO表領域の20%にも満たない量しかUNDO_RETENTION間に生成されていない。通常、tuned_undo_retentionにより、UNDO表領域が85%程度を超えると、UNDO_RETENTIONが短く自動調整され、UNEXPIREDのものもEXPIREされてUNDO表領域あふれが発生しないように調整される。そのため、UNDO生成量がUNDO表領域のサイズに対して大きくなるとORA-1555が発生しやすくなるのは理解できる。しかし、今回は20%に満たないのはおかしい。
調べているうちに気がついたのは、CDB$ROOTのUNDO表領域のサイズに影響されたのではないか、という仮説である。CDB$ROOTのUNDO表領域は特に業務APを動かす訳ではないため、PDBより小さめに設定していた。このサイズに対し、上記UNDO生成量を計算すると、ちょうど85%程度になり、つじつまが合う。おそらく、PDBのtuned_undo_retentionの動作ロジックは、CDBのUNDOのサイズを見ているままになっている可能性がある。
MOSを見ると、機知の不具合として、CDB$ROOTのUNDO表領域のAUTOEXTENDのON・OFFが、PDBのローカルUNDOのtuned_undo_retentionの挙動に影響を与えるというものがあった。少し事象は異なるが、CDBのUNDOの設定がPDBのローカルUNDOに影響を与えてしまう、という点では似ている。
バグ 27543971 : INCORRECT V$UNDOSTAT.TUNED_UNDORETENTION VALUE IN LOCAL UNDO MODE
結局、CDB$ROOTのUNDO表領域のサイズを、PDBのUNDO表領域のサイズと同じにすることで、ORA-1555の発生は回避することができた。不具合として認められればそのうちパッチ等が提供されるかもしれないが、それまでは暫定の回避策としてCDB$ROOTのサイズをうまく調整して誤魔化すという対応が必要そうである。
2018/11/15追記
サポートとのやりとりの結果、本事象の根本原因は上記不具合と判明。パッチは当面出ないらしい(かなり大きな修正が必要なため来年の19cでも見送られ、20cになる模様)。
以上今さらsort_area_sizeについて考えさせられる [オプティマイザ]
先日12.2でソートの実行計画がおかしいという話を聞いて調べてみたときのこと。前のシステム(11.1)ではメモリソートをする実行計画だったのに、12.2ではなぜかソート列に張られている主キーの索引をフルスキャンしテーブルアクセスする実行計画になっていた。SQLはこんなイメージ。
select * from emp where hiredate=to_date('20181001','YYYYMMDD') order by empno;
※主キーemp_pkはempnoに張られている状況
前者の実行計画は表のマルチブロックリード(hiredateで絞り込み)+結果セットのメモリソートなので高速、後者は索引のマルチブロックリード(全件)+表シングルブロックリード(hiredateで絞込み)ということで、後者の方がかなり遅かった。
/*+ FULL(emp) */ ヒント句をつければ確かに速くなったのだが、問題はなぜ12.2のオプティマイザは後者の実行計画を選択したか、という点であった。なお、前提としては、表の統計はなし(NULL統計でロック)、テーブルに格納するデータは同じ(レコード数も同じ)である。
そこで10053トレースを取得してみて調べてみた。10053トレースはオプティマイザのコスト計算のトレースであり、複数ある実行計画のコストをどう計算し、最終的な実行計画を導いたかがわかる。ここから、12.2のオプティマイザはソートのコストを極めて高く見積もっていることがわかった。それは、メモリソートに収まるサイズが1MBとなっており、ソートスピルのためにtemp表領域にI/Oが発生するコストとなっていたからだった。なお、11.1ではpga_aggregate_target(PAT)を使わず、sort_area_sizeを明示的により大きく(32MB)設定していたため、メモリソートに収まるため、コストが低く見積もられていた。
PATはセッション毎の最大ソート領域は自動チューニングのため、個別セッションのソート領域を通常意識する必要はないと思っていた。実際、セッション毎の最大ソートサイズは_smm_max_sizeで決定し、これはお概ねPATのサイズに比例して大きくなる。しかし、オプティマイザのソートコスト計算での前提となるメモリサイズはセッション毎の最小ソートサイズ(_smm_min_size)であり、どうやらこの最大値は1MBであるらしい。つまり、どれだけPATを大きくしても、オプティマイザのコスト計算上はsort_area_size=1MB相当となってしまう。最大ソートサイズまでPGAは利用できるのに、コスト計算上はこれが考慮されず、必然的にソートコストが高めに計算される、という訳だ。
結局、_smm_min_sizeを前システムのsort_area_sizeの値に設定し、オプティマイザのコスト計算を従来と同様にする対処をすることとした。いまどき新規で作る際PATを使わない、という選択はあまりしないと思うが、もしupgradeなどでPATを使い始める際には、実行計画を安定させる上でこの点の考慮が有用かもしれない。
なお、このソート周りのオプティマイザのコスト計算を理解する上で非常に有用だったのが、Jonathan Lewis氏のCost-Based Oracle Fundamentalsである。これ以上、オラクルのコストについて熱く(厚く)書かれた書籍を私は知らない。残念ながら12cの話は含まれていないが、それでもなお、基本的な考え方は変わっておらず、オプティマイザに関しては私のバイブル的な本である。
")
select * from emp where hiredate=to_date('20181001','YYYYMMDD') order by empno;
※主キーemp_pkはempnoに張られている状況
前者の実行計画は表のマルチブロックリード(hiredateで絞り込み)+結果セットのメモリソートなので高速、後者は索引のマルチブロックリード(全件)+表シングルブロックリード(hiredateで絞込み)ということで、後者の方がかなり遅かった。
/*+ FULL(emp) */ ヒント句をつければ確かに速くなったのだが、問題はなぜ12.2のオプティマイザは後者の実行計画を選択したか、という点であった。なお、前提としては、表の統計はなし(NULL統計でロック)、テーブルに格納するデータは同じ(レコード数も同じ)である。
そこで10053トレースを取得してみて調べてみた。10053トレースはオプティマイザのコスト計算のトレースであり、複数ある実行計画のコストをどう計算し、最終的な実行計画を導いたかがわかる。ここから、12.2のオプティマイザはソートのコストを極めて高く見積もっていることがわかった。それは、メモリソートに収まるサイズが1MBとなっており、ソートスピルのためにtemp表領域にI/Oが発生するコストとなっていたからだった。なお、11.1ではpga_aggregate_target(PAT)を使わず、sort_area_sizeを明示的により大きく(32MB)設定していたため、メモリソートに収まるため、コストが低く見積もられていた。
PATはセッション毎の最大ソート領域は自動チューニングのため、個別セッションのソート領域を通常意識する必要はないと思っていた。実際、セッション毎の最大ソートサイズは_smm_max_sizeで決定し、これはお概ねPATのサイズに比例して大きくなる。しかし、オプティマイザのソートコスト計算での前提となるメモリサイズはセッション毎の最小ソートサイズ(_smm_min_size)であり、どうやらこの最大値は1MBであるらしい。つまり、どれだけPATを大きくしても、オプティマイザのコスト計算上はsort_area_size=1MB相当となってしまう。最大ソートサイズまでPGAは利用できるのに、コスト計算上はこれが考慮されず、必然的にソートコストが高めに計算される、という訳だ。
結局、_smm_min_sizeを前システムのsort_area_sizeの値に設定し、オプティマイザのコスト計算を従来と同様にする対処をすることとした。いまどき新規で作る際PATを使わない、という選択はあまりしないと思うが、もしupgradeなどでPATを使い始める際には、実行計画を安定させる上でこの点の考慮が有用かもしれない。
なお、このソート周りのオプティマイザのコスト計算を理解する上で非常に有用だったのが、Jonathan Lewis氏のCost-Based Oracle Fundamentalsである。これ以上、オラクルのコストについて熱く(厚く)書かれた書籍を私は知らない。残念ながら12cの話は含まれていないが、それでもなお、基本的な考え方は変わっておらず、オプティマイザに関しては私のバイブル的な本である。
Cost-Based Oracle Fundamentals (Expert's Voice in Oracle)
- 作者: Jonathan Lewis
- 出版社/メーカー: Apress
- 発売日: 2007/03/15
- メディア: ペーパーバック
トランケートについて知っておくべきこと [SQL・DDL]
#変更履歴:2019/5/3 図を追加
トランケートをご存知だろうか。こんな単純な問いかけに対し自信をもって「はい」と答えられるDBAは以外と少ないかもしれないと最近思い始めている。
まずはじめに基本的な事項をおさらいしておこう。トランケートはテーブル(パーティション)内のレコードを削除するDDLである。HWM(ハイウォーターマーク)を下げることにより、テーブル内のレコードを削除するため、一般的にDELETEより高速であり、ログ量も小さくて済む。また、DDLであるため、ロールバックはできない。
例)truncate table scott.emp
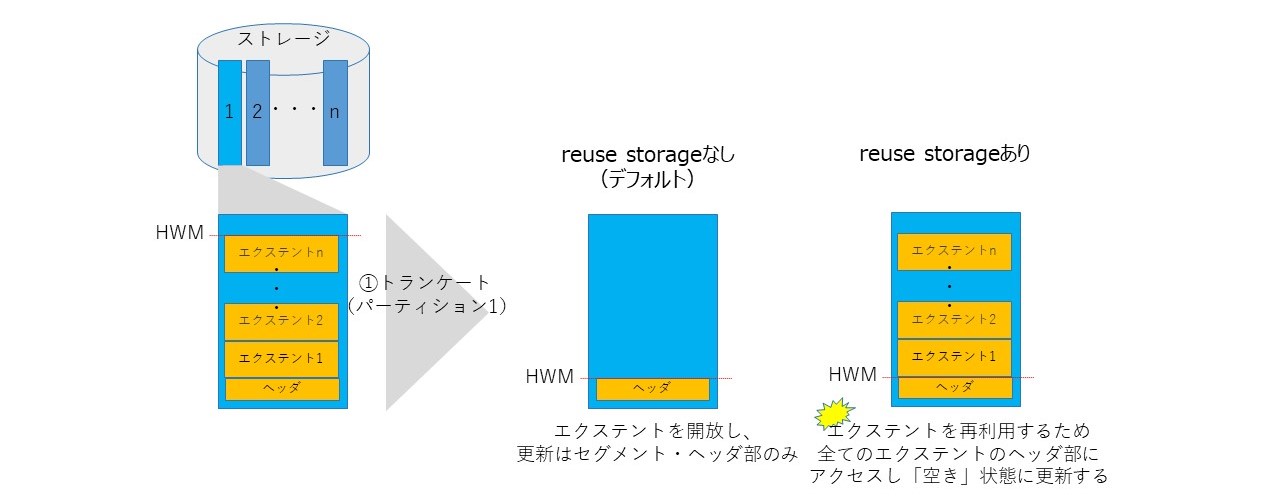
トランケートはreuse storageオプションがある。これをつけると、確保済みエクステントを開放せず、保持しながらトランケートを実行することができる(下記例)。デフォルトはdrop storageである。
例)truncate table scott.emp reuse storage
パーティションレベルのトランケートは上記reuse storageオプションの他、(パーティション)索引のリビルド・パラレル等のオプションが指定できる。
例)alter table scott.emp truncate partition part01 (..オプション)
いかがだろうか。これだけでも、トランケート処理は様々な機能が実装されていることがわかると思う。さて、このトランケートの挙動について知っておいた方がよいと思うことを以下に5点述べる。11gR2の挙動をベースに記載しているが、バージョンが違っても基本的なアーキテクチャは大きく変わっていないので12cでも参考になるだろう。
その1.共有カーソルが無効化されハードパースが走る
トランケートを実行すると、その対象セグメントのDATA_OBJECT_ID(セグメントのオブジェクト番号)が変更される。これにより、当該オブジェクトにかかわるSQLの共有カーソルがINVALIDになる(RACでは全ノードで関連するSQLがINVALIDとなる)。この結果、次回SQL実行時にハードパースが走ることになる。なお、パーティション表の場合は、仮に1つのパーティションをトランケートしても、すべてのパーティション、およびテーブルのDATA_OBJECT_IDが変更される点である。このため、参照していないと思ってトランケートすると、ハードパースによりオンラインのSQLに思わぬ性能劣化を発生させてしまうということが起こりうる。
なお、ALTER TABALEやALTER INDEXといったDDLでも同様の挙動が発生する。どのような処理で共有カーソルがINVALIDになるかについては、「共有カーソルがINVALIDになる処理(KROWN:101305)(ドキュメントID 1731739.1)が参考になるだろう。

その2.テーブルレベルのロックがかかる
特定のパーティションのトランケートでも、共有カーソルを無効化するため、テーブルレベルでlibrary cache lockを排他モードで獲得する。このとき、ハードパースが必要なSQLはlibrary cache lockを共有モードで獲得する必要があるため、待ちが発生する。この理由から、異なるパーティションのトランケート処理を並列実行したとしても、処理は必ずシリアライズされてしまう。
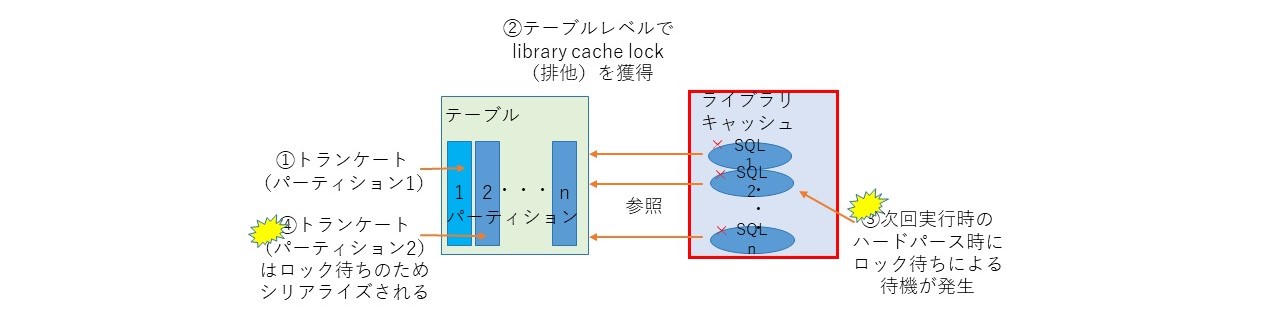
その3.ミニ・チェックポイントが走る
トランケートを実行すると、内部でミニ・チェックポイント(バッファキャッシュ上のダーティブロックをストレージに書き出す処理)が走る。このため、バッファキャッシュ上のダーティブロックが多いと、トランケート処理時間が長くかかることがある。この事象が発生するときは、enq: RO fast object reuseの待機イベントが顕著に表れる。
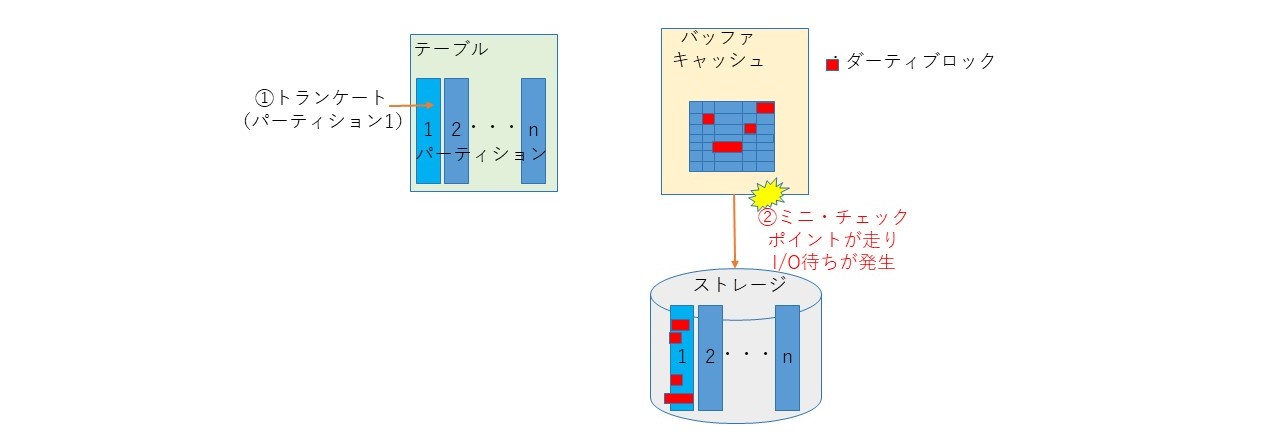
その4.reuse storageを付けると遅くなることがある
reuse storageはエクステントの開放はしないが、空ブロックであるというマークをする必要があるため、エクステント数とブロック数に応じてトランケート時間が伸びる傾向がある。INSERT時のエクステント確保の性能とのトレードオフに考慮が必要だが、筆者のExadataでの経験上では、reuse storageなしの方が速い。
その5.グローバル索引のメンテナンスが必要
パーティションをトランケートすると、グローバル索引はunusable(再構築までアクセス不可)状態となる。しかし、update global indexesオプションを付与すると、グローバル索引の自動更新が可能である。
例)alter table scott.emp truncate partition part01 update global indexes
一見便利であるが、この処理の内部的にはフルテーブルスキャンが走る(ドキュメントID 2177233.1)ため、テーブル全体の件数に応じて時間がかかる。運用当初は少ないパーティションでレコード数が小さくから顕在化しにくいが、経年で大きくなると非常に時間がかかるようになることがありうるため注意が必要である。このフルスキャンはparallel句を付けることでパラレル度を上げることができるが、おそらくこれが唯一のチューニング方法だろう。
上記5点を踏まえると、トランケート関連のトラブルを避ける上では以下に注意すればよいだろう。
・業務繁忙時間帯にトランケートを実行することは極力避ける
・reuse storageはむやみに使わない(トランケートだけなら使わないほうが性能は良い)
・グローバル索引は極力作らない(作るならメンテナンスの方式を考えておくこと)
・トランケートの発行回数は極力減らす。例えば、パーティション単位でなく、テーブル単位でまとめてトランケートする(下図)

トランケートについて理解を深めるきっかけになれば幸いである。
トランケートをご存知だろうか。こんな単純な問いかけに対し自信をもって「はい」と答えられるDBAは以外と少ないかもしれないと最近思い始めている。
まずはじめに基本的な事項をおさらいしておこう。トランケートはテーブル(パーティション)内のレコードを削除するDDLである。HWM(ハイウォーターマーク)を下げることにより、テーブル内のレコードを削除するため、一般的にDELETEより高速であり、ログ量も小さくて済む。また、DDLであるため、ロールバックはできない。
例)truncate table scott.emp
トランケートはreuse storageオプションがある。これをつけると、確保済みエクステントを開放せず、保持しながらトランケートを実行することができる(下記例)。デフォルトはdrop storageである。
例)truncate table scott.emp reuse storage
パーティションレベルのトランケートは上記reuse storageオプションの他、(パーティション)索引のリビルド・パラレル等のオプションが指定できる。
例)alter table scott.emp truncate partition part01 (..オプション)
いかがだろうか。これだけでも、トランケート処理は様々な機能が実装されていることがわかると思う。さて、このトランケートの挙動について知っておいた方がよいと思うことを以下に5点述べる。11gR2の挙動をベースに記載しているが、バージョンが違っても基本的なアーキテクチャは大きく変わっていないので12cでも参考になるだろう。
その1.共有カーソルが無効化されハードパースが走る
トランケートを実行すると、その対象セグメントのDATA_OBJECT_ID(セグメントのオブジェクト番号)が変更される。これにより、当該オブジェクトにかかわるSQLの共有カーソルがINVALIDになる(RACでは全ノードで関連するSQLがINVALIDとなる)。この結果、次回SQL実行時にハードパースが走ることになる。なお、パーティション表の場合は、仮に1つのパーティションをトランケートしても、すべてのパーティション、およびテーブルのDATA_OBJECT_IDが変更される点である。このため、参照していないと思ってトランケートすると、ハードパースによりオンラインのSQLに思わぬ性能劣化を発生させてしまうということが起こりうる。
なお、ALTER TABALEやALTER INDEXといったDDLでも同様の挙動が発生する。どのような処理で共有カーソルがINVALIDになるかについては、「共有カーソルがINVALIDになる処理(KROWN:101305)(ドキュメントID 1731739.1)が参考になるだろう。
その2.テーブルレベルのロックがかかる
特定のパーティションのトランケートでも、共有カーソルを無効化するため、テーブルレベルでlibrary cache lockを排他モードで獲得する。このとき、ハードパースが必要なSQLはlibrary cache lockを共有モードで獲得する必要があるため、待ちが発生する。この理由から、異なるパーティションのトランケート処理を並列実行したとしても、処理は必ずシリアライズされてしまう。
その3.ミニ・チェックポイントが走る
トランケートを実行すると、内部でミニ・チェックポイント(バッファキャッシュ上のダーティブロックをストレージに書き出す処理)が走る。このため、バッファキャッシュ上のダーティブロックが多いと、トランケート処理時間が長くかかることがある。この事象が発生するときは、enq: RO fast object reuseの待機イベントが顕著に表れる。
その4.reuse storageを付けると遅くなることがある
reuse storageはエクステントの開放はしないが、空ブロックであるというマークをする必要があるため、エクステント数とブロック数に応じてトランケート時間が伸びる傾向がある。INSERT時のエクステント確保の性能とのトレードオフに考慮が必要だが、筆者のExadataでの経験上では、reuse storageなしの方が速い。
その5.グローバル索引のメンテナンスが必要
パーティションをトランケートすると、グローバル索引はunusable(再構築までアクセス不可)状態となる。しかし、update global indexesオプションを付与すると、グローバル索引の自動更新が可能である。
例)alter table scott.emp truncate partition part01 update global indexes
一見便利であるが、この処理の内部的にはフルテーブルスキャンが走る(ドキュメントID 2177233.1)ため、テーブル全体の件数に応じて時間がかかる。運用当初は少ないパーティションでレコード数が小さくから顕在化しにくいが、経年で大きくなると非常に時間がかかるようになることがありうるため注意が必要である。このフルスキャンはparallel句を付けることでパラレル度を上げることができるが、おそらくこれが唯一のチューニング方法だろう。
上記5点を踏まえると、トランケート関連のトラブルを避ける上では以下に注意すればよいだろう。
・業務繁忙時間帯にトランケートを実行することは極力避ける
・reuse storageはむやみに使わない(トランケートだけなら使わないほうが性能は良い)
・グローバル索引は極力作らない(作るならメンテナンスの方式を考えておくこと)
・トランケートの発行回数は極力減らす。例えば、パーティション単位でなく、テーブル単位でまとめてトランケートする(下図)
トランケートについて理解を深めるきっかけになれば幸いである。
direct path readについて思うこと [オプティマイザ]
Exadataを使い始めたのは2014年、X4-2からだ。当初はOracleに毛が生えたもの程度にしか思っていなかった。しかし、使い込んでいくうちに、DB層の下のストレージサーバ層に独自の機能が作りこまれていることがだんだんわかってきた。これを知ったのはExpert Oracle Exadata[1]という一冊の本に出会ってからである。
この本は英語でかなり厚く、お値段もそれなりにするので敷居が高いが、Exadataの内部動作をここまで紐解いてわかりやすく説明している点は他に類を見ない。もっと早くこの本に出会っていれば、よりExadataを有効活用し、トラブル対応も違った形でできたのではという忸怩たる思いがある。
さて、この本を読み進める中でわかったのは、Exadataを使う(使いこなす)上での一つのポイントが、direct path readである、ということである。ご存知の通りdirect path readとはバッファキャッシュをバイパスしてストレージ上のブロックをサーバプロセスのPGAに読み込むことで、フルスキャンなどのマルチブロックを高速に実現する方法である。もともとパラレルクエリのメカニズムであったが、11gからシリアルクエリでもdirect path readが使えるようになった。
なぜdirect path readがExadataにおいて重要なのか?スマートスキャンなど、ストレージからDBサーバのブロック転送量を減らす仕組み(具体的にはpredicate filteringやcolumn projection、storage indexなどを指す)が有効になるのは、すべてdirect path readであることが前提となる。Exadataのスマートスキャンが有効となるのは、以下の3つの条件がすべて揃わなければならない。
1.セグメントのフルスキャンであること
2.direct path readであること
3.オブジェクトはExadataに格納されていること
上記のうち、1は実行計画を確認すれば簡単にわかるだろう。3も環境により自明であることが多い。しかし、2については一番わかりにくい。なぜなら、direct path readの発動条件が公開されておらず、また、Oracleのバージョンによってロジックが異なるためである。少なくとも、条件としては、バッファキャッシュのサイズとオブジェクトのサイズ、バッファキャッシュに乗っているオブジェクトのブロック数が関係しているといわれる。
例えば、私の利用している環境(Exadata X7-2/Oracle12.2.0.1)では、セグメントサイズがバッファキャッシュの約2%を超えるとdirect path readが発生し始めることを確認している。このため、Oracle社の技術資料の中にはスマートスキャンを使うためにはパラレルヒントを入れることを促す資料があるほどである。嘘ではないが若干荒っぽいチューニング手法であると個人的には思う。
direct path readが発生していることは実行計画からは判別ができない。このため、一般的にはSQLトレース(10046トレース)を確認することが確実だろう。あるいは、セッション統計(v$sesstat, v$mystat)の統計の変化を確認することも有効だろう。いずれにしても本番環境で確認するのはいささかハードルが高い。
direct path readのデメリットといえば、バッファキャッシュに乗らないため、毎回ストレージに負荷がかかる点である。特にアクセス頻度が高いSQLではストレージサーバ側の負荷に注意が必要だろう。
例えば、ある表に対するHASH結合をプロセス多重で実行するようなケースを考えてみよう。HASH結合ではフルスキャンが走るため、上記条件を満たせばdirect path readとなり、Exadataではスマートスキャンによるストレージサーバへのオフロード機能の恩恵を受けられる。しかし、これを多重で実行すると、バッファキャッシュに乗らないため、ストレージサーバへ負荷が集中することとなる。このような場合は、あえてdirect path readを実行されないような考慮が必要かもしれない(具体的にはセッションレベルで_serinal_direct_readをNEVERにするなど)。
また、経年でセグメントサイズが増加するようなテーブルでは、DBサーバ再起動後からdirect path readに切り替わってしまうということが起きうる。これは、バッファキャッシュ上にセグメントブロックがある程度乗っているうちは、direct path readは発生しないという特性による。運用中にセグメントが閾値(具体的には_small_table_thresholdのブロック数から導出される閾値)を超え、インスタンス再起動によりバッファキャッシュがクリアされると途端にdirect path readになってしまい、ストレージサーバの負荷が高くなるという事象が起こりうる。性能が向上すればよいが、ストレージサーバの負荷によっては性能劣化を引き起こす可能性があるため、このような特性は理解しておく必要がある。
参考文献:[1]Expert Oracle Exadata

この本は英語でかなり厚く、お値段もそれなりにするので敷居が高いが、Exadataの内部動作をここまで紐解いてわかりやすく説明している点は他に類を見ない。もっと早くこの本に出会っていれば、よりExadataを有効活用し、トラブル対応も違った形でできたのではという忸怩たる思いがある。
さて、この本を読み進める中でわかったのは、Exadataを使う(使いこなす)上での一つのポイントが、direct path readである、ということである。ご存知の通りdirect path readとはバッファキャッシュをバイパスしてストレージ上のブロックをサーバプロセスのPGAに読み込むことで、フルスキャンなどのマルチブロックを高速に実現する方法である。もともとパラレルクエリのメカニズムであったが、11gからシリアルクエリでもdirect path readが使えるようになった。
なぜdirect path readがExadataにおいて重要なのか?スマートスキャンなど、ストレージからDBサーバのブロック転送量を減らす仕組み(具体的にはpredicate filteringやcolumn projection、storage indexなどを指す)が有効になるのは、すべてdirect path readであることが前提となる。Exadataのスマートスキャンが有効となるのは、以下の3つの条件がすべて揃わなければならない。
1.セグメントのフルスキャンであること
2.direct path readであること
3.オブジェクトはExadataに格納されていること
上記のうち、1は実行計画を確認すれば簡単にわかるだろう。3も環境により自明であることが多い。しかし、2については一番わかりにくい。なぜなら、direct path readの発動条件が公開されておらず、また、Oracleのバージョンによってロジックが異なるためである。少なくとも、条件としては、バッファキャッシュのサイズとオブジェクトのサイズ、バッファキャッシュに乗っているオブジェクトのブロック数が関係しているといわれる。
例えば、私の利用している環境(Exadata X7-2/Oracle12.2.0.1)では、セグメントサイズがバッファキャッシュの約2%を超えるとdirect path readが発生し始めることを確認している。このため、Oracle社の技術資料の中にはスマートスキャンを使うためにはパラレルヒントを入れることを促す資料があるほどである。嘘ではないが若干荒っぽいチューニング手法であると個人的には思う。
direct path readが発生していることは実行計画からは判別ができない。このため、一般的にはSQLトレース(10046トレース)を確認することが確実だろう。あるいは、セッション統計(v$sesstat, v$mystat)の統計の変化を確認することも有効だろう。いずれにしても本番環境で確認するのはいささかハードルが高い。
direct path readのデメリットといえば、バッファキャッシュに乗らないため、毎回ストレージに負荷がかかる点である。特にアクセス頻度が高いSQLではストレージサーバ側の負荷に注意が必要だろう。
例えば、ある表に対するHASH結合をプロセス多重で実行するようなケースを考えてみよう。HASH結合ではフルスキャンが走るため、上記条件を満たせばdirect path readとなり、Exadataではスマートスキャンによるストレージサーバへのオフロード機能の恩恵を受けられる。しかし、これを多重で実行すると、バッファキャッシュに乗らないため、ストレージサーバへ負荷が集中することとなる。このような場合は、あえてdirect path readを実行されないような考慮が必要かもしれない(具体的にはセッションレベルで_serinal_direct_readをNEVERにするなど)。
また、経年でセグメントサイズが増加するようなテーブルでは、DBサーバ再起動後からdirect path readに切り替わってしまうということが起きうる。これは、バッファキャッシュ上にセグメントブロックがある程度乗っているうちは、direct path readは発生しないという特性による。運用中にセグメントが閾値(具体的には_small_table_thresholdのブロック数から導出される閾値)を超え、インスタンス再起動によりバッファキャッシュがクリアされると途端にdirect path readになってしまい、ストレージサーバの負荷が高くなるという事象が起こりうる。性能が向上すればよいが、ストレージサーバの負荷によっては性能劣化を引き起こす可能性があるため、このような特性は理解しておく必要がある。
参考文献:[1]Expert Oracle Exadata
- 作者: Martin Bach
- 出版社/メーカー: Apress
- 発売日: 2015/08/28
- メディア: ペーパーバック


