Things you should know before truncate tables and partitions [SQL・DDL]
"Do you know truncate?" You will defenitely answer Yes, but how much? Here, what I would like to describe is about truncate. Even though truncate is such a simple command, what behind the scene is not not easy to explain. Throughout the past several years of maintaining a large Exadata, I would like to describe some of the lessons learned, in terms of how it may influence performance. Advanced DBAs probably know most of the things described here, but still, I thought it might be useful to write it down as a reference.
Let's start from the basics.
1. Basics of truncate
Truncate is a DDL that deletes all records in a table or a patition. To do that, it will lower the HWM (high water mark), therefore general, it is much faster than DELETE and generate less redo log. Truncate cannot rollback since it is a DDL. When you truncate a scott.emp table, you will do the following:
SQL> truncate table scott.emp;
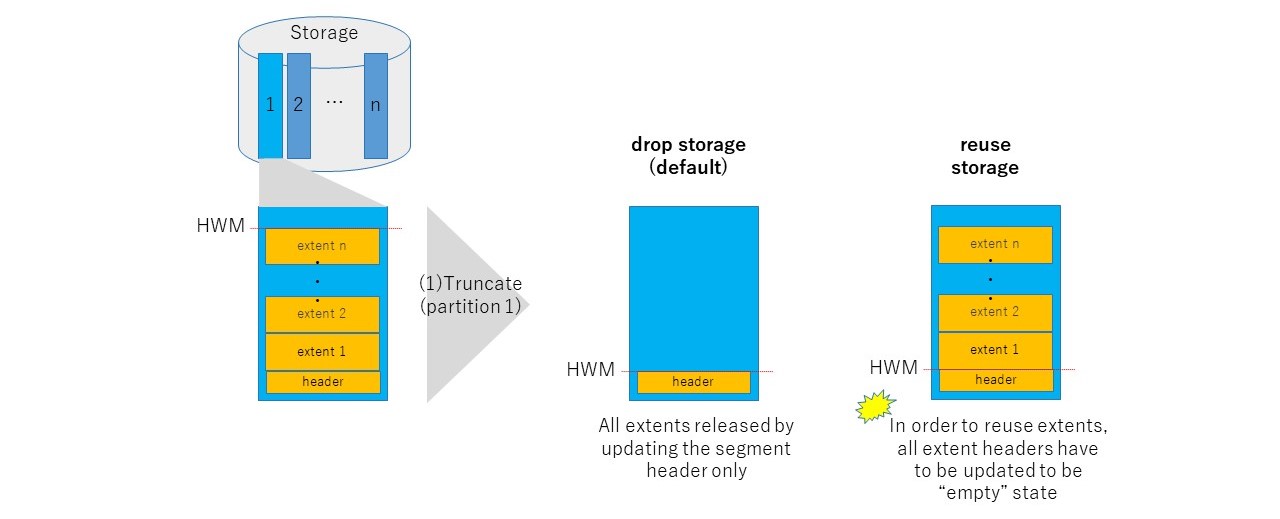
Truncate frees all allocated extents belonging to the table by default ("drop storage" option). With "reuse storage" option, truncate keeps allocated extents and make the table empty.
SQL> truncate table scott.emp reuse storage;
Concerning a partition level truncate, you can specify options not only to rebuild global indexes with paralellism, as well as reuse storage option described above.
SQL> alter table scott.emp truncate partition part01 reuse storage update global indexes parallel 4;
It is not my intention to describe all the possilbe options of truncate here, but to give impression how such a simple DDL can do various things.
2. Five things you should know about truncate
I will describe five things that it's better to understand about truncate. Even though the behavirour is based on 11gR2, I believe most of the things will be still available on 12c as well.
2.1. Shared cursor is invalidated, then pard parsed
Upon executing truncate on a table, the table's DATA_OBJECT_ID (a object number of the segment) will be changed. Because of this, all shared cursors that relate to the table will be invalidated. When using RAC, this propagets to the other instances. As a result, all such SQLs will be hard parsed on next executions, not only the instance the truncate is executed, but other instances as well.
When you truncate a partition, all the partitions' DATA_OBJECT_ID will be changed, even you truncate a single partition out of thouthand. Therefore, if you truncate a old partition in range partitioned table as a maintenance task during online, there is a chance that online SQL that access to the table will be slow down, even if the query doesn't access the partition truncated.
By the way, the same will happen on DDLs such as ALTER TABLE or ALTER INDEX. To confirm what kind of DDLs make shared cursors INVALID, refer to DocumentID 1731739.1* (* this is written in Japanese, though).
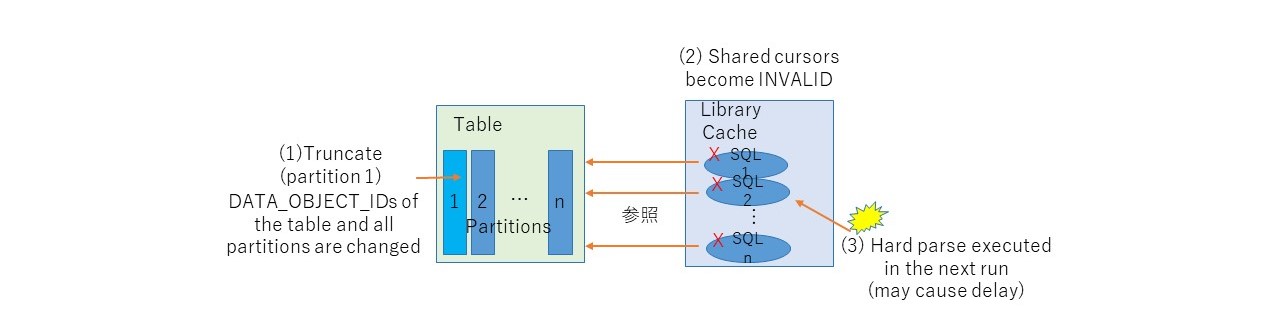
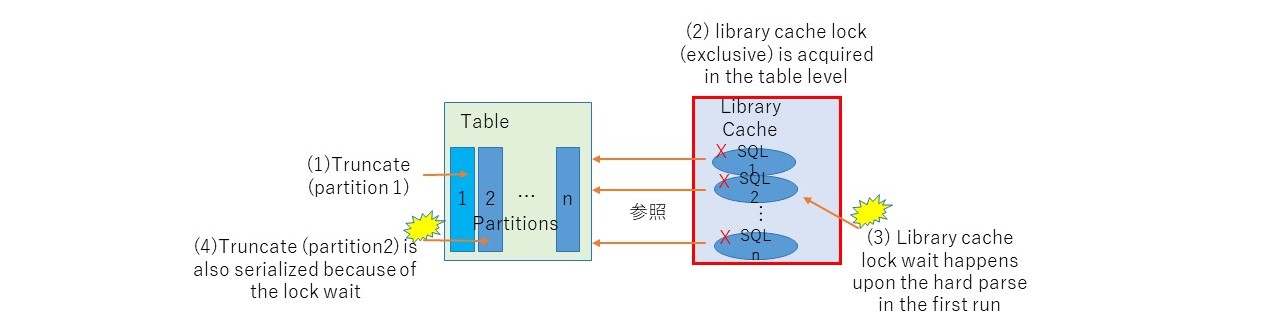
2.2. Table is locked (not a specific partition)
Truncating a partition not only makes related SQLs invalidated, but also acquire "library cache lock" to the table ( not the partition) with exclusive mode. At this point, all SQLs that need to be hard parsed will be blocked because they also try to acquire "library cache lock" with shared mode. It is also worth while noted that if you try to truncate different partitions concurrently, it will be always serialized.
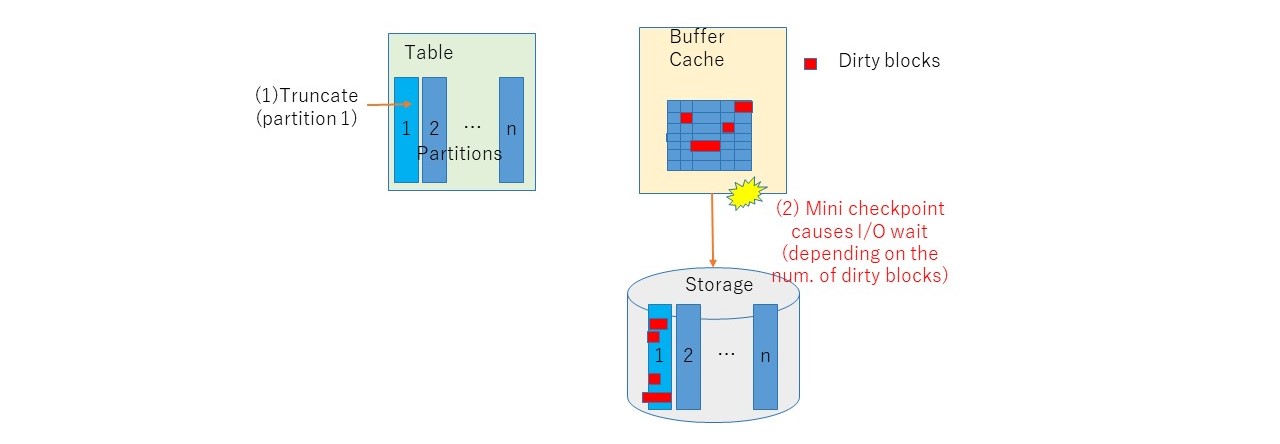
2.3. Mini-checkpoint executed
Truncate will execute mini-checkpoint. Mini-checkpoint will flush dirty blocks of the table in the buffer cache to its storage. While ordinaly checkpoint will deal with all dirty blocks, mini-checkpoint will only deal with relevant blocks of the table. Therefore, truncate may take a long time when the number of dirty blocks is large. This behaviour will be observed as excessive amount of a wait event "enq: RO fast object reuse".
2.4. reuse storage option may be slower
You may think truncate with reuse storage option faster than drop storage option because it doesn't have to free the extents, especially for large segments. However, it may not be true. With reuse storage option, truncate needs to mark all extents as free and takes time depending on the segment size. In fact, in my experience, trunate with resuse storage option was slower than drop storage option (10-20 sec vs 3 sec) in Exadata X4, while INSERT performance hardly have any difference. Since I think this may not be always true depending on its environment, it is a good idea to verify before deciding which is better on your environment.
2.5. Global index maintanance required and may take time
When a partition is truncated, the global index (if exists) will become unusable state, which means it will not be accessible until rebuild. It is possible to update such global indexes automatically with "update global index" option.
SQL> alter table scott.emp truncate partition part01 update global indexes
Even though it looks useful, it is internally a full table scan happening as described in DocID 2177233.1, which might take a long time to complete. It is often not a problem for the first time because the number of rows is small, but it might be a serious problem in the future gradually depending on the increase of the data. In such a situation, parallel option will be useful to reduce the time to rebuild global indexes. In fact, as far as I understand, this will be the only tuning option.
3. Conclusion
Considering the above, some tips for using truncate are the following:
- reduce the number of truncate executed to minimize lock and hard parse. For example, instead of truncate every partition, truncate a table once.
- avoid to execute truncate during business hours when online transaction is accessing the table frequently.
- avoid to use "reuse storage" option if you have severe performance requirement for the truncate. INSERT performance may not get benefit of reuse of extents.
- avoid to create global indexes. If it is really necessary, think about the maintenance in terms of performance.

I hope this document helps to understand truncate better.
Let's start from the basics.
1. Basics of truncate
Truncate is a DDL that deletes all records in a table or a patition. To do that, it will lower the HWM (high water mark), therefore general, it is much faster than DELETE and generate less redo log. Truncate cannot rollback since it is a DDL. When you truncate a scott.emp table, you will do the following:
SQL> truncate table scott.emp;
Truncate frees all allocated extents belonging to the table by default ("drop storage" option). With "reuse storage" option, truncate keeps allocated extents and make the table empty.
SQL> truncate table scott.emp reuse storage;
Concerning a partition level truncate, you can specify options not only to rebuild global indexes with paralellism, as well as reuse storage option described above.
SQL> alter table scott.emp truncate partition part01 reuse storage update global indexes parallel 4;
It is not my intention to describe all the possilbe options of truncate here, but to give impression how such a simple DDL can do various things.
2. Five things you should know about truncate
I will describe five things that it's better to understand about truncate. Even though the behavirour is based on 11gR2, I believe most of the things will be still available on 12c as well.
2.1. Shared cursor is invalidated, then pard parsed
Upon executing truncate on a table, the table's DATA_OBJECT_ID (a object number of the segment) will be changed. Because of this, all shared cursors that relate to the table will be invalidated. When using RAC, this propagets to the other instances. As a result, all such SQLs will be hard parsed on next executions, not only the instance the truncate is executed, but other instances as well.
When you truncate a partition, all the partitions' DATA_OBJECT_ID will be changed, even you truncate a single partition out of thouthand. Therefore, if you truncate a old partition in range partitioned table as a maintenance task during online, there is a chance that online SQL that access to the table will be slow down, even if the query doesn't access the partition truncated.
By the way, the same will happen on DDLs such as ALTER TABLE or ALTER INDEX. To confirm what kind of DDLs make shared cursors INVALID, refer to DocumentID 1731739.1* (* this is written in Japanese, though).
2.2. Table is locked (not a specific partition)
Truncating a partition not only makes related SQLs invalidated, but also acquire "library cache lock" to the table ( not the partition) with exclusive mode. At this point, all SQLs that need to be hard parsed will be blocked because they also try to acquire "library cache lock" with shared mode. It is also worth while noted that if you try to truncate different partitions concurrently, it will be always serialized.
2.3. Mini-checkpoint executed
Truncate will execute mini-checkpoint. Mini-checkpoint will flush dirty blocks of the table in the buffer cache to its storage. While ordinaly checkpoint will deal with all dirty blocks, mini-checkpoint will only deal with relevant blocks of the table. Therefore, truncate may take a long time when the number of dirty blocks is large. This behaviour will be observed as excessive amount of a wait event "enq: RO fast object reuse".
2.4. reuse storage option may be slower
You may think truncate with reuse storage option faster than drop storage option because it doesn't have to free the extents, especially for large segments. However, it may not be true. With reuse storage option, truncate needs to mark all extents as free and takes time depending on the segment size. In fact, in my experience, trunate with resuse storage option was slower than drop storage option (10-20 sec vs 3 sec) in Exadata X4, while INSERT performance hardly have any difference. Since I think this may not be always true depending on its environment, it is a good idea to verify before deciding which is better on your environment.
2.5. Global index maintanance required and may take time
When a partition is truncated, the global index (if exists) will become unusable state, which means it will not be accessible until rebuild. It is possible to update such global indexes automatically with "update global index" option.
SQL> alter table scott.emp truncate partition part01 update global indexes
Even though it looks useful, it is internally a full table scan happening as described in DocID 2177233.1, which might take a long time to complete. It is often not a problem for the first time because the number of rows is small, but it might be a serious problem in the future gradually depending on the increase of the data. In such a situation, parallel option will be useful to reduce the time to rebuild global indexes. In fact, as far as I understand, this will be the only tuning option.
3. Conclusion
Considering the above, some tips for using truncate are the following:
- reduce the number of truncate executed to minimize lock and hard parse. For example, instead of truncate every partition, truncate a table once.
- avoid to execute truncate during business hours when online transaction is accessing the table frequently.
- avoid to use "reuse storage" option if you have severe performance requirement for the truncate. INSERT performance may not get benefit of reuse of extents.
- avoid to create global indexes. If it is really necessary, think about the maintenance in terms of performance.
I hope this document helps to understand truncate better.
REDOとUNDOその2 [アーキテクチャ]
前回に引き続きREDOとUNDOについて、別の書籍(参考文献 2章のRedo and Undo)の内容をメモしておく。こちらは敬愛するJonathan Lewis氏の書籍である。
---
私の意見では、Oracleの唯一最も重要な機能は、バージョン6で登場した「チェンジベクター」である。これは、データブロックへの変更を表現するメカニズムであり、REDOとUNDOの核心である。この技術により、データが安全に確保され、読み込みと書き込みの競合を最小限に抑え、さらにインスタンスリカバリやメディアリカバリ、スタンバイ技術(データガード)、フラッシュバックメカニズム、変更データのキャプチャやストリームが可能となっているのである。...
基本的なデータの変更
Oracleデータベースの不思議なところは同じデータを2回記録するところである。1つはデータファイルに存在するデータであり、これは概ね最新になっているがup-to-dateの状態はメモリ上に存在しやがてディスクへ反映されるのを待っている。もう1つはREDOログファイル内に一連の説明として存在しており、これによりどのようにデータの内容をゼロから再生成するかがわかる。
アプローチ
あるデータ項目を更新するような命令を発行したとき、Oracleはデータを変更するためにすぐにデータファイル(あるいはメモリ上のデータブロック)を探して変更するようなアプローチはとらない。Oracleは以下のような手順を踏んで変更を行う。
1. データブロックを変更するためのREDOチェンジベクターを生成する
2. UNDO表領域のUNDOブロックにインサートするためのUNDOレコードを生成する
3. UNDOブロックを変更するためのREDOチェンジベクターを生成する
4. データブロックを変更する
実際のところ正確なステップ順や技術的な詳細は、Oracleのバージョンやトランザクションの特性、トランザクションのどこまで実行したか、命令が実行される前の様々なデータベースブロックの状態、トランザクションの始めの変更を見るのかどうか、等に依存する。
例
はじめに簡単なデータを変更する例から始める。1つの行をOLTPトランザクションの中で更新するときの動きである。実際、一般的な状況において、ステップ順は上記で述べたものとは異なる。実際は3-1-2-4の順となり、2つのREDOチェンジベクターはまとめて1つのREDO変更レコードとなりログバッファにコピーされる。この処理は、UNDOブロックとデータブロックが(この順に)変更される前に行われる。つまり、もう少し正確な順にすると、以下のようになる。
1. UNDOブロックをインサートするためのREDOチェンジベクターを生成する
2. データブロックを変更するためのREDOチェンジベクターを生成する
3. 上記2つのREDOチェンジベクターを1つのREDOレコードとして、ログバッファに書き込む
4. UNDOレコードをUNDOブロックにインサートする
5. データブロックを変更する
振り返り
データブロックを更新するとき、OracleはUNDOレコードをUNDOブロックにインサートし、変更をどのように戻すかを記録する。しかし、データベース上のブロックに対するすべての変更について、Oracleはどのようにその変更を行うかを説明するREDOチェンジベクターを生成する。そして、そのベクターの生成は実際の変更の前である。歴史的に、UNDOチェンジベクターを先に生成し、その後、進めるチェンジベクターを生成する。したがって、以下のイベントが順に発生する。
1. UNDOレコードのチェンジベクターを生成する
2. データブロックのチェンジベクターを生成する
3. チェンジベクターをまとめて、REDOレコードをREDOログ(バッファ)に書き込む
4. UNDOレコードをUNDOブロックに書き込む
5. データブロックに変更を行う
始めの2つのステップは必ずしも正確と信じる明確な理由はない。いままでに説明したことやダンプの結果から、この順になることは示すことはできない。...
まとめ
データファイルにおいて、すべての変更はUNDOレコードの生成とマッチする(これもデータファイルへの変更の一部であるが)。同時にOracleはREDOログに、どのようにわれわれの変更を行うか、どのようにそれ自身の変更を行うかを記録する。
1点留意すべきは、データは「その場(in place)」で変更できるため、特定の1レコードに対して無限の更新を行うことができると思うかもしれない。しかし、無限のUNDOレコードを記録することは、UNDO表領域のデータファイルの増加なしでできないし、REDOログに無限に変更を記録することは、新たなログファイルを追加せずに行うことはできない。事を単純化するために、今の時点ではこの無限更新の問題は先送りにして、必要なだけUNDOとREDOレコードを記録できると考えよう。
---
Oracleコミュニティでたびたび投稿を見ることがあるが、いつも内容の思慮深さと謙虚さに関心させられる。これ程簡潔に、Oracleのアーキテクチャの本質を解説した本は他に見たことがない。もう一歩、Oracleの深い世界を体験させてくれる一冊である。
◆参考文献
")
---
私の意見では、Oracleの唯一最も重要な機能は、バージョン6で登場した「チェンジベクター」である。これは、データブロックへの変更を表現するメカニズムであり、REDOとUNDOの核心である。この技術により、データが安全に確保され、読み込みと書き込みの競合を最小限に抑え、さらにインスタンスリカバリやメディアリカバリ、スタンバイ技術(データガード)、フラッシュバックメカニズム、変更データのキャプチャやストリームが可能となっているのである。...
基本的なデータの変更
Oracleデータベースの不思議なところは同じデータを2回記録するところである。1つはデータファイルに存在するデータであり、これは概ね最新になっているがup-to-dateの状態はメモリ上に存在しやがてディスクへ反映されるのを待っている。もう1つはREDOログファイル内に一連の説明として存在しており、これによりどのようにデータの内容をゼロから再生成するかがわかる。
アプローチ
あるデータ項目を更新するような命令を発行したとき、Oracleはデータを変更するためにすぐにデータファイル(あるいはメモリ上のデータブロック)を探して変更するようなアプローチはとらない。Oracleは以下のような手順を踏んで変更を行う。
1. データブロックを変更するためのREDOチェンジベクターを生成する
2. UNDO表領域のUNDOブロックにインサートするためのUNDOレコードを生成する
3. UNDOブロックを変更するためのREDOチェンジベクターを生成する
4. データブロックを変更する
実際のところ正確なステップ順や技術的な詳細は、Oracleのバージョンやトランザクションの特性、トランザクションのどこまで実行したか、命令が実行される前の様々なデータベースブロックの状態、トランザクションの始めの変更を見るのかどうか、等に依存する。
例
はじめに簡単なデータを変更する例から始める。1つの行をOLTPトランザクションの中で更新するときの動きである。実際、一般的な状況において、ステップ順は上記で述べたものとは異なる。実際は3-1-2-4の順となり、2つのREDOチェンジベクターはまとめて1つのREDO変更レコードとなりログバッファにコピーされる。この処理は、UNDOブロックとデータブロックが(この順に)変更される前に行われる。つまり、もう少し正確な順にすると、以下のようになる。
1. UNDOブロックをインサートするためのREDOチェンジベクターを生成する
2. データブロックを変更するためのREDOチェンジベクターを生成する
3. 上記2つのREDOチェンジベクターを1つのREDOレコードとして、ログバッファに書き込む
4. UNDOレコードをUNDOブロックにインサートする
5. データブロックを変更する
振り返り
データブロックを更新するとき、OracleはUNDOレコードをUNDOブロックにインサートし、変更をどのように戻すかを記録する。しかし、データベース上のブロックに対するすべての変更について、Oracleはどのようにその変更を行うかを説明するREDOチェンジベクターを生成する。そして、そのベクターの生成は実際の変更の前である。歴史的に、UNDOチェンジベクターを先に生成し、その後、進めるチェンジベクターを生成する。したがって、以下のイベントが順に発生する。
1. UNDOレコードのチェンジベクターを生成する
2. データブロックのチェンジベクターを生成する
3. チェンジベクターをまとめて、REDOレコードをREDOログ(バッファ)に書き込む
4. UNDOレコードをUNDOブロックに書き込む
5. データブロックに変更を行う
始めの2つのステップは必ずしも正確と信じる明確な理由はない。いままでに説明したことやダンプの結果から、この順になることは示すことはできない。...
まとめ
データファイルにおいて、すべての変更はUNDOレコードの生成とマッチする(これもデータファイルへの変更の一部であるが)。同時にOracleはREDOログに、どのようにわれわれの変更を行うか、どのようにそれ自身の変更を行うかを記録する。
1点留意すべきは、データは「その場(in place)」で変更できるため、特定の1レコードに対して無限の更新を行うことができると思うかもしれない。しかし、無限のUNDOレコードを記録することは、UNDO表領域のデータファイルの増加なしでできないし、REDOログに無限に変更を記録することは、新たなログファイルを追加せずに行うことはできない。事を単純化するために、今の時点ではこの無限更新の問題は先送りにして、必要なだけUNDOとREDOレコードを記録できると考えよう。
---
Oracleコミュニティでたびたび投稿を見ることがあるが、いつも内容の思慮深さと謙虚さに関心させられる。これ程簡潔に、Oracleのアーキテクチャの本質を解説した本は他に見たことがない。もう一歩、Oracleの深い世界を体験させてくれる一冊である。
◆参考文献
Oracle Core: Essential Internals for DBAs and Developers (Expert's Voice in Databases)
- 作者: Jonathan Lewis
- 出版社/メーカー: Apress
- 発売日: 2011/12/06
- メディア: ペーパーバック
REDOとUNDO [アーキテクチャ]
最近読んでいる書籍(下記の参考文献9章 REDOとUNDO)に、Oracleデータベースの最も重要なREDOとUNDOについて詳しく記載されていたので、備忘まで要点をメモしておく。原文の英語を読みやすさを優先して意図を汲んで要約しているので、原文の正確性は損なわれているかもしれないが、そのあたりはご容赦頂きたい。
---
REDOとはトランザクションを記録したログであり、不慮の障害の場合にトランザクションを再生するためのものである。UNDOはその逆に、トランザクションをロールバックするためのものである。REDOはオンラインREDOログファイル(アーカイブログファイル)、UNDOはUNDO表領域(内のセグメント)に記録される。
REDOとUNDOはどのように動作するのか
以下のようなテーブルと索引があるとする。
create table t(x int, y int);
create index ti on t(x);
ここで、以下のトランザクションを例に考えてみる。
(1) insert into t (x,y) values (1,1);
(2) update t set x= x+1 where x=1;
(3) delete from t where x=2;
まず(1)のINSERTのケースを考えてみる。INSERT INTO TはREDOとUNDOを生成する。このとき、バッファキャッシュ上には、テーブル、索引、UNDOセグメントのブロックがディスクから読み込まれ更新される。そして、それらブロックへの更新情報はログとしてREDOログバッファに記録される。
さて、COMMIT前にDBに何らかの障害が発生しサーバがダウンしたとしよう。このとき、なんら問題はない。SGA上のREDOログバッファ、バッファキャッシュ上のダーティブロックはディスクに記録されず、DBサーバ復旧時は、あたかもトランザクションが実行される前の状態のままとなる。
次に、バッファキャッシュが一杯になったケースを考えよう。このとき、バッファキャッシュの空きを作るため、DBWnはダーティブロックをディスクに書き込む必要があるが、その前にLGWRはREDOログバッファをこれらのブロックに関連するトランザクションログをフラッシュさせる。これにより、UNDOのログがディスクに記録されるため、DB障害時に未コミットトランザクションによる変更ブロックをロールバックすることが可能となる。なお、REDOログバッファは、(1)3秒毎、(2)ログバッファの1/3に達したとき、または1MB以上に達したとき、(3)COMMITまたはROLLBACKが発行されたとき、にフラッシュされるため、通常ほとんどのREDOログバッファはフラッシュされた状態になっているはずである。つまり、未コミットの変更ブロックがバッファキャッシュ上にあり、その未コミットの変更のREDOがディスク上にある状態というのは、通常よく発生するありふれた状態なのである。
次に(2)のUPDATEのケース。UPDATEはINSERTと同様の動きをする。ただし、UNDO量はUPDATE前のイメージを保持するため大きくなる。テーブル、索引、UNDOセグメントブロックがバッファキャッシュ上にあり、ログバッファにUPDATEの更新ログが記録された状態(INSERTの更新ログはREDOログファイルに記録)である。
もしこの状態でDBがクラッシュしたらどうなるか。DBのインスタンス起動時にOracleはREDOログファイルを読み込み、このトランザクションログを見つけ、INSERTにより生成された更新ログ(UNDOブロックを含む)からロールフォワードする。UPDATEのREDOログはバッファ上にのみ存在していたので失われるが、COMMITしていないので問題ない。Oracleはクラッシュリカバリの過程でINSERTがCOMMITされていないことを検出し、(記録されたREDOログにより生成された)バッファキャッシュ上のUNDOセグメントの情報(テーブルと索引の更新前情報)からROLLBACKする。これにより、すべては元の状態となる。ディスク上のブロックはINSERTの更新が反映されているかもしれないが、更新が取り消されたバッファキャッシュがやがてフラッシュされるタイミングで反映されるので問題ない。このようにクラッシュリカバリでは2つのフェーズで行われる。始めにロールフォワードにより障害直前の状態に復旧し、その後に未COMMITトランザクションすべてをロールバックする。これによりデータファイルが整合性が取れた状態となる訳である。
ではクラッシュではなく、トランザクションをロールバックしたらどうなるか。OracleはこのトランザクションのUNDOをバッファキャッシュ上またはディスク上のUNDOセグメントを見つけ、バッファキャッシュ上の表のデータと索引にUNDO情報を適用する。もしバッファキャッシュになければディスクから読み込みUNDOを適用する。これらのブロックは後にフラッシュされディスクに反映される。ここで1点明確にしておくと、ロールバックするプロセスにおいて、REDOログは一切関与しないということである。REDOログが使われるのはリカバリとアーカイブのためだけである。ARCnがオンラインREDOログファイルを読み、LGWRが別のREDOログファイルに書き込みを行うだけに十分なデバイスがある限り、ログファイルの競合は発生しない。このようにREDOとUNDOが別となっていないデータベースでは、ログファイルをトランザクションログとして扱っており、ロールバック時にログを読み込むと同時に、ログライターが同じログに書き込みを行うため競合が発生してしまう。OracleはREDOログをシーケンシャルに書き込む。そして、書き込み中には他から読み込みが発生することはない、というアーキテクチャとなっている。
(3)のDELETEのケースでは、DELETEの結果UNDOが生成され、ブロックが更新され、REDOがログバッファに書き込まれる。UPDATEの動きと同じである。
COMMITを行うとどうなるか。OracleはREDOログバッファをディスクへフラッシュする。変更されたブロックはバッファキャッシュ上にあるが、一部はディスクにフラッシュされた状態かもしれない。しかし、重要なのは、このトランザクションを再実行するためのREDOログはディスクに書き込まれており、永続的な状態になっていることである。データファイルの個々のブロックはまだトランザクション実行前の状態かもしれないが、問題はない。障害時にはREDOログファイルにより最新のブロックの状態にすることができるからである。UNDO情報はUNDOセグメントが上書きされ再利用されるまで保持され、読み取り一貫性のために利用される。
COMMITは何をするのか?
COMMITは通常トランザクションの更新量に依存せず非常に高速に完了する。COMMITの処理時間はトランザクションのサイズにかかわらずフラットなのである。これはCOMMITの処理が本質的に少ないからである。なぜなら、COMMITに必要な以下のような処理はほとんど完了している。
・SGA上にUNDOブロックの生成
・SGA上に更新データブロックの生成
・上記2つのREDOをSGA上に生成
・上記3つのサイズと処理時間に応じてデータがディスクへフラッシュされる
・すべてのロックが獲得される
その上で、COMMITすると、残作業として以下が行われる
・このトランザクションのSCNが生成される
・LGWRがログバッファ上の(残りの)ログエントリをディスクに書き込む
・V$LOCK上のロックレコードをリリースする
・バッファキャッシュ上のダーティブロックに対してブロッククリーンアウト(ブロックヘッダ上のロック関連情報の削除)を行う
上記を見ればわかるように、COMMITの処理はほとんどすることがない。一番長い処理はI/O処理を含む、LGWRにより行われる処理である。しかしそれにしても、REDOログバッファの内容は繰り返しフラッシュされているので、その量はかなり削減されているはずである。LGWRはバックグラウンドでREDOログバッファの内容を継続的にフラッシュしていく。これによりCOMMITが長い時間待たせることを防いでいる訳である。
ROLLBACKは何をするのか?
ROLLBACKの時間は更新量に依存する。なぜならROLLBACKは実行した処理を取り消さなければならないからだ。COMMITと同様、一連の処理が実行されなければならないが、ROLLBACKが行われる前に、データベースは既に多くの処理を行っている
・UNDOセグメントのレコードをSGA上に生成する
・更新されたデータブロックをSGA上に生成する
・上記2つのREDOログをSGA上に生成する
・上記3つのサイズと処理時間に応じてデータがディスクへフラッシュされる
・すべてのロックが獲得される
ROLLBACKを行うと、以下が実行される
・すべての更新を取り消す。これはUNDOセグメントからデータブロックを読み込み実行した処理を巻き戻し、UNDOエントリを適用済みとマークする。INSERTなら削除、UPDATEならその変更を元に戻す、DELETEなら再度INSERTする
・すべてのロックをリリースする
---
なお、実際は図やサンプルスクリプトでより具体的に説明されているので、理解を深めたい方は一読をお勧めする。このレベルまで詳しく記載された書籍は日本語ではなかなかないので、この章意外についても時間があれば紹介したいと思う。
◆参考文献

---
REDOとはトランザクションを記録したログであり、不慮の障害の場合にトランザクションを再生するためのものである。UNDOはその逆に、トランザクションをロールバックするためのものである。REDOはオンラインREDOログファイル(アーカイブログファイル)、UNDOはUNDO表領域(内のセグメント)に記録される。
REDOとUNDOはどのように動作するのか
以下のようなテーブルと索引があるとする。
create table t(x int, y int);
create index ti on t(x);
ここで、以下のトランザクションを例に考えてみる。
(1) insert into t (x,y) values (1,1);
(2) update t set x= x+1 where x=1;
(3) delete from t where x=2;
まず(1)のINSERTのケースを考えてみる。INSERT INTO TはREDOとUNDOを生成する。このとき、バッファキャッシュ上には、テーブル、索引、UNDOセグメントのブロックがディスクから読み込まれ更新される。そして、それらブロックへの更新情報はログとしてREDOログバッファに記録される。
さて、COMMIT前にDBに何らかの障害が発生しサーバがダウンしたとしよう。このとき、なんら問題はない。SGA上のREDOログバッファ、バッファキャッシュ上のダーティブロックはディスクに記録されず、DBサーバ復旧時は、あたかもトランザクションが実行される前の状態のままとなる。
次に、バッファキャッシュが一杯になったケースを考えよう。このとき、バッファキャッシュの空きを作るため、DBWnはダーティブロックをディスクに書き込む必要があるが、その前にLGWRはREDOログバッファをこれらのブロックに関連するトランザクションログをフラッシュさせる。これにより、UNDOのログがディスクに記録されるため、DB障害時に未コミットトランザクションによる変更ブロックをロールバックすることが可能となる。なお、REDOログバッファは、(1)3秒毎、(2)ログバッファの1/3に達したとき、または1MB以上に達したとき、(3)COMMITまたはROLLBACKが発行されたとき、にフラッシュされるため、通常ほとんどのREDOログバッファはフラッシュされた状態になっているはずである。つまり、未コミットの変更ブロックがバッファキャッシュ上にあり、その未コミットの変更のREDOがディスク上にある状態というのは、通常よく発生するありふれた状態なのである。
次に(2)のUPDATEのケース。UPDATEはINSERTと同様の動きをする。ただし、UNDO量はUPDATE前のイメージを保持するため大きくなる。テーブル、索引、UNDOセグメントブロックがバッファキャッシュ上にあり、ログバッファにUPDATEの更新ログが記録された状態(INSERTの更新ログはREDOログファイルに記録)である。
もしこの状態でDBがクラッシュしたらどうなるか。DBのインスタンス起動時にOracleはREDOログファイルを読み込み、このトランザクションログを見つけ、INSERTにより生成された更新ログ(UNDOブロックを含む)からロールフォワードする。UPDATEのREDOログはバッファ上にのみ存在していたので失われるが、COMMITしていないので問題ない。Oracleはクラッシュリカバリの過程でINSERTがCOMMITされていないことを検出し、(記録されたREDOログにより生成された)バッファキャッシュ上のUNDOセグメントの情報(テーブルと索引の更新前情報)からROLLBACKする。これにより、すべては元の状態となる。ディスク上のブロックはINSERTの更新が反映されているかもしれないが、更新が取り消されたバッファキャッシュがやがてフラッシュされるタイミングで反映されるので問題ない。このようにクラッシュリカバリでは2つのフェーズで行われる。始めにロールフォワードにより障害直前の状態に復旧し、その後に未COMMITトランザクションすべてをロールバックする。これによりデータファイルが整合性が取れた状態となる訳である。
ではクラッシュではなく、トランザクションをロールバックしたらどうなるか。OracleはこのトランザクションのUNDOをバッファキャッシュ上またはディスク上のUNDOセグメントを見つけ、バッファキャッシュ上の表のデータと索引にUNDO情報を適用する。もしバッファキャッシュになければディスクから読み込みUNDOを適用する。これらのブロックは後にフラッシュされディスクに反映される。ここで1点明確にしておくと、ロールバックするプロセスにおいて、REDOログは一切関与しないということである。REDOログが使われるのはリカバリとアーカイブのためだけである。ARCnがオンラインREDOログファイルを読み、LGWRが別のREDOログファイルに書き込みを行うだけに十分なデバイスがある限り、ログファイルの競合は発生しない。このようにREDOとUNDOが別となっていないデータベースでは、ログファイルをトランザクションログとして扱っており、ロールバック時にログを読み込むと同時に、ログライターが同じログに書き込みを行うため競合が発生してしまう。OracleはREDOログをシーケンシャルに書き込む。そして、書き込み中には他から読み込みが発生することはない、というアーキテクチャとなっている。
(3)のDELETEのケースでは、DELETEの結果UNDOが生成され、ブロックが更新され、REDOがログバッファに書き込まれる。UPDATEの動きと同じである。
COMMITを行うとどうなるか。OracleはREDOログバッファをディスクへフラッシュする。変更されたブロックはバッファキャッシュ上にあるが、一部はディスクにフラッシュされた状態かもしれない。しかし、重要なのは、このトランザクションを再実行するためのREDOログはディスクに書き込まれており、永続的な状態になっていることである。データファイルの個々のブロックはまだトランザクション実行前の状態かもしれないが、問題はない。障害時にはREDOログファイルにより最新のブロックの状態にすることができるからである。UNDO情報はUNDOセグメントが上書きされ再利用されるまで保持され、読み取り一貫性のために利用される。
COMMITは何をするのか?
COMMITは通常トランザクションの更新量に依存せず非常に高速に完了する。COMMITの処理時間はトランザクションのサイズにかかわらずフラットなのである。これはCOMMITの処理が本質的に少ないからである。なぜなら、COMMITに必要な以下のような処理はほとんど完了している。
・SGA上にUNDOブロックの生成
・SGA上に更新データブロックの生成
・上記2つのREDOをSGA上に生成
・上記3つのサイズと処理時間に応じてデータがディスクへフラッシュされる
・すべてのロックが獲得される
その上で、COMMITすると、残作業として以下が行われる
・このトランザクションのSCNが生成される
・LGWRがログバッファ上の(残りの)ログエントリをディスクに書き込む
・V$LOCK上のロックレコードをリリースする
・バッファキャッシュ上のダーティブロックに対してブロッククリーンアウト(ブロックヘッダ上のロック関連情報の削除)を行う
上記を見ればわかるように、COMMITの処理はほとんどすることがない。一番長い処理はI/O処理を含む、LGWRにより行われる処理である。しかしそれにしても、REDOログバッファの内容は繰り返しフラッシュされているので、その量はかなり削減されているはずである。LGWRはバックグラウンドでREDOログバッファの内容を継続的にフラッシュしていく。これによりCOMMITが長い時間待たせることを防いでいる訳である。
ROLLBACKは何をするのか?
ROLLBACKの時間は更新量に依存する。なぜならROLLBACKは実行した処理を取り消さなければならないからだ。COMMITと同様、一連の処理が実行されなければならないが、ROLLBACKが行われる前に、データベースは既に多くの処理を行っている
・UNDOセグメントのレコードをSGA上に生成する
・更新されたデータブロックをSGA上に生成する
・上記2つのREDOログをSGA上に生成する
・上記3つのサイズと処理時間に応じてデータがディスクへフラッシュされる
・すべてのロックが獲得される
ROLLBACKを行うと、以下が実行される
・すべての更新を取り消す。これはUNDOセグメントからデータブロックを読み込み実行した処理を巻き戻し、UNDOエントリを適用済みとマークする。INSERTなら削除、UPDATEならその変更を元に戻す、DELETEなら再度INSERTする
・すべてのロックをリリースする
---
なお、実際は図やサンプルスクリプトでより具体的に説明されているので、理解を深めたい方は一読をお勧めする。このレベルまで詳しく記載された書籍は日本語ではなかなかないので、この章意外についても時間があれば紹介したいと思う。
◆参考文献
Expert Oracle Database Architecture
- 作者: Thomas Kyte
- 出版社/メーカー: Apress
- 発売日: 2014/11/14
- メディア: ペーパーバック
Exadataと不揮発性メモリ [最新動向]
ストレージサーバにCell RAMキャッシュと呼ばれるキャッシュがある。Cell RAMキャッシュはフラッシュキャッシュの前面に位置し、フラッシュキャッシュよりレイテンシは低く、容量は小さい。そのため、cell single block physical readが上位にくるOLTPのワークロードにおいて、あたかもバッファキャッシュの追加キャッシュがストレージサーバ上にあることにより、オンライン性能向上が期待できる。ストレージサーバソフトウェア18cからの機能であり、デフォルトでは無効化されている(ramCacheModeがautoに設定されている)。
ストレージサーバのRAMキャッシュがデフォルトで無効なのは、なにも新機能なので自信がない訳ではない。これを有効に使うためにはストレージサーバ側のメモリの増設が前提となる。マニュアルを見ると、AWRのBuffer Pool Advisoryから、バッファキャッシュをどの程度増やすとどの程度の物理読み込みが削減できるか確認できるが、これを見てCell側にどの程度のRAMを増設(メモリ拡張キット)するかを決定すればよいと記載されている。
RAMキャッシュの設定方法は簡単だ。cellcliからALTER CELL ramCacheMode=onして、ALTER CELL RESTART SERVICES CELLSRVによりcellsrvプロセスを再起動する。これをすべてのストレージサーバで実行すればよい。これで勝手に空きメモリをRAMキャッシュとして使うようになるそうだ。実際はバックグラウンドでRAMキャッシュは構成されるらしく、作成にはしばらく時間がかかるようだ。この様子はLIST CELL ATTRIBUTES ramCacheMaxSize,ramCacheMode, ramCacheSizeで確認できる。RAMキャッシュサイズの最大を制限することは、ALTER CELL ramCacheMaxSize=1Gのように実行できる。
昨年(2018年)秋のOOWでこの機能を紹介していたが、日本でも新機能として紹介されていた話なので特段目新しいとも思っていなかった。しかし、最近たまたま以下のブログでインテルのOptaneという不揮発性メモリがExadataで活用されようとしている話を知った。この記事は2018/10/22、ちょうどOOWの時期であったが、OOWのセミナではこのメモリの話はしていなかった記憶がある(もちろん自分の英語力にそれほど自信がある訳ではないが)。物理的には従来のDIMMスロットにそのまま刺せるので導入が容易らしい。
Exadata Persistent Memory Accelerator: Partnering with Intel on Optane DC Persistent Memory
インテルのOptaneのサイトを見ると、確かにOracleもこのメモリのベータプログラムに参加しており、ExadataのVice PresidentがExadataへの活用を紹介している。数TB程度のDBであれば、完全にインメモリで処理できるので、超低レイテンシのOLTP(証券取引やIoT)やリアルタイム分析の高速化といったユースケースを意識しているようだ。ちなみに同時期にGoogleもこのメモリを使ってクラウドサーバで7TBのサービスを提供すると発表していた。SAP HANAなどのインメモリDBへの利用も視野に入れているようだ。
Intel Optane DC Persistent Memory Hardware Beta Partners
Intel Optane DC Persistent Memory Partner: Oracle
今後の開発の方向性がどうなるかわからないが、ストレージサーバ上のDIMMスロット(の一部)がこの不揮発性メモリとなり、上記CELL RAMキャッシュにこの不揮発の領域がライトバックとしても使えるようになったら面白いかもしれない。フラッシュキャッシュよいさらに低いレイテンシ、高速に大量の処理が行えるようになるはずだ。また、これにあわせて特に分析用途ではCell側の集合計算などの機能拡充が決定的に重要になり、また処理のボトルネックはCell側のCPUになるかもしれない。
こうなってくると、もうインメモリの流れは止まらないと感じる、今日この頃である。
ストレージサーバのRAMキャッシュがデフォルトで無効なのは、なにも新機能なので自信がない訳ではない。これを有効に使うためにはストレージサーバ側のメモリの増設が前提となる。マニュアルを見ると、AWRのBuffer Pool Advisoryから、バッファキャッシュをどの程度増やすとどの程度の物理読み込みが削減できるか確認できるが、これを見てCell側にどの程度のRAMを増設(メモリ拡張キット)するかを決定すればよいと記載されている。
RAMキャッシュの設定方法は簡単だ。cellcliからALTER CELL ramCacheMode=onして、ALTER CELL RESTART SERVICES CELLSRVによりcellsrvプロセスを再起動する。これをすべてのストレージサーバで実行すればよい。これで勝手に空きメモリをRAMキャッシュとして使うようになるそうだ。実際はバックグラウンドでRAMキャッシュは構成されるらしく、作成にはしばらく時間がかかるようだ。この様子はLIST CELL ATTRIBUTES ramCacheMaxSize,ramCacheMode, ramCacheSizeで確認できる。RAMキャッシュサイズの最大を制限することは、ALTER CELL ramCacheMaxSize=1Gのように実行できる。
昨年(2018年)秋のOOWでこの機能を紹介していたが、日本でも新機能として紹介されていた話なので特段目新しいとも思っていなかった。しかし、最近たまたま以下のブログでインテルのOptaneという不揮発性メモリがExadataで活用されようとしている話を知った。この記事は2018/10/22、ちょうどOOWの時期であったが、OOWのセミナではこのメモリの話はしていなかった記憶がある(もちろん自分の英語力にそれほど自信がある訳ではないが)。物理的には従来のDIMMスロットにそのまま刺せるので導入が容易らしい。
Exadata Persistent Memory Accelerator: Partnering with Intel on Optane DC Persistent Memory
インテルのOptaneのサイトを見ると、確かにOracleもこのメモリのベータプログラムに参加しており、ExadataのVice PresidentがExadataへの活用を紹介している。数TB程度のDBであれば、完全にインメモリで処理できるので、超低レイテンシのOLTP(証券取引やIoT)やリアルタイム分析の高速化といったユースケースを意識しているようだ。ちなみに同時期にGoogleもこのメモリを使ってクラウドサーバで7TBのサービスを提供すると発表していた。SAP HANAなどのインメモリDBへの利用も視野に入れているようだ。
Intel Optane DC Persistent Memory Hardware Beta Partners
Intel Optane DC Persistent Memory Partner: Oracle
今後の開発の方向性がどうなるかわからないが、ストレージサーバ上のDIMMスロット(の一部)がこの不揮発性メモリとなり、上記CELL RAMキャッシュにこの不揮発の領域がライトバックとしても使えるようになったら面白いかもしれない。フラッシュキャッシュよいさらに低いレイテンシ、高速に大量の処理が行えるようになるはずだ。また、これにあわせて特に分析用途ではCell側の集合計算などの機能拡充が決定的に重要になり、また処理のボトルネックはCell側のCPUになるかもしれない。
こうなってくると、もうインメモリの流れは止まらないと感じる、今日この頃である。
Exadataのメモリ使用率の考え方 [アーキテクチャ]
性能試験等でExadataのDBサーバのメモリの利用状況をvmstat等OSのコマンドから確認するが、SGAの領域はHugePageを使うため、その分を考慮して評価する必要がある。よく聞かれることが多いので、ExadataのDBサーバのメモリ使用率について、vmstatの結果からの確認方法のメモを残しておく。
1.OSのメモリ利用状況の確認方法について
一般的にLinuxのメモリ使用率を確認するためにfreeコマンドを使う。数値の単位はKBである。
[oracle@db01 ~]$ free
total used free shared buffers cached
Mem: 790788832 738741596 52047236 6554056 763312 226434384
-/+ buffers/cache: 511543900 279244932
Swap: 25165820 0 25165820
OSから認識されるメモリ全体量はtotal。この例では755GB程度(実際の物理メモリは768GBなので若干少なくなる)。total=used+freeの関係になっているが、このusedが使用済みメモリという訳ではない点に注意が必要である。このusedのうち、buffers+cached: 227197696KB(217GB)はアクティブプロセスで使われていない領域を示す。従って、実質的な空きメモリと使用メモリのサイズは以下の式で求めることができる。
・空きメモリサイズ=free+ buffers + cached ※この例では279244932(266GB)
・使用メモリサイズ=used-(buffers + cached) ※この例では511543900(488GB)
なお、上記のtotalのサイズは/proc/meminfoのMemTotalで確認することができる。
[oracle@db01 bin]$ cat /proc/meminfo
MemTotal: 790788832 kB
2.vmstatの結果からのメモリ使用率について
vmstatの結果を見ると、下記の通りfree, buffer, cachedが確認できる(それぞれ単位はKB)ので、これらを合計したのが実質的な空きメモリサイズである。使用率を確認するにはメモリ全体量が必要だが、vmstatでは確認できないので、別途/proc/meminfo等で確認が必要である。
メモリ使用率= 1- (free+buff+cache) / MemTotal
※下記例の★部分では1- (52650176 + 763312 + 226436064) / 790788832 = 65% ...(1)
例)
[oracle@db01 ~]$ vmstat 5 10
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 0 52932476 763312 226435088 0 0 10 11 0 0 2 2 97 0 0
1 0 0 52791844 763312 226435536 0 0 0 226 13319 1140813 4 5 91 0 0
★ 2 0 0 52650176 763312 226436064 0 0 0 384 13871 1076744 4 5 91 0 0
3.Hugepageの考慮について
上記ではHugePageは考慮されていない。HugePageはSGA格納用としてOS起動時に予約されるメモリ領域である。ユーザプロセス(サーバプロセスやPGA領域)はHugePagesを使うことができないため、そもそもHugePage領域を使用率の分母に入れることに大きな意味はない。DBサーバのメモリを監視する際、個人的にはHugePage領域を考慮(除外)し監視する方が実態に合うのではないかと考える。
HugePageのサイズは/proc/meminfoで確認ができる。
例)
[oracle@db01 bin]$ cat /proc/meminfo
・・・
HugePages_Total: 230912 ・・・HugePageのブロック数
Hugepagesize: 2048 kB ・・・HugePageのブロックサイズ
HugePageの領域は実質OSでは利用できないため、実質トータルで利用可能なメモリは下記式の通りとなる。
実質トータル利用可能メモリサイズ = MemTotal - HugePageサイズ = MemTotal - HugePages_Total x Hugepagesize
ここから、結局HugePageを考慮した実質メモリ使用率は以下の式で計算できる。
HugePageを考慮した実質メモリ使用率 = 1- (free+buff+cache) / ( MemTotal - HugePages_Total x Hugepagesize )
上記例では、以下の通り分母は303GBとなるため、vmstatからfree+buff+cacheを計算するだけで、HugePageを考慮したメモリ使用率を導くことができる。
MemTotal - HugePages_Total x Hugepagesize = 790788832KB(755GB) - 230912x2048KB(451GB) = 317,881,056KB(303GB)
※下記例の★部分では1- (52650176 + 763312 + 226436064) / ( 317881056 ) =~ 12% ...(2)
例)
[oracle@db01 ~]$ vmstat 5 10
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 0 52932476 763312 226435088 0 0 10 11 0 0 2 2 97 0 0
1 0 0 52791844 763312 226435536 0 0 0 226 13319 1140813 4 5 91 0 0
★ 2 0 0 52650176 763312 226436064 0 0 0 384 13871 1076744 4 5 91 0 0
HugePageを考慮しない(1)と65%だったメモリ使用率が、考慮する(2)だと12%となる。後者の方がどの程度APが処理してメモリを消費しているか直感的に把握し易いと考える。
4.まとめ
vmstatからDBサーバの実質的なメモリ使用率を求めるためには、まず/proc/meminfoからHugePageを考慮した実質的に利用可能なメモリサイズを求め、以下の式を用いて実質メモリ使用率を求める。
HugePageを考慮した実質メモリ使用率 = 1- (free+buff+cache) / ( MemTotal - HugePages_Total x Hugepagesize )
free, buff, cache ... vmstatの値
MemTotal, HugePages_Total, Hugepagesize ... /proc/meminfoの値
以上
1.OSのメモリ利用状況の確認方法について
一般的にLinuxのメモリ使用率を確認するためにfreeコマンドを使う。数値の単位はKBである。
[oracle@db01 ~]$ free
total used free shared buffers cached
Mem: 790788832 738741596 52047236 6554056 763312 226434384
-/+ buffers/cache: 511543900 279244932
Swap: 25165820 0 25165820
OSから認識されるメモリ全体量はtotal。この例では755GB程度(実際の物理メモリは768GBなので若干少なくなる)。total=used+freeの関係になっているが、このusedが使用済みメモリという訳ではない点に注意が必要である。このusedのうち、buffers+cached: 227197696KB(217GB)はアクティブプロセスで使われていない領域を示す。従って、実質的な空きメモリと使用メモリのサイズは以下の式で求めることができる。
・空きメモリサイズ=free+ buffers + cached ※この例では279244932(266GB)
・使用メモリサイズ=used-(buffers + cached) ※この例では511543900(488GB)
なお、上記のtotalのサイズは/proc/meminfoのMemTotalで確認することができる。
[oracle@db01 bin]$ cat /proc/meminfo
MemTotal: 790788832 kB
2.vmstatの結果からのメモリ使用率について
vmstatの結果を見ると、下記の通りfree, buffer, cachedが確認できる(それぞれ単位はKB)ので、これらを合計したのが実質的な空きメモリサイズである。使用率を確認するにはメモリ全体量が必要だが、vmstatでは確認できないので、別途/proc/meminfo等で確認が必要である。
メモリ使用率= 1- (free+buff+cache) / MemTotal
※下記例の★部分では1- (52650176 + 763312 + 226436064) / 790788832 = 65% ...(1)
例)
[oracle@db01 ~]$ vmstat 5 10
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 0 52932476 763312 226435088 0 0 10 11 0 0 2 2 97 0 0
1 0 0 52791844 763312 226435536 0 0 0 226 13319 1140813 4 5 91 0 0
★ 2 0 0 52650176 763312 226436064 0 0 0 384 13871 1076744 4 5 91 0 0
3.Hugepageの考慮について
上記ではHugePageは考慮されていない。HugePageはSGA格納用としてOS起動時に予約されるメモリ領域である。ユーザプロセス(サーバプロセスやPGA領域)はHugePagesを使うことができないため、そもそもHugePage領域を使用率の分母に入れることに大きな意味はない。DBサーバのメモリを監視する際、個人的にはHugePage領域を考慮(除外)し監視する方が実態に合うのではないかと考える。
HugePageのサイズは/proc/meminfoで確認ができる。
例)
[oracle@db01 bin]$ cat /proc/meminfo
・・・
HugePages_Total: 230912 ・・・HugePageのブロック数
Hugepagesize: 2048 kB ・・・HugePageのブロックサイズ
HugePageの領域は実質OSでは利用できないため、実質トータルで利用可能なメモリは下記式の通りとなる。
実質トータル利用可能メモリサイズ = MemTotal - HugePageサイズ = MemTotal - HugePages_Total x Hugepagesize
ここから、結局HugePageを考慮した実質メモリ使用率は以下の式で計算できる。
HugePageを考慮した実質メモリ使用率 = 1- (free+buff+cache) / ( MemTotal - HugePages_Total x Hugepagesize )
上記例では、以下の通り分母は303GBとなるため、vmstatからfree+buff+cacheを計算するだけで、HugePageを考慮したメモリ使用率を導くことができる。
MemTotal - HugePages_Total x Hugepagesize = 790788832KB(755GB) - 230912x2048KB(451GB) = 317,881,056KB(303GB)
※下記例の★部分では1- (52650176 + 763312 + 226436064) / ( 317881056 ) =~ 12% ...(2)
例)
[oracle@db01 ~]$ vmstat 5 10
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 0 52932476 763312 226435088 0 0 10 11 0 0 2 2 97 0 0
1 0 0 52791844 763312 226435536 0 0 0 226 13319 1140813 4 5 91 0 0
★ 2 0 0 52650176 763312 226436064 0 0 0 384 13871 1076744 4 5 91 0 0
HugePageを考慮しない(1)と65%だったメモリ使用率が、考慮する(2)だと12%となる。後者の方がどの程度APが処理してメモリを消費しているか直感的に把握し易いと考える。
4.まとめ
vmstatからDBサーバの実質的なメモリ使用率を求めるためには、まず/proc/meminfoからHugePageを考慮した実質的に利用可能なメモリサイズを求め、以下の式を用いて実質メモリ使用率を求める。
HugePageを考慮した実質メモリ使用率 = 1- (free+buff+cache) / ( MemTotal - HugePages_Total x Hugepagesize )
free, buff, cache ... vmstatの値
MemTotal, HugePages_Total, Hugepagesize ... /proc/meminfoの値
以上


