補助インスタンスを用いた表単位のリカバリ [アーキテクチャ]
1.はじめに
最近関わっている案件で、DBは遠隔の災対環境へ常時同期し、罹災時に災対環境に切り替えする、ただし特定の表(複数)だけ、前日の特定リストアポイントに復旧したい、という要件があった。いくつか検討した方式が以下であった。
(a)災対同期をGoldenGate等論理レプリケーションとし表毎に同期を制御できるようにする
(b)災対同期はDataGuardで物理レプリケーションとし、フェールオーバー後に
(b-1)前日断面のエクスポートを取得しておき、それをインポートする
(b-2)フラッシュバックテーブルで特定表を復旧
(b-3)補助インスタンスを用いた表単位のリカバリ
このうち、(a)は災対側の維持運用の負荷が高いので、(b)の方向性が望ましい。ActiveDataGuardなら(b-1)方式で、災対側でエクスポートしておくのがシンプルだ。しかし、表数やサイズが大きいと罹災時のRTOが許容できるか、ダンプファイルの置き場所やダンプ処理にかかる時間も実運用上許容されるかといった懸念がある。
(b-2)はDBオープン後にフラッシュバックテーブルで特定断面に戻す方法である。フラッシュバックテーブルは内部的にはUNDOを使ってリストアポイントまでリカバリする。母体の表サイズが大きくても更新が少なければ高速に処理が完了する。リストアポイントまでのUNDOが上書きされないよう、十分にUNDOリテンションを確保する必要がある。リストアポイントまでの間にalter table等のDDLが実行された場合はフラッシュバックテーブルは使えない(エラーとなる)という制約があり、プライマリ側で定義変更後に罹災するなど刹那なタイミングで復旧できないリスクがあるため、これだけに頼るのもリスクがある。
そこで(b-3)補助インスタンスを用いた表単位のリカバリである。これはRMANバックアップとアーカイブログを利用し、仮のインスタンスを立てて特定の(複数の)表をリカバリする機能である。災対側でもRMANのバックアップがとられていれば、そこから表の特定時点の断面を取り出すことができる。
今回、この補助インスタンスを用いた表単位のリカバリを実際に行い、補助インスタンスを利用した表リカバリについて考察してみたい。
2.検証モデル
ここでは、補助インスタンスを使った表単位のリカバリで、PDB上のSCOTT.EMPを特定のリストアポイント(=SCN)にリカバリしてみる(その他のDBは最新状態のまま)。テスト環境は手元のVirtual BoxのOracle19.11を使う。テスト準備として、アーカイブログモードとし、RMANフルバックアップを取得する。補助インスタンスリストア用に/mntをC:\Users\kazuhiro\Downloadsにマウントしておく(VirtualBoxの共有フォルダの設定)。
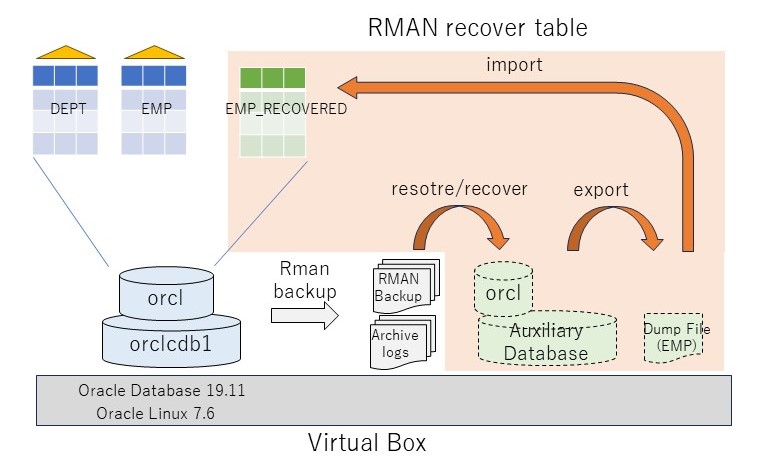
テストシナリオは以下の通り:
- PDB名ORCLのSCOTT.EMP/DEPTを作成、初期データを挿入
- リストアポイント取得
- EMPにINSERT 1件
- EMPをリストアポイントにリカバリした内容をEMP_RECOVER表に復旧
テストのコマンドは以下の通り。ポイントは★の部分のRMANコマンドで、recover tableで、EMP表をEMP_RECOVERED表に復旧するようにしている。なお、@empはemp表の作成スクリプトである。EMP表には初期データとして14件、リストアポイント作成後にempno=9999を1行を追加している。したがって、復旧した際には15件ではなく、14件となることが期待である。
rman target /
backup as compressed backupset database;
--EMP表作成
sqlplus scott/oracle@orcl
@emp
select count(*) from dept;
select count(*) from emp;
--リストアポイント(zenjitu)を作成
sqlplus sys/oracle@orcl as sysdba
create restore point zenjitu;
--リストアポイント後の更新を実行
sqlplus scott/oracle@orcl
insert into emp
values(
9999, 'KAZUHIRO', 'TAKAHASHI', 7000,
to_date('08-03-2024','dd-mm-yyyy'),
1000, null, 10
);
commit;
select count(*) from emp;
select * from emp where empno=9999;
exit
--★表のリカバリ(EMP表をEMP_RECOVERED表に復旧する)
rman target /
recover table scott.emp of pluggable database orcl until restore point ZENJITU auxiliary destination '/mnt' REMAP TABLE 'SCOTT'.'EMP':'EMP_RECOVERED' ;
select count(*) from dept;
select count(*) from emp;
select * from emp where empno=9999;
select segment_name, bytes, blocks from user_segments;
desc emp
desc emp_recovered
3.検証結果
補助インスタンスを用いた表のリカバリは、内部的に以下の動作を行っていることがわかった(検証結果のログは参考[1]を参照されたい)。ポイントとなる部分に★を付けたので、ここだけ追えば概ね流れは理解できるだろう。
SID='gicq'でインスタンスを起動 SCNをリストアポイントに設定 制御ファイルをリストア ★①補助インスタンス用制御ファイル クローンデータベースをマウント ログスイッチ SCNをリストアポイントに設定 クローンデータファイルの1,9,4,11,3,10とtempファイルの1,3に新しい名前を付与 全てのtempfileをスイッチ クローンデータファイルをリストア(1,9,4,11,3,10) ★②CDBリストア 全てのクローンデータファイルをスイッチ SCNをリストアポイントに設定 クローンデータファイルをオンライン(1,9,4,11,3,10) クローンデータベースの表領域をリカバリ ★③CDBメディアリカバリ "SYSTEM", "ORCL":"SYSTEM", "UNDOTBS1", "ORCL":"UNDOTBS1", "SYSAUX", "ORCL":"SYSAUX" クローンデータベースをリードオンリーでオープン クローンのPDBをオープン(ORCL) クローンでspfileをメモリから生成 クローンをシャットダウン クローンをnomountで起動 制御ファイルを設定(①でリストアしたファイル) クローンをシャットダウン クローンをnomountで起動 クローンをマウント SCNをリストアポイントに設定 クローンデータファイルの12に新しい名前を付与 クローンデータファイルをリストア(12) ★④PDBリストア 全てのクローンデータファイルをスイッチ SCNをリストアポイントに設定 クローンORCLのデータファイルをオンライン(12) クローンデータベースの表領域をリカバリ ★⑤PDBメディアリカバリ "ORCL":"USERS", "SYSTEM", "ORCL":"SYSTEM", "UNDOTBS1", "ORCL":"UNDOTBS1", "SYSAUX", "ORCL":"SYSAUX" delete archivelog クローンデータベースをリセットログでオープン クローンのPDBをオープン(ORCL) ORCLにディレクトリオブジェクトを作成する(TSPITR_DIROBJ_DPDIR as /mnt) クローンのORCLにディレクトリオブジェクトを作成する(TSPITR_DIROBJ_DPDIR as /mnt) 表のエクスポート(/mnt/tspitr_gicq_28603.dmp) ★⑥表エクスポート クローンデータベースをシャットダウン(abort) 表のインポート ★⑦表インポート 自動インスタンスの削除
復旧後の結果確認をしたところ、想定通りEMP_RECOVEREDが作成されている。件数は14件で、INSERTの更新前のリストアポイントに復旧していることがわかる。
[oracle@localhost ~]$ sqlplus scott/oracle@orcl
...
SQL> select table_name from user_tables;
TABLE_NAME
--------------------------------------------------------------------------------
DEPT
EMP
EMP_RECOVERED ★
SQL>
SQL> select count(*) from EMP_RECOVERED;
COUNT(*)
----------
14
SQL>
SQL> select * from emp where empno=9999;
EMPNO ENAME JOB MGR HIREDATE SAL COMM
---------- ---------- --------- ---------- --------- ---------- ----------
DEPTNO
----------
9999 KAZUHIRO TAKAHASHI 7000 08-MAR-24 1000
10
SQL> select * from EMP_RECOVERED where empno=9999;
no rows selected
セグメントの状態を確認すると、EMP_RECOVEREDにはPKの索引がない。表の定義を確認すると、EMPNOのNOT NULL制約がなくなっていた。FK制約もない。データは復旧できるが、表の制約は外れてしまうようだ。
SQL> select segment_name, bytes, blocks from user_segments; SEGMENT_NAME BYTES BLOCKS ________________ ________ _________ DEPT 65536 8 EMP 65536 8 EMP_RECOVERED 65536 8 ★対応するPK索引がない PK_DEPT 65536 8 PK_EMP 65536 8 SQL> SQL> desc emp Name Null? Type ___________ ___________ _______________ EMPNO NOT NULL NUMBER(4) ENAME VARCHAR2(10) JOB VARCHAR2(9) MGR NUMBER(4) HIREDATE DATE SAL NUMBER(7,2) COMM NUMBER(7,2) DEPTNO NUMBER(2) SQL> desc emp_recovered Name Null? Type ___________ ________ _______________ EMPNO NUMBER(4) ★NOT NULLがない ENAME VARCHAR2(10) JOB VARCHAR2(9) MGR NUMBER(4) HIREDATE DATE SAL NUMBER(7,2) COMM NUMBER(7,2) DEPTNO NUMBER(2) SQL> SQL> select index_name from user_indexes; INDEX_NAME _____________ PK_DEPT PK_EMP SQL> select constraint_name,constraint_type,table_name,status from user_constraints; CONSTRAINT_NAME CONSTRAINT_TYPE TABLE_NAME STATUS __________________ __________________ _____________ __________ FK_DEPTNO R EMP ENABLED PK_DEPT P DEPT ENABLED PK_EMP P EMP ENABLED ★EMP_RECOVEREDに対応するPK制約がない SQL>
4.考察
今回の検証を通して分かったことは以下の通り
- recover table scott.emp of pluggable database orcl until restore pointで特定の表の断面を復旧させることが可能
- 補助インスタンスに必要なメモリ(SGAのサイズ)は元のDBと同じ
- 補助インスタンスに必要な領域はSYSTEM、SYSAUX、UNDO(CDBとPDB)+復旧したい表の格納されている表領域を構成するデータファイルの合計サイズ+TEMP(CDBとPDB)+REDO+リストアが必要なアーカイブログ
- 復旧時間は上記ファイルのリストアおよびSCNまでのリカバリ時間+エクスポート+インポートの時間
- 復旧した表は制約が外れる
今回の検証結果を踏まえると、データの内容は復旧できるが、表の制約や関連する索引は復旧できない。元表をドロップして、recover tableで戻したとしても、その状態から制約や索引を付与する対処をすることは、運用上結構厳しいかもしれない。それならば、今回のように別名で一度復旧させて、元表をトランケートし、insert into selectでコピー、リストアした表をドロップが良いだろう。一時的にこの表の領域が2倍必要となるが、表毎の個別対応をするよりはシンプルに復旧できる。
SQL> truncate table emp; Table EMP truncated. SQL> insert /*+ append */ into emp select * from emp_recovered; 14 rows inserted. SQL> commit; Commit complete. SQL> drop table emp_recovered; Table EMP_RECOVERED dropped. SQL>
もう一つ考えられるのは、RESTOREコマンドにNOTABLEIMPORT句をつけて、ダンプの出力で留めておく方法である。インポートする際にトランケートモード、DATA_ONLYでインポートすれば、索引を維持したままデータを復旧できるし、DB領域は余計にかからないだろう。
22.1.3.4 リカバリされた表および表パーティションのターゲット・データベースへのインポートについて デフォルトでは、RMANは、リカバリされた表または表パーティション(エクスポート・ダンプ・ファイルに格納される)をターゲット・データベースにインポートします。ただし、RESTOREコマンドのNOTABLEIMPORT句を使用すると、リカバリされた表または表パーティションをインポートしないように選択できます。
もしリストアポイント後に定義変更がされていた場合、元表と復旧した表とで定義が異なることになる。この場合はやはり表は再作成(必要な索引も含め)した上で、上記いずれかの対応を取ることになるのだろう。データやオブジェクトの依存関係を考えなければならないという点で、オブジェクトレベルのリカバリは本質的に難易度が高くなるのは仕方がない。
5.まとめ
本稿では補助インスタンスを用いた表のリカバリについて、実機検証した結果を踏まえ活用方法について考察した。総じて言えるのは、バックアップから特定の表の特定の状態のダンプファイルを生成することができる、という点は極めて有用である。本質的には複雑な処理をRMANの1つのコマンドで実現できてしまうのは非常に有難い。
ただ、使いどころという観点では、あまり大量の表に対して実行するケースには向いておらず、特定、あるいはいくつかの表について復旧したい場合に限られるだろう。補助インスタンスは復旧に関連する表領域(を構成するデータファイル)をリストアするため、復旧範囲が広がれば広がるほど、元のデータベースと同じ領域が補助インスタンスに必要となってしまうし、ダンプファイルも大きくなってしまう。
今回の結果を踏まえると、フラッシュバックテーブルが使えるなら、多くの場合でその方が復旧はシンプルで速いだろう。UNDOを大きくとる必要はあるが、バックアップ運用が回れば副作用はないように思う。それでもUNDOが不足した場合(ギャランティでない場合は上書きされてしまう)は復旧できないというリスクがあるし、定義変更の影響もあるので、そういった表についてはこの方法で個別にリカバリすればよいだろう。
今回調べている中で、TSPITRを使った表領域のリカバリもできることが気が付いた。リカバリしたい表(+関連する索引)を表領域にまとめられれば、有効な復旧方法になるかもしれない。この点については、別途検証してみたい。Oracleは様々なリカバリ方法が用意されているので、ユーザ側が要件に対してどこまで使い方をイマジネーションできるかが重要である。
参考
[1]補助インスタンスを用いた表のリカバリ検証のログ20240311_recovertable.txt
[2]バックアップおよびリカバリ・ユーザーズ・ガイド 19c, 22 表および表パーティションのリカバリ
2024-03-16 20:58
SQL*Loaderの性能見積もりの考え方 [アーキテクチャ]
はじめに
データ移行等でcsvをSQL*LoaderでOracleにロードする際、どの程度の性能を期待できるのかを見積もる必要がある。特定の表についてであれば、実機の基礎性能をベースに件数で比例させれば簡単に見積もりができる。しかし、実際は様々な表があり、それぞれに対して測定する訳にもいかない。ここでは、簡単なテストケースでLoaderの基礎性能を測定し、平均行長と行数からロード性能を見積もる方法について考察してみたい。
1.性能モデル
やりたいことは、特定の環境において、入力となるcsvの平均行長と行数から、SQL*Loaderの性能を見積もりすることである。
方法として考えたのは、平均行長の異なる3つの表、b10tbl, b50tbl, b100tblについて、一定の件数(10,000,000件)のロード性能を基礎数値として取得し、それをもとに性能を見積もる方法である。
モデルとした表は、idカラムをnumber型の主キーとし、1からの連番を振る。dtカラムはdate型で、更新日時を入れる。col1~colnはvarchar2(10)のカラムで、b10tblは1個、b50tblは5個、b100tblは10個とし、ランダムな文字列を10バイト挿入する。
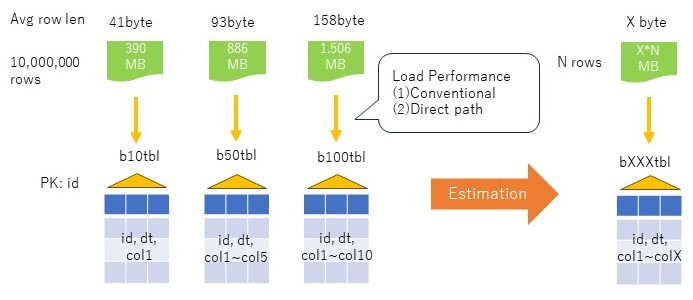
Loaderの測定パタンとしては、一般的なにコンベンショナルとダイレクトパスロードを考える。前提として、データは主キー順に並んでいることは保証されず、主キーは作成しつつ挿入することとする。NOLOGGINGも使わない。表のPCTFREEはデフォルト10%、記憶域(初期エクステントサイズ)もデフォルト(64KB)とする。
2.表(データ)の準備
表を作成する。
drop table b10tbl cascade constraints; create table b10tbl( id number(9), dt date, col1 varchar2(10), constraint pk_b10tbl primary key (id) ); drop table b50tbl cascade constraints; create table b50tbl( id number(9), dt date, col1 varchar2(10), col2 varchar2(10), col3 varchar2(10), col4 varchar2(10), col5 varchar2(10), constraint pk_b50tbl primary key (id) ); drop table b100tbl cascade constraints; create table b100tbl( id number(9), dt date, col1 varchar2(10), col2 varchar2(10), col3 varchar2(10), col4 varchar2(10), col5 varchar2(10), col6 varchar2(10), col7 varchar2(10), col8 varchar2(10), col9 varchar2(10), col10 varchar2(10), constraint pk_b100tbl primary key (id) );
SQL*Loader用のcsvを生成するための初期データを挿入する。
begin
for i in 1..10 loop
insert into b10tbl select
1000000*(i-1)+rownum id,
sysdate dt,
dbms_random.string('x',10) col1
from dual connect by level <=1000000;
commit;
end loop;
end;
/
begin
for i in 1..10 loop
insert into b50tbl select
1000000*(i-1)+rownum id,
sysdate dt,
dbms_random.string('x',10) col1,
dbms_random.string('x',10) col2,
dbms_random.string('x',10) col3,
dbms_random.string('x',10) col4,
dbms_random.string('x',10) col5
from dual connect by level <=1000000;
commit;
end loop;
end;
/
begin
for i in 1..10 loop
insert into b100tbl select
1000000*(i-1)+rownum id,
sysdate dt,
dbms_random.string('x',10) col1,
dbms_random.string('x',10) col2,
dbms_random.string('x',10) col3,
dbms_random.string('x',10) col4,
dbms_random.string('x',10) col5,
dbms_random.string('x',10) col6,
dbms_random.string('x',10) col7,
dbms_random.string('x',10) col8,
dbms_random.string('x',10) col9,
dbms_random.string('x',10) col10
from dual connect by level <=1000000;
commit;
end loop;
end;
/
統計情報を取得しておく(_optimizer_gather_stats_on_loadがデフォルト(TRUE)のため、空だと自動で取得されてしまうかもしれないため)。
exec dbms_stats.gather_table_stats('scott','b10tbl');
exec dbms_stats.gather_table_stats('scott','b50tbl');
exec dbms_stats.gather_table_stats('scott','b100tbl');
この時点でセグメントサイズを確認しておく。
col segment_name for a20 select segment_name, sum(bytes)/1024/1024 mb from user_segments where segment_name like '%B%TBL' group by segment_name order by 1; SEGMENT_NAME MB -------------------- ---------- B100TBL 1415 B10TBL 327 B50TBL 804 PK_B100TBL 160 PK_B10TBL 164 PK_B50TBL 163 6 rows selected.
ここから、csvファイルを出力するためのSQLファイルを作成する。ここで主キーでのソートはしない。csvの出力先を/u01とする(OCIのBaseDBは/u01のファイルシステムに196Gが割り当てられている。/homeは1GBもないので、大きなファイルを置いてはいけない)。
vi b10tbl.sql spool /u01/app/oracle/dump/scott/b10tbl.csv select * from b10tbl; spool off vi b50tbl.sql spool /u01/app/oracle/dump/scott/b50tbl.csv select * from b50tbl; spool off vi b100tbl.sql spool /u01/app/oracle/dump/scott/b100tbl.csv select * from b100tbl; spool off
上記sqlファイルをsqlplusから実行して、csvファイルを作成する。
sqlplus scott/xxx@oradb alter session set nls_date_format='YYYYMMDD HH24:MI:SS'; set feedback off heading off termout off set markup csv on delimiter '|' @b10tbl.sql @b50tbl.sql @b100tbl.sql set markup csv off
csvのサイズは以下の通り、最大のB100TBLで1.47GBであった。
[oracle@oradbvm1 ~]$ cd /u01/app/oracle/dump/scott/ [oracle@oradbvm1 scott]$ ll *.csv -rw-r--r-- 1 oracle oinstall 1578888897 Feb 18 16:19 b100tbl.csv -rw-r--r-- 1 oracle oinstall 408888897 Feb 18 16:17 b10tbl.csv -rw-r--r-- 1 oracle oinstall 928888897 Feb 18 16:18 b50tbl.csv [oracle@oradbvm1 scott]$
3.SQL*Loaderの準備
SQL*Loaderの制御ファイルを用意する。トランケートモードとして、表にデータが入っていれば切り捨てられる。
vi b10tbl.ctl load data characterset UTF8 infile '/u01/app/oracle/dump/scott/b10tbl.csv' badfile 'b10tbl.bad' discardfile 'b10tbl.dsc' truncate into table b10tbl fields terminated by '|' optionally enclosed by '"' trailing nullcols ( id integer external, dt date 'YYYYMMDD HH24:MI:SS', col1 char(10) ) vi b50tbl.ctl load data characterset UTF8 infile '/u01/app/oracle/dump/scott/b50tbl.csv' badfile 'b50tbl.bad' discardfile 'b50tbl.dsc' truncate into table b50tbl fields terminated by '|' optionally enclosed by '"' trailing nullcols ( id integer external, dt date 'YYYYMMDD HH24:MI:SS', col1 char(10), col2 char(10), col3 char(10), col4 char(10), col5 char(10) ) vi b100tbl.ctl load data characterset UTF8 infile '/u01/app/oracle/dump/scott/b100tbl.csv' badfile 'b100tbl.bad' discardfile 'b100tbl.dsc' truncate into table b100tbl fields terminated by '|' optionally enclosed by '"' trailing nullcols ( id integer external, dt date 'YYYYMMDD HH24:MI:SS', col1 char(10), col2 char(10), col3 char(10), col4 char(10), col5 char(10), col6 char(10), col7 char(10), col8 char(10), col9 char(10), col10 char(10) )
4.性能測定
上記のモデルを実際にOCIのBaseDBを利用して測定した。環境はこちらに記載の環境と同じため割愛する。
SQL*Loaderでロードを行う。まずは、コンベンショナルモードを使う。1000件毎にコミットとなるよう、rowsとbindsizeを設定する。
sqlldr scott/xxx@oradb control=b10tbl.ctl log=b10tblc.log rows=1000,bindsize=1000000,silent=errors,feedback sqlldr scott/xxx@oradb control=b50tbl.ctl log=b50tblc.log rows=1000,bindsize=1000000,silent=errors,feedback sqlldr scott/xxx@oradb control=b100tbl.ctl log=b100tblc.log rows=1000,bindsize=1000000,silent=errors,feedback
続いて、ダイレクトパス(direct=true)でデータロードを行う。1000件毎の処理となるよう、columnarrayrowsを設定する。
sqlldr scott/xxx@oradb control=b10tbl.ctl log=b10tbld.log direct=true, columnarrayrows=1000, silent=errors,feedback sqlldr scott/xxx@oradb control=b50tbl.ctl log=b50tbld.log direct=true, columnarrayrows=1000, silent=errors,feedback sqlldr scott/xxx@oradb control=b100tbl.ctl log=b100tbld.log direct=true, columnarrayrows=1000, silent=errors,feedback
5.測定結果
測定結果のサマリは下表の通り。
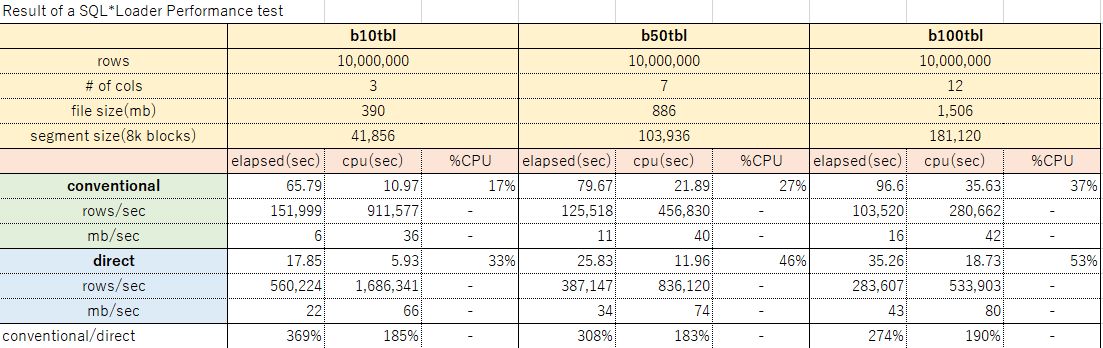
上記結果から、平均行長とロード性能の関係をグラフにすると、下図の通りとなった。行長が大きくなると線形に処理時間が伸びているように見えるため、ここから任意の平均行長について10,000,000件をロードする近似式を作ることができる。
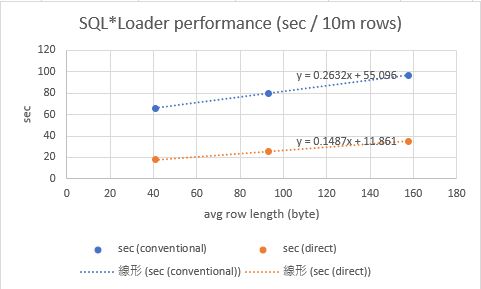
上記近似式で得られた結果から、単位行数あたりのロード時間が求まるので、下図のように任意の行数を時間を見積もる式が得られる。例えば、平均行長223バイト、5,000,000件のb200tblの場合は、コンベンショナルは57秒、ダイレクトパスロードは23秒と見積もることができる。

答え合わせのため、実際に平均行長223バイト、5,000,000件で測定したところ、コンベンショナルの見積もり57秒に対し54秒、ダイレクトパスの見積もり23秒に対し28秒となった。若干ブレはあるものの、まずまずの値が見積もれることがわかった。
SQL> !ls -l /u01/app/oracle/dump/scott/b200tbl.csv
-rw-r--r-- 1 oracle oinstall 1113888896 Feb 20 07:36 /u01/app/oracle/dump/scott/b200tbl.csv
SQL> select 1113888896/5000000 from dual;
222.777779 →平均カラム長223バイト
SQL> !wc -l /u01/app/oracle/dump/scott/b200tbl.csv
5000000 /u01/app/oracle/dump/scott/b200tbl.csv →5,000,000件
[oracle@oradbvm1 ldrtest]$ grep Elapsed b200tbld.log
Elapsed time was: 00:00:28.24 →ダイレクトパス
[oracle@oradbvm1 ldrtest]$ grep Elapsed b200tblc.log
Elapsed time was: 00:00:54.42 →コンベンショナル
[oracle@oradbvm1 ldrtest]$
7.まとめ
本稿では、SQL*Loaderの性能を、実機の基礎性能を用いて、任意の行長、行数のロード性能(コンベンショナル、ダイレクト)を見積もる方法について考察した。性能の結果はあくまで一例で、実際は入力ファイルの要件に応じてLoaderのパラメータは実際の利用シーンにより適宜変更が必要だろう。なお、平均行長が伸びると、線形に処理時間も伸びる、という仮定は一定の範囲を超えると誤差が大きくなるかもしれない。ブロックサイズ(今回の環境では8KB、PCTFREE10%)に対して、平均行長が極端に大きい場合は誤差が大きくなる可能性があるので、大きな行長を扱う場合は基礎性能モデルの作り方に注意が必要だろう。
◆参考
[1]測定結果詳細:20240218_sqlldrPerfTest_v2.xlsx
2024-02-20 06:47
DBのCPUサイジングについての一考察 [アーキテクチャ]
はじめに
DBサーバにどの程度のCPUが必要かを見積りしなければならない状況はよくある。
基盤更改の場合は、現行のシステムがあり、そのHWスペックもリソース状況もわかっているので、CPUの性能比から概ね精度の高い見積もりが可能である。しかし、全く新規業務の場合は、机上でどの程度のCPUが必要かを導くことは難しい。しかも、業務仕様や処理方式が決まっていない状況ではなおさらである。このような場合、想定する処理方式に対する性能の基礎数値が重要となる。
本稿では、DBの基礎的な処理(INSERT, SELECT, UPDATE, DELETE)の基礎数値を取得する簡単なモデルと処理(PL/SQL)を、OCIの環境で実測し、その結果を考察してみたい。なお、性能の結果は環境によって変わるので、あくまで参考程度と考えてほしい。
1.性能モデル
性能モデルとして、3つの表、b10tbl, b50tbl, b100tblを考える。
idカラムをnumber型の主キーとし、1からの連番を振る。dtカラムはdate型で、更新日時を入れる。col1~colnはvarchar2(10)のカラムで、b10tblは1個、b50tblは5個、b100tblは10個とし、ランダムな文字列を10バイト挿入する。初期データ件数は100万件とする。
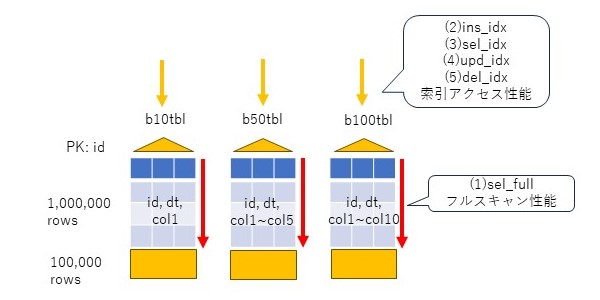
この表に対して、以下のパタンで基礎性能値を確認する。1番目はselectのフルスキャン、2~5番目は索引アクセスのパタン(insert、select、update、delete)である。索引アクセスは10万回行う。
2.表(データ)の準備
表を作成するDDLは以下の通り。
drop table b10tbl cascade constraints; create table b10tbl( id number(7), dt date, col1 varchar2(10), constraint pk_b10tbl primary key (id) ); drop table b50tbl cascade constraints; create table b50tbl( id number(7), dt date, col1 varchar2(10), col2 varchar2(10), col3 varchar2(10), col4 varchar2(10), col5 varchar2(10), constraint pk_b50tbl primary key (id) ); drop table b100tbl cascade constraints; create table b100tbl( id number(7), dt date, col1 varchar2(10), col2 varchar2(10), col3 varchar2(10), col4 varchar2(10), col5 varchar2(10), col6 varchar2(10), col7 varchar2(10), col8 varchar2(10), col9 varchar2(10), col10 varchar2(10), constraint pk_b100tbl primary key (id) );
初期データを挿入する。
insert into b10tbl select
rownum id,
sysdate dt,
dbms_random.string('x',10) col1
from dual connect by level <=1000000;
commit;
insert into b50tbl select
rownum id,
sysdate dt,
dbms_random.string('x',10) col1,
dbms_random.string('x',10) col2,
dbms_random.string('x',10) col3,
dbms_random.string('x',10) col4,
dbms_random.string('x',10) col5
from dual connect by level <=1000000;
commit;
insert into b100tbl select
rownum id,
sysdate dt,
dbms_random.string('x',10) col1,
dbms_random.string('x',10) col2,
dbms_random.string('x',10) col3,
dbms_random.string('x',10) col4,
dbms_random.string('x',10) col5,
dbms_random.string('x',10) col6,
dbms_random.string('x',10) col7,
dbms_random.string('x',10) col8,
dbms_random.string('x',10) col9,
dbms_random.string('x',10) col10
from dual connect by level <=1000000;
commit;
統計情報を取得する。
exec dbms_stats.gather_table_stats('scott','b10tbl');
exec dbms_stats.gather_table_stats('scott','b50tbl');
exec dbms_stats.gather_table_stats('scott','b100tbl');
作成した表のサイズを確認する。
col segment_name for a20 select segment_name, sum(bytes)/1024/1024 mb from user_segments where segment_name like '%B%TBL' group by segment_name order by 1;
3.測定
フルスキャン性能については、シンプルにautotraceの処理時間を想定する。select *としたのは、フルスキャンに主キーの索引が使われないにするためである。以下はb10tblの例である。
set timi on set autotrace traceonly select * from b10tbl; set autotrace off
INSERT性能は、PL/SQLで100万件の状態から10万件を追加する。この際、dtには更新日時、colxにはdbms_randomでランダムな文字列を生成して設定する。以下の例はb10tblなので、col1カラムだけであるが、b50tblでは5カラム、b100tblでは10カラム分、ランダムな文字列を生成し設定する。また、コミットは1件毎に実施する。
declare
i number;
begin
for i in 1000001..1100000 loop
insert into b10tbl values(i,sysdate,dbms_random.string('x',10));
commit;
end loop;
end;
/
SELECT性能は、同様にPL/SQLで、INSERTで積まれた10万件に対して、主キー一本引きのSQLを発行する。以下の例はb10tblなので、col1カラムだけであるが、b50tblでは5カラム、b100tblでは10カラム分、カラムを取得する。
declare i number; l_col1 varchar2(10); begin for i in 1000001..1100000 loop select col1 into l_col1 from b10tbl where id=i; end loop; end; /
SELECT性能は、同様にPL/SQLで、INSERTで積まれた10万件に対して、主キー一本引きでUPDATEを発行する。この際、dtには更新日時、colxにはdbms_randomでランダムな文字列を生成して設定する。以下の例はb10tblなので、col1カラムだけであるが、b50tblでは5カラム、b100tblでは10カラム分、ランダムな文字列を生成し設定する。コミットは1件毎に実施する。
declare
i number;
begin
for i in 1..100000 loop
update b10tbl set dt=sysdate,col1=dbms_random.string('u',10) where id=1000000+i;
commit;
end loop;
end;
/
DELETE性能は、同様にPL/SQLで、INSERTで積まれた10万件に対して、主キー一本引きのDELETEを発行する。コミットは1件毎に実施する。
declare i number; begin for i in 1000001..1100000 loop delete from b10tbl where id=i; commit; end loop; end; /
4.測定環境
上記のモデルを実際にOCIのBaseDBを利用して測定する。環境は以下の通り。
Shape: VM.Standard.E4.Flex CPU core count: 2 Oracle Database software edition: Enterprise Edition High Performance Storage management software: Oracle Grid Infrastructure Available data storage: 256 GB Recovery area storage: 256 GB Total storage size: 712 GB Theoretical max IOPS: 19.2K DB system version: 19.20.0.0.0
メモリの状態は以下の通り。SGAは14.5GB、そのうちバッファキャッシュは12GBである。
Memory Statistics
~~~~~~~~~~~~~~~~~ Begin End
------------ ------------
Host Mem (MB): 31,893.9 31,893.9
SGA use (MB): 14,848.0 14,848.0
PGA use (MB): 1,084.4 1,106.1
% Host Mem used for SGA+PGA: 49.95 50.02
Database Resource Limits
~~~~~~~~~~~~~~~~~~~~~~~~ Begin End
---------------- ----------------
CPUs: 4 4
SGA Target: 15,569,256,448 15,569,256,448
PGA Target: 3,892,314,112 3,892,314,112
Memory Target: 0 0
Cache Sizes Begin End
~~~~~~~~~~~ ---------- ----------
Buffer Cache: 12,352M 12,352M Std Block Size: 8K
Shared Pool Size: 1,405M 1,404M Log Buffer: 154,872K
In-Memory Area: 0M 0M
上記の方法でデータを作成したところ、以下のサイズ(表と索引)となった。合計でたかだか338MBなので、全てバッファキャッシュに十分収まる。
SEGMENT_NAME MB -------------------- ---------- B100TBL 157 B10TBL 36 B50TBL 94 PK_B100TBL 17 PK_B10TBL 17 PK_B50TBL 17
5.測定結果
下表に測定結果を示す。rowsは処理件数、elapsed(ms)は処理の経過時間を示す。1番目のsel_fullはautotraceの経過時間、その他2~5番目はSQLレポート上の経過時間を示す。ms/rowは、1件あたりの処理時間を示す。例えばsel_fullであれば100万件の処理時間を100万で割った数値、sel_idxであれば、10万件の処理時間を10万で割った数値を示す。tpsは1をms/rowで割った値で、単位時間(1秒)あたりの処理件数を示す。

なお、参考[1]に、測定結果とあわせて、AWRレポート、SQLレポートをまとめたexcelシートを載せているので、詳細に興味があればそちらを確認頂きたい。
6.考察
フルスキャンはカラム長が長くなるほどに処理時間が延びる。カラム長が長いと参照ブロック数が増えることになるので、当然だろう。表と索引はバッファキャッシュに乗っているため、処理時間にIOは含まれていない数字と理解する必要がある。
SELECTはカラム数が増えるとじわりと処理時間が伸びていることがわかる。SQLレポートのGetsを見る限り、SELECTは4ブロック/件の論理ブロック読み込みをしていた。索引に3ブロック(BLEVEL=2)、表に1ブロックの読み込みをしていると推測される。通常の索引はBLEVEL=3位になっていることが多いので、少し軽めな索引アクセスと理解する必要がある。
INSERTとUPDATEはほぼおなじ程度の処理単価となっている。カラム増加に対する処理時間の傾向もほぼ同じである。SQLレポートのGetsを見る限り、INSERTは5ブロック/件、UPDATEは6ブロック/件の論理ブロック読み込みをしていた。このうち4ブロックは更新ブロックの特定に使われているはずなので、残りが純粋な更新に必要なUNDO関連のブロック数と思われる。カラム増加による処理時間の伸びが顕著なのは、dbms_randomの呼び出し回数の影響が大きいかもしれない。純粋なDMLの処理時間を確認する意味では、関数を含めない方が良かったかもしれない。
DELETEはカラム数の増加の影響はかなり限定的に見える。SQLレポートのGetsを見る限り、8ブロック/件の論理ブロック読み込みをしていた。これも4ブロックは更新ブロックの特定に使われているはずで、残りがDELETEに必要なUNDO関連のブロックなのだろう。更新よりブロック数が多いのは、索引の更新に伴うものかもしれない(削除に伴い、索引のB*Treeおよびリーフブロックの更新が必要)。
単位時間あたりのトランザクション数(tps)については、総じてSQLの性能は、DMLより一桁は速い。INSERTやUPDATEで、b10tblで18倍、b100tblで40倍もの差がある。DELETEは比較的軽いが、それでも10倍程度の差がある。
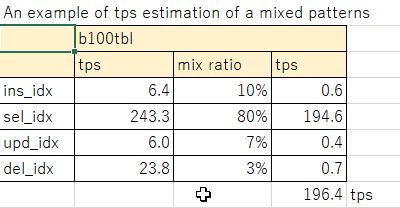
実際のシステムにおいては、一定の比率で参照、更新トランザクションが発生するので、上記を基礎数値として1コアあたりにさばけるトランザクション数が導き出せる。例えば、b100tblのモデルでselectが80%、insertが10%、updateが7%、deleteが3%の比率とすると、196tps/コアとなる。このような考え方で、必要な単位時間あたりのトランザクションに応じて、コア数を見積もることができる。実際に使うコアのスペックが異なる場合は、ここからspec int等のベンチマーク結果から、コア性能を考慮した見積もりを作れば良いだろう。
7.まとめ
DBサーバのCPUの見積もりについて、モデル(データ、処理モデル)から、OCIで実測した結果をもとに基礎数値を求めて、コア数を見積もる考え方について述べた。また、測定結果について、SQL、DMLの性能の傾向、カラム数(平均行長)に対する性能の傾向について考察した。
性能測定結果は環境によって変わるので、あくまで参考程度にしかならないとしても、実際の業務処理ロジックに近いモデルを作ることで、見積もりの精度を上げることができるだろう。
ありがたいことに、OCIのようなパブリッククラウドが使えるようになり、実機による測定ができる環境を実に簡単に準備できるようになった。いくばくかの利用料は発生するかもしれないが、コア数を比較的精度高く見積もることは、Oracleライセンス費の適正化につながるので、サイジング用にOCI使ったとしても十分にその価値はあるのではないかと感じる。
◆参考
[1]測定結果詳細:20240211_性能テスト結果_v2.xlsx
2024-02-11 14:03
Oracle19cでメンテナンスウィンドウのCPU高騰をチューニングした話 [アーキテクチャ]
OCIのBaseDB(Oracle19c)でメンテナンスウィンドウ時間帯のCPU高騰をチューニングしたので、メモを残しておく。結論から言うと、統計情報取得処理の中で、カラム統計の保留統計を削除するdelete文(5hud5urmn39bx)の実行計画が非効率だったので、SQLパッチを適用して回避したという話である。以下、事象、原因、対処について簡単に記載する。
OCIのBaseDB(19.11)で、メンテナンス時間帯にDBサーバのCPU使用率がかなり上がっていることが問題になっていた。メンテナンスウィンドウは平日7時~11時までに設定されていたが、メンテナンス時間中に複数のPDBで同時に以下のSQLが長時間化しており、CPUをほぼ使い切ってしまっている状況であった。
wri$_optstat_histhead_history表は、日次のパーティション表で、カラム統計のバックアップを保持する。通常はSAVTIMEはバックアップ日時が入るが、保留統計を使っている場合は、テーブル毎、カラム毎にSAVTIME=3000年12月1日で記録される。つまり、保留統計は全て同じパーティションに入る。
このdelete文は、savtime, obj#, intcol#の3つのプレディケートで削除対象を特定し、(保留)統計情報取得の際に、不要となった保留統計情報を削除していると思われる。様々な表のカラム統計が全く同じSAVTIMEで記録されるため、ある表の保留統計のレコードを識別するためにSAVTIMEでは絞り込めない。このため、表の数が増えてくると、保留統計取得に伴う過去カラム統計の削除に時間がかかるようになるのである。
SQLの実行計画は以下の通り。
◆非効率な実行計画
グローバルファンクション索引I_WRI$_OPTSTAT_HH_STでsavtimeで絞り込み、obj#とintcol#でフィルタをかけて削除対象のレコードを特定していることがわかる。この実行計画だと、同じSAVTIMEを持つレコードの件数が多いと、フィルタの絞り込みに時間がかる。
AWRレポートから、SQLの実行回数は6,571で、平均実行時間は0.48秒、論理読み込みブロック数は8,196.7である。保留統計の削除は全てsavtimeが同一であることから、パーティションのフルスキャンを繰り返し、結果としてバッファキャッシュ上のブロック読み込みでCPUを使ってしまう。そして、この処理が複数PDB(メンテナンス時間が一緒)で並列実行されるため、DBサーバのCPUが上昇してしまう、という状況を作り出していたのだろう。
他に有効な索引がないか確認したところ、以下のようにI_WRI$_OPTSTAT_HH_OBJ_ICOL_STという索引があった。これはobj#、intcol#、SYS_NC00027$で構成されているので、savtimeだけの絞り込みより効果がありそうである。
ちなみにSYS_NC00027$は仮想列で、TIMESTAMP WITH TIME ZONE型のsavtimeから、UTC時間を取り出していることが確認できる。
このdelete文は統計情報取得のプロシージャ内部で発行されているため、直接ヒントは使えない。SQLパッチで直接SQL_IDを指定して、I_WRI$_OPTSTAT_HH_OBJ_ICOL_STの索引を使うように誘導する。
SQLパッチ作成には、SQL_IDがv$sqlに存在している必要がある。遅延が発生している状況であれば、メンテナンス時間帯またはその直後ならライブラリキャッシュに確認できるはずである。統計情報を手動で取得すればこのdelete文も内部から発行されるはずである。当該SQLパッチは、PDB毎に設定する必要がある点に注意が必要である(CDBに設定してもPDBには効果がない)。
SQLパッチを適用した後、実行計画を確認したところ、期待通りI_WRI$_OPTSTAT_HH_OBJ_ICOL_STの索引が使われている。こちらの実行計画では索引でobj#とsavtimeを絞り込んでから、savtimeとintcol#でフィルターする形になる(索引だけではsavtimeを絞り込み切れないため、フィルタにも現れていると思われる)。
◆改善後の実行計画
上記の状態で、後日メンテナンスウィンドウ時間帯のリソースを確認したところ、このDMLによるCPU張り付きの事象は解消することができた。AWRのSQL ordered by...に現れない状態になった。
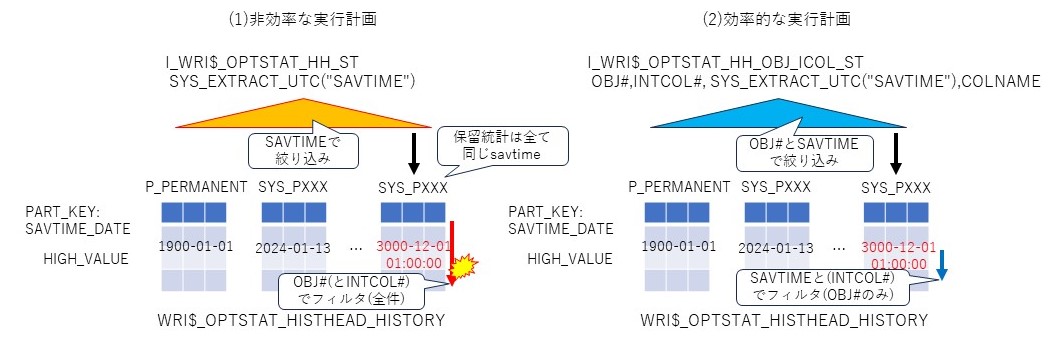
今回の事象を簡単に図に示す。遅延は(1)のI_WRI$_OPTSTAT_HH_STの索引を使ったとき、索引でsavtimeで絞り込んだ後、行をobj#(およびintcol#)で絞り込む部分で発生していたと考えられる。実際は保留統計の場合、savtimeは全て同じ値になっているので、全く絞り込みは効かない。(2)は、I_WRI$_OPTSTAT_HH_OBJ_ICOL_STの索引でobj#とsavtimeで絞り込み、行をsavtime(およびintcol#)で絞り込むため、効率が良い。
根本的な問いは、SQL_ID:5hud5urmn39bxにおいてI_WRI$_OPTSTAT_HH_OBJ_ICOL_ST ではなくI_WRI$_OPTSTAT_HH_ST が利用されていた要因は何か、という点である。10053トレース確認したところ、オプティマイザは両者の索引を比較して、I_WRI$_OPTSTAT_HH_STの方がコストが少ないと判断している。実際のトレースを見てみよう。
オプティマイザは★aでI_WRI$_OPTSTAT_HH_OBJ_ICOL_STのコスト計算を開始している。★bで索引の選択率を0.005435と推定し、★cでコストを4と推定している。その後、★dでI_WRI$_OPTSTAT_HH_STのコスト計算を開始し、★eで索引の選択率を7.3638e-04=0.00073と推定し、コストを2.001352と推定している。以上の結果から★fでI_WRI$_OPTSTAT_HH_STの方がコストが低いため、★gでこの索引を使う実行計画(非効率な実行計画)を選択している。問題は★eの部分において、保留統計の場合はsavtimeが全て同じ値になってしまう点が考慮されていないことではないかと感じている。col#27のヒストグラムが取得されており、バインドピークが有効になっていれば、適切な実行計画が選択されるかもしれない、という期待はあるが、本環境ではバインドピークは無効化しているため、そこまでの確認は行っていない。
本稿では、統計情報履歴削除のdelete文(5hud5urmn39bx)遅延の原因と対処方法について記載した。これは過去に保留統計でヒストグラムの統計履歴削除で遅延した事象(参考[1])と類似事象である。今回はヒストグラム統計は取得しない設定にしていたため、この問題には該当しなかった。
本件をサポートに問い合わせたところ、対処方法についてはSQLパッチが妥当とのことであった。改善要望として、当該回避方法を公開ドキュメント化していただけるようなので、そのうち、公になるかもしれない。
保留統計を使って、マルチテナントでPDBを多く抱えているようなDBでは、このCPU高騰の事象が顕在化しやすいので留意した方が良いかもしれない。
[1]保留統計との闘い~統計取得遅延問題
[2]WRI$_OPTSTAT_HISTHEAD_HISTORYの構成情報
・表・パーティション構成
・索引の構成
以上
1.事象
OCIのBaseDB(19.11)で、メンテナンス時間帯にDBサーバのCPU使用率がかなり上がっていることが問題になっていた。メンテナンスウィンドウは平日7時~11時までに設定されていたが、メンテナンス時間中に複数のPDBで同時に以下のSQLが長時間化しており、CPUをほぼ使い切ってしまっている状況であった。
Elapsed Elapsed Time
Time (s) Executions per Exec (s) %Total %CPU %IO SQL Id
---------------- -------------- ------------- ------ ------ ------ -------------
3,148.5 6,571 0.48 36.4 94.2 .0 5hud5urmn39bx
PDB: XXX
delete /* QOSH:PURGE_OLD_STS *//*+ dynamic_sampling(4) */ from sys.wri$_optstat_histhead_history
where :1 = savtime and obj# = :2 and intcol# = nvl(:3, intcol#)
Buffer Gets Elapsed
Gets Executions per Exec %Total Time (s) %CPU %IO SQL Id
----------- ----------- ------------ ------ ---------- ----- ----- -------------
53,860,231 6,571 8,196.7 30.6 3,148.5 94.2 .0 5hud5urmn39bx
PDB: XXX
delete /* QOSH:PURGE_OLD_STS *//*+ dynamic_sampling(4) */ from sys.wri$_optstat_histhead_history
where :1 = savtime and obj# = :2 and intcol# = nvl(:3, intcol#)
2.解析
wri$_optstat_histhead_history表は、日次のパーティション表で、カラム統計のバックアップを保持する。通常はSAVTIMEはバックアップ日時が入るが、保留統計を使っている場合は、テーブル毎、カラム毎にSAVTIME=3000年12月1日で記録される。つまり、保留統計は全て同じパーティションに入る。
このdelete文は、savtime, obj#, intcol#の3つのプレディケートで削除対象を特定し、(保留)統計情報取得の際に、不要となった保留統計情報を削除していると思われる。様々な表のカラム統計が全く同じSAVTIMEで記録されるため、ある表の保留統計のレコードを識別するためにSAVTIMEでは絞り込めない。このため、表の数が増えてくると、保留統計取得に伴う過去カラム統計の削除に時間がかかるようになるのである。
SQLの実行計画は以下の通り。
◆非効率な実行計画
Plan hash value: 120054584
--------------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop |
--------------------------------------------------------------------------------------------------------------------------------------------
| 0 | DELETE STATEMENT | | 1 | 85 | 4 (0)| 00:00:01 | | |
| 1 | DELETE | WRI$_OPTSTAT_HISTHEAD_HISTORY | | | | | | |
|* 2 | TABLE ACCESS BY GLOBAL INDEX ROWID BATCHED| WRI$_OPTSTAT_HISTHEAD_HISTORY | 1 | 85 | 4 (0)| 00:00:01 | ROWID | ROWID |
|* 3 | INDEX RANGE SCAN | I_WRI$_OPTSTAT_HH_ST | 19 | | 3 (0)| 00:00:01 | | |
--------------------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("OBJ#"=TO_NUMBER(:2) AND "INTCOL#"=NVL(:3,"INTCOL#"))
3 - access(SYS_EXTRACT_UTC("SAVTIME")=SYS_EXTRACT_UTC(TO_TIMESTAMP_TZ(:1)))
グローバルファンクション索引I_WRI$_OPTSTAT_HH_STでsavtimeで絞り込み、obj#とintcol#でフィルタをかけて削除対象のレコードを特定していることがわかる。この実行計画だと、同じSAVTIMEを持つレコードの件数が多いと、フィルタの絞り込みに時間がかる。
AWRレポートから、SQLの実行回数は6,571で、平均実行時間は0.48秒、論理読み込みブロック数は8,196.7である。保留統計の削除は全てsavtimeが同一であることから、パーティションのフルスキャンを繰り返し、結果としてバッファキャッシュ上のブロック読み込みでCPUを使ってしまう。そして、この処理が複数PDB(メンテナンス時間が一緒)で並列実行されるため、DBサーバのCPUが上昇してしまう、という状況を作り出していたのだろう。
他に有効な索引がないか確認したところ、以下のようにI_WRI$_OPTSTAT_HH_OBJ_ICOL_STという索引があった。これはobj#、intcol#、SYS_NC00027$で構成されているので、savtimeだけの絞り込みより効果がありそうである。
SQL> select index_name, column_name from user_ind_columns where table_name='WRI$_OPTSTAT_HISTHEAD_HISTORY' order by index_name, column_position; INDEX_NAME COLUMN_NAME ------------------------------ ------------------------------ I_WRI$_OPTSTAT_HH_OBJ_ICOL_ST OBJ# I_WRI$_OPTSTAT_HH_OBJ_ICOL_ST INTCOL# I_WRI$_OPTSTAT_HH_OBJ_ICOL_ST SYS_NC00027$ I_WRI$_OPTSTAT_HH_OBJ_ICOL_ST COLNAME I_WRI$_OPTSTAT_HH_ST SYS_NC00027$
ちなみにSYS_NC00027$は仮想列で、TIMESTAMP WITH TIME ZONE型のsavtimeから、UTC時間を取り出していることが確認できる。
SQL> select index_name, column_position, column_expression from user_ind_expressions where table_name='WRI$_OPTSTAT_HISTHEAD_HISTORY';
INDEX_NAME COLUMN_POSITION COLUMN_EXPRESSION
------------------------------ --------------- --------------------------------------------------------------------------------
I_WRI$_OPTSTAT_HH_OBJ_ICOL_ST 3 SYS_EXTRACT_UTC("SAVTIME")
I_WRI$_OPTSTAT_HH_ST 1 SYS_EXTRACT_UTC("SAVTIME")
3.対処(チューニング)
このdelete文は統計情報取得のプロシージャ内部で発行されているため、直接ヒントは使えない。SQLパッチで直接SQL_IDを指定して、I_WRI$_OPTSTAT_HH_OBJ_ICOL_STの索引を使うように誘導する。
SQLパッチ作成には、SQL_IDがv$sqlに存在している必要がある。遅延が発生している状況であれば、メンテナンス時間帯またはその直後ならライブラリキャッシュに確認できるはずである。統計情報を手動で取得すればこのdelete文も内部から発行されるはずである。当該SQLパッチは、PDB毎に設定する必要がある点に注意が必要である(CDBに設定してもPDBには効果がない)。
declare patch_name varchar2(20); begin patch_name := dbms_sqldiag.create_sql_patch( sql_id=>'5hud5urmn39bx', hint_text=>'index(@DEL$1 WRI$_OPTSTAT_HISTHEAD_HISTORY@DEL$1 I_WRI$_OPTSTAT_HH_OBJ_ICOL_ST)', name=>'5hud5urmn39bx_patch'); end; /
SQLパッチを適用した後、実行計画を確認したところ、期待通りI_WRI$_OPTSTAT_HH_OBJ_ICOL_STの索引が使われている。こちらの実行計画では索引でobj#とsavtimeを絞り込んでから、savtimeとintcol#でフィルターする形になる(索引だけではsavtimeを絞り込み切れないため、フィルタにも現れていると思われる)。
◆改善後の実行計画
Plan hash value: 3378320514
---------------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop |
---------------------------------------------------------------------------------------------------------------------------------------------
| 0 | DELETE STATEMENT | | 1 | 72 | 4 (0)| 00:00:01 | | |
| 1 | DELETE | WRI$_OPTSTAT_HISTHEAD_HISTORY | | | | | | |
| 2 | TABLE ACCESS BY GLOBAL INDEX ROWID BATCHED| WRI$_OPTSTAT_HISTHEAD_HISTORY | 1 | 72 | 4 (0)| 00:00:01 | ROWID | ROWID |
|* 3 | INDEX RANGE SCAN | I_WRI$_OPTSTAT_HH_OBJ_ICOL_ST | 1 | | 3 (0)| 00:00:01 | | |
---------------------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("OBJ#"=TO_NUMBER(:2) AND SYS_EXTRACT_UTC("SAVTIME")=SYS_EXTRACT_UTC(TO_TIMESTAMP_TZ(:1)))
filter("INTCOL#"=NVL(:3,"INTCOL#") AND SYS_EXTRACT_UTC("SAVTIME")=SYS_EXTRACT_UTC(TO_TIMESTAMP_TZ(:1)))
上記の状態で、後日メンテナンスウィンドウ時間帯のリソースを確認したところ、このDMLによるCPU張り付きの事象は解消することができた。AWRのSQL ordered by...に現れない状態になった。
4.考察
今回の事象を簡単に図に示す。遅延は(1)のI_WRI$_OPTSTAT_HH_STの索引を使ったとき、索引でsavtimeで絞り込んだ後、行をobj#(およびintcol#)で絞り込む部分で発生していたと考えられる。実際は保留統計の場合、savtimeは全て同じ値になっているので、全く絞り込みは効かない。(2)は、I_WRI$_OPTSTAT_HH_OBJ_ICOL_STの索引でobj#とsavtimeで絞り込み、行をsavtime(およびintcol#)で絞り込むため、効率が良い。
根本的な問いは、SQL_ID:5hud5urmn39bxにおいてI_WRI$_OPTSTAT_HH_OBJ_ICOL_ST ではなくI_WRI$_OPTSTAT_HH_ST が利用されていた要因は何か、という点である。10053トレース確認したところ、オプティマイザは両者の索引を比較して、I_WRI$_OPTSTAT_HH_STの方がコストが少ないと判断している。実際のトレースを見てみよう。
****** Costing Index I_WRI$_OPTSTAT_HH_OBJ_ICOL_ST ★a (2)I_WRI$_OPTSTAT_HH_OBJ_ICOL_ST索引のコスト計算(効率的な実行計画)
SPD: Return code in qosdDSDirSetup: NOCTX, estType = INDEX_SCAN
SPD: Return code in qosdDSDirSetup: NOCTX, estType = INDEX_FILTER
ColGroup Usage:: PredCnt: 2 Matches Full: Partial:
Estimated selectivity: 0.005435 , col: #1 →obj#の選択率
Estimated selectivity: 7.3638e-04 , col: #27 →savtime(仮想列)の選択率:7.3638e-04=0.00073
Estimated selectivity: 0.009434 , col: #2 →intcol#の選択率
Access Path: index (RangeScan)
Index: I_WRI$_OPTSTAT_HH_OBJ_ICOL_ST
resc_io: 4.000000 resc_cpu: 57356
ix_sel: 0.005435 ix_sel_with_filters: 3.7755e-08 ★b (2)の索引の検索率(ix_sel)はobj#と同じ
***** Virtual column Adjustment ******
Column name SYS_NC00027$
Adjusted cost_cpu 250
Adjusted cost_io 0.000000
***** End virtual column Adjustment ******
Cost: 4.004604 Resp: 4.004604 Degree: 1 ★c (2)のコストは4
****** Costing Index I_WRI$_OPTSTAT_HH_ST★d (1)I_WRI$_OPTSTAT_HH_ST索引のコスト計算(非効率な実行計画)
SPD: Return code in qosdDSDirSetup: NOCTX, estType = INDEX_SCAN
SPD: Return code in qosdDSDirSetup: NOCTX, estType = INDEX_FILTER
Estimated selectivity: 7.3638e-04 , col: #27 →savtime(仮想列)の選択率
Access Path: index (AllEqRange)
Index: I_WRI$_OPTSTAT_HH_ST
resc_io: 2.000000 resc_cpu: 29484
ix_sel: 7.3638e-04 ix_sel_with_filters: 7.3638e-04 ★e (1)の索引の検索率(ix_sel)はsavtime
Cost: 2.001352 Resp: 2.001352 Degree: 1
Best:: AccessPath: IndexRange ★f (1)の方が良い(いままでのうちベスト)と判定している
Index: I_WRI$_OPTSTAT_HH_ST
Cost: 2.001352 Degree: 1 Resp: 2.001352 Card: 0.000983 Bytes: 0.000000 ★g (1)の索引の実行計画を選定
オプティマイザは★aでI_WRI$_OPTSTAT_HH_OBJ_ICOL_STのコスト計算を開始している。★bで索引の選択率を0.005435と推定し、★cでコストを4と推定している。その後、★dでI_WRI$_OPTSTAT_HH_STのコスト計算を開始し、★eで索引の選択率を7.3638e-04=0.00073と推定し、コストを2.001352と推定している。以上の結果から★fでI_WRI$_OPTSTAT_HH_STの方がコストが低いため、★gでこの索引を使う実行計画(非効率な実行計画)を選択している。問題は★eの部分において、保留統計の場合はsavtimeが全て同じ値になってしまう点が考慮されていないことではないかと感じている。col#27のヒストグラムが取得されており、バインドピークが有効になっていれば、適切な実行計画が選択されるかもしれない、という期待はあるが、本環境ではバインドピークは無効化しているため、そこまでの確認は行っていない。
5.まとめ
本稿では、統計情報履歴削除のdelete文(5hud5urmn39bx)遅延の原因と対処方法について記載した。これは過去に保留統計でヒストグラムの統計履歴削除で遅延した事象(参考[1])と類似事象である。今回はヒストグラム統計は取得しない設定にしていたため、この問題には該当しなかった。
本件をサポートに問い合わせたところ、対処方法についてはSQLパッチが妥当とのことであった。改善要望として、当該回避方法を公開ドキュメント化していただけるようなので、そのうち、公になるかもしれない。
保留統計を使って、マルチテナントでPDBを多く抱えているようなDBでは、このCPU高騰の事象が顕在化しやすいので留意した方が良いかもしれない。
参考
[1]保留統計との闘い~統計取得遅延問題
[2]WRI$_OPTSTAT_HISTHEAD_HISTORYの構成情報
・表・パーティション構成
SQL> select internal_column_id, column_name, nullable, data_type, virtual_column from user_tab_cols where table_name='WRI$_OPTSTAT_HISTHEAD_HISTORY' order by 1;
INTERNAL_COLUMN_ID COLUMN_NAME N DATA_TYPE VIR
------------------ -------------------- - ------------------------------ ---
1 OBJ# N NUMBER NO
2 INTCOL# N NUMBER NO
3 SAVTIME Y TIMESTAMP(6) WITH TIME ZONE NO
4 FLAGS Y NUMBER NO
5 NULL_CNT Y NUMBER NO
6 MINIMUM Y NUMBER NO
7 MAXIMUM Y NUMBER NO
8 DISTCNT Y NUMBER NO
9 DENSITY Y NUMBER NO
10 LOWVAL Y RAW NO
11 HIVAL Y RAW NO
12 AVGCLN Y NUMBER NO
13 SAMPLE_DISTCNT Y NUMBER NO
14 SAMPLE_SIZE Y NUMBER NO
15 TIMESTAMP# Y DATE NO
16 EXPRESSION Y CLOB NO
17 COLNAME Y VARCHAR2 NO
18 SAVTIME_DATE Y DATE YES
19 SPARE1 Y NUMBER NO
20 SPARE2 Y NUMBER NO
21 SPARE3 Y NUMBER NO
22 SPARE4 Y VARCHAR2 NO
23 SPARE5 Y VARCHAR2 NO
24 SPARE6 Y TIMESTAMP(6) WITH TIME ZONE NO
25 MINIMUM_ENC Y RAW NO
26 MAXIMUM_ENC Y RAW NO
27 SYS_NC00027$ Y TIMESTAMP(6) YES
SQL> select partition_name, high_value from user_tab_partitions where table_name='WRI$_OPTSTAT_HISTHEAD_HISTORY';
PARTITION_NAME HIGH_VALUE
---------------- --------------------------------------------------------------------------------
P_PERMANENT TO_DATE(' 1900-01-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIA
SYS_P1907 TO_DATE(' 2024-01-25 00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIA
SYS_P1922 TO_DATE(' 2024-01-27 00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIA
SYS_P1931 TO_DATE(' 2024-01-28 00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIA
SYS_P1942 TO_DATE(' 2024-01-29 00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIA
・索引の構成
SQL> select index_name, column_name from user_ind_columns where table_name='WRI$_OPTSTAT_HISTHEAD_HISTORY' order by index_name, column_position;
INDEX_NAME COLUMN_NAME
------------------------------ ------------------------------
I_WRI$_OPTSTAT_HH_OBJ_ICOL_ST OBJ#
I_WRI$_OPTSTAT_HH_OBJ_ICOL_ST INTCOL#
I_WRI$_OPTSTAT_HH_OBJ_ICOL_ST SYS_NC00027$
I_WRI$_OPTSTAT_HH_OBJ_ICOL_ST COLNAME
I_WRI$_OPTSTAT_HH_ST SYS_NC00027$
SQL> select index_name, column_position, column_expression from user_ind_expressions where table_name='WRI$_OPTSTAT_HISTHEAD_HISTORY';
INDEX_NAME COLUMN_POSITION COLUMN_EXPRESSION
------------------------------ --------------- --------------------------------------------------------------------------------
I_WRI$_OPTSTAT_HH_OBJ_ICOL_ST 3 SYS_EXTRACT_UTC("SAVTIME")
I_WRI$_OPTSTAT_HH_ST 1 SYS_EXTRACT_UTC("SAVTIME")
以上
2024-01-28 20:46
保留統計の索引統計0件問題について [アーキテクチャ]
今までかかわっていたプロジェクトが一段落して離れることとなり少し落ち着いた時間が取れたので、先日コミュニティに投稿した、保留統計でgather_table_statsで索引の統計情報を取得すると、索引の統計がnum_rows=0となってしまうことがある、という事象について、ここで紹介しておきたい。
gather_table_stats doesn't gather related index stats properly when pending stats are enabled
事象の詳細や再現方法については上記を見て頂きたいが、簡単に言えば、保留統計を使っている表に対してgather_table_statsで表と一緒に索引の統計情報を取得するとき(カスケードオプション有効)、ある条件を満たすと索引の統計が適切に取得できない、より具体的には表の件数が有件なのに、索引の統計(num_rows)が0になってしまうのである。これが発生するのは表の(パブリッシュされた)統計(num_rows)が0で、保留統計を使っており、gather_table_statsでカスケードオプション有効にした場合に発生する。上記投稿で示したテストケースは19.3である。
この事象は新規不具合のため修正されるまではしばらく時間がかかる(一般的には21cまたは22cに取り込まれ、旧バージョンへバックポートされる流れになる)と思われる。このため、この事象を回避するワークアラウンドの確立が課題である。上記投稿ではパブリッシュ前にそのような問題を含んでいる可能性のある索引を抽出する方法について記載したが、実運用上この問題の影響と対処方法について少し補足しておきたい。
まず統計情報取得するシーンとして大きく2つあると考えている。1つは自動統計情報収集、これはOracleの一般的な統計情報取得方法であり、メンテナンスウィンドウに設定された時間帯に統計情報が古くなった表を選定(デフォルトでは更新が10%以上)し、統計情報を取得するケースである。システムが運用されている状態では、この方法で統計情報を取得していることがほとんどであろう。この問題の特性から有件の表に対しては統計情報取得に問題がないことは明らかであろう。あるとすれば、有件→0件→有件を繰り返すケースであろうが、そもそもそのようなテンポラリ表のような使い方のテーブルであれば、統計情報の状態を自動統計に任せること自体問題となる可能性があるので、統計ロックすることを検討するだろう。
もう一つのシーンは手動での統計情報収集である。これは、運用開始前のデータ移行や、リリースに伴う新規表の作成の際に、統計情報を適切な状態にするためにDBAが手動で統計情報を取得するケースである。この統計情報をどのような状態にすべきかは状況によって異なるだろうが、概ね初期データ投入後の状態で取得するか、あるいは空の状態としておき、何等かの契機でデータが投入された後を狙って手動で取得するといったケースが考えられる。いずれのケースにおいても、保留統計を使う場合は注意が必要である。空の状態で統計情報取得・パブリッシュして0件統計の状態を作ってしまうと、有件になったときの統計情報取得でこの事象の影響で意図せず索引統計が0となり、実行計画が適切でなくなるリスクがある。回避するには、0件統計をとらない、つまり0件の場合はあえてNULL統計にしておく、そして有件になった適切なタイミングで統計情報を取得することが一番簡易な対処である。ただ、0件の状態で統計情報を取得するなら、その後の統計情報取得では、必ず索引の統計情報が適切に取得できているかをパブリッシュ前に確認し、必要であれば、索引統計を再取得する、という運用を徹底することである。
索引のnum_rowsが0となってしまう弊害は、主に実行計画が適切でないことに伴う性能遅延に尽きる。ある表に複数の索引がある場合に、索引のnum_rowsが0であった場合、問い合わせのプレディケートに合致する索引が複数あった場合にコストが適切に算出できず、適切な索引が選択されない可能性がある。実際に、このような事象に遭遇した経験から、統計情報を手動取得する場合は、上記投稿にあるチェックSQLを実行し、索引統計に問題ないことを確認する運用を、少なくとも製品不具合が解消されるまでは徹底することが必要だと考える。手間としてはわずかであるが、このひと手間で後続の性能遅延のリスクを低減できるなら、これは十分実施検討するに値すると考える。
なお、コミュニティのSureshさんからは古い19cでは不具合多いよね、とのコメントを頂いたが、21cでも再現することが確認できたと聞いているので、おそらくこの事象は最新の19cでも修正されていないはずである。私の手元のテスト環境をそろそろ最新にバージョンアップさせなければと思う今日この頃である。Jonathan Lewisさんからの「いいね」が心の支えになっていることは言うまでもない。
以上
gather_table_stats doesn't gather related index stats properly when pending stats are enabled
事象の詳細や再現方法については上記を見て頂きたいが、簡単に言えば、保留統計を使っている表に対してgather_table_statsで表と一緒に索引の統計情報を取得するとき(カスケードオプション有効)、ある条件を満たすと索引の統計が適切に取得できない、より具体的には表の件数が有件なのに、索引の統計(num_rows)が0になってしまうのである。これが発生するのは表の(パブリッシュされた)統計(num_rows)が0で、保留統計を使っており、gather_table_statsでカスケードオプション有効にした場合に発生する。上記投稿で示したテストケースは19.3である。
この事象は新規不具合のため修正されるまではしばらく時間がかかる(一般的には21cまたは22cに取り込まれ、旧バージョンへバックポートされる流れになる)と思われる。このため、この事象を回避するワークアラウンドの確立が課題である。上記投稿ではパブリッシュ前にそのような問題を含んでいる可能性のある索引を抽出する方法について記載したが、実運用上この問題の影響と対処方法について少し補足しておきたい。
まず統計情報取得するシーンとして大きく2つあると考えている。1つは自動統計情報収集、これはOracleの一般的な統計情報取得方法であり、メンテナンスウィンドウに設定された時間帯に統計情報が古くなった表を選定(デフォルトでは更新が10%以上)し、統計情報を取得するケースである。システムが運用されている状態では、この方法で統計情報を取得していることがほとんどであろう。この問題の特性から有件の表に対しては統計情報取得に問題がないことは明らかであろう。あるとすれば、有件→0件→有件を繰り返すケースであろうが、そもそもそのようなテンポラリ表のような使い方のテーブルであれば、統計情報の状態を自動統計に任せること自体問題となる可能性があるので、統計ロックすることを検討するだろう。
もう一つのシーンは手動での統計情報収集である。これは、運用開始前のデータ移行や、リリースに伴う新規表の作成の際に、統計情報を適切な状態にするためにDBAが手動で統計情報を取得するケースである。この統計情報をどのような状態にすべきかは状況によって異なるだろうが、概ね初期データ投入後の状態で取得するか、あるいは空の状態としておき、何等かの契機でデータが投入された後を狙って手動で取得するといったケースが考えられる。いずれのケースにおいても、保留統計を使う場合は注意が必要である。空の状態で統計情報取得・パブリッシュして0件統計の状態を作ってしまうと、有件になったときの統計情報取得でこの事象の影響で意図せず索引統計が0となり、実行計画が適切でなくなるリスクがある。回避するには、0件統計をとらない、つまり0件の場合はあえてNULL統計にしておく、そして有件になった適切なタイミングで統計情報を取得することが一番簡易な対処である。ただ、0件の状態で統計情報を取得するなら、その後の統計情報取得では、必ず索引の統計情報が適切に取得できているかをパブリッシュ前に確認し、必要であれば、索引統計を再取得する、という運用を徹底することである。
索引のnum_rowsが0となってしまう弊害は、主に実行計画が適切でないことに伴う性能遅延に尽きる。ある表に複数の索引がある場合に、索引のnum_rowsが0であった場合、問い合わせのプレディケートに合致する索引が複数あった場合にコストが適切に算出できず、適切な索引が選択されない可能性がある。実際に、このような事象に遭遇した経験から、統計情報を手動取得する場合は、上記投稿にあるチェックSQLを実行し、索引統計に問題ないことを確認する運用を、少なくとも製品不具合が解消されるまでは徹底することが必要だと考える。手間としてはわずかであるが、このひと手間で後続の性能遅延のリスクを低減できるなら、これは十分実施検討するに値すると考える。
なお、コミュニティのSureshさんからは古い19cでは不具合多いよね、とのコメントを頂いたが、21cでも再現することが確認できたと聞いているので、おそらくこの事象は最新の19cでも修正されていないはずである。私の手元のテスト環境をそろそろ最新にバージョンアップさせなければと思う今日この頃である。Jonathan Lewisさんからの「いいね」が心の支えになっていることは言うまでもない。
以上
2021-07-01 01:02
保留統計との闘い~統計取得遅延問題 [アーキテクチャ]
久しぶりの投稿である。保留統計が蓄積すると、統計取得が遅延する問題について調査したことを記録しておく。手元の検証環境(19.3)で動作確認をした。
まず簡単に保留統計について記載しておく。Oracle12cから統計情報は取得したタイミングで即時反映するのではなく、一時的に保留状態にしておき、任意のタイミングで反映(パブリッシュ)することができる。保留統計で取得された実行計画を参照するようにセッションレベルで統計を切り替えることができるため、explain plan for等で実行計画を反映前に事前に確認することができる。これにより、統計情報取得によって突然実行計画が変わり性能劣化を招くような事態を未然に防ぐことができる。
保留統計の設定は以下の例のように表毎にプリファレンスで行う(スキーマレベルでプリファレンスを設定することも可能ではあるが、そのときにスキーマに存在するオブジェクトにしか影響しないため、注意が必要である)。
例)テーブルの保留統計の設定方法
保留統計を取得するには、通常の統計取得方法と変わらずdbms_stats.gather_table/index_statsを利用する。保留統計が取得されるとdba_tab_pending_statsやdba_ind_pending_statsで統計情報を確認することができる。この時点ではあくまで保留状態であるので、統計情報は変更されておらず、実行計画への影響はない。
例)テーブル・索引の保留統計の状態
保留統計に取得された統計で実行計画を確認するためには、以下のようにセッションレベルでoptimizer_use_pending_statisticsをtrueに設定すれば良い。下記例は、scott.t1を10000件にした状態の保留統計ではインデックスを使う実行計画になっていることがわかる。
例)
実行計画に問題がないことを確認したら、保留統計を以下のようにパブリッシュし、通常の統計情報へ反映する。反映されれば保留統計はなくなる。パブリッシュは表にだけ実行でき、紐づく索引は同時にパブリッシュされる。索引のみパブリッシュすることはできない。
例)
保留統計の削除はdbms_stats.delete_pending_statsを使う。検証用以外で実運用上は使うことは少ないと思うが、例えば保留に古い統計情報が残ってしまったときに有用だろう。
例)
保留統計をあまりため込むと、統計取得に伴う過去保留統計(ヒストグラム)の削除処理に時間がかかり、統計取得が遅延することがある。ヒストグラムの保留統計はオブジェクト毎・カラム毎に取得されるため、テーブル数(パーティション数)xカラム数が多いと、保留統計が蓄積した際に遅延することがある。これは下記DocIDに記載されている通り仕様であり、保留統計はため込まないことが推奨されている。製品機能として運用の制約は規定していないものの、感覚としては、メンテナンスウィンドウで日次に取得された保留統計は、何カ月もため込むものではなく、取得したその日のうちにパブリッシュし、保留統計はなるべく空としておく程度が良い。
When Number of Pending Statistics Increases, It Takes Time to Collect Statistical Information (ドキュメントID 2642768.1)
上記の仕様は理解したとしても、実際に保留統計が蓄積してしまうケースはあるだろう。この保留統計の削除処理に伴う上記DocのDELETE文に時間がかかるのは実行計画の問題である。問題のdelete文と実行計画を見てほしい。I_WRI$_OPTSTAT_H_STを使ってWRI$_OPTSTAT_HISTGRM_HISTORYの絞り込みを行っている。
この索引はタイムスタンプ型SAVTIMEカラムのファンクション索引(SYS_EXTRACT_UTC("SAVTIME"))である。SAVTIMEがほぼユニークに絞り込める状況では効率的であるが、逆に同じ値が大量に入っている場合は非効率である。
このテーブルの索引には、I_WRI$_OPTSTAT_H_OBJ#_ICOL#_STという別の索引があることがわかる。OBJ#で絞り込みができる場合はこちらの方が良い。
この表は、もともとヒストグラムのバックアップを保持している表で、SAVTIMEはバックアップ日時が入る。しかし、保留統計の場合は、テーブル毎、カラム毎にSAVTIME=3000年12月1日で記録される。様々な表のヒストグラムが全く同じSAVTIMEで記録されるため、ある表の保留統計のレコードを識別するためにSAVTIMEでは絞り込めない。このため、表の数(厳密にはヒストグラムが取得されているカラム数)が増えてくると、保留統計取得に伴う過去ヒストグラムの削除に時間がかかるようになるのである。
以下の例では3つの表の保留統計を取得した例であるが、表ごとに153件のヒストグラムが取得されており、すべて同じSAVTIMEである。1回の統計取得でこのdeleteが5回発行されているのは、表のカラム数に依存しているのだろう。仮にこの表が1000個あると、統計情報収集で15万件程度の規模の表をINDEX FULL SCANで5回走査する処理になるだろう。
なお、パブリッシュでもこのdeleteは発行されるが、表毎に1回しか発行されていなかった。特にカラムを絞り込むことなく削除できるからだろう。
このdelete文はdbms_statsパッケージ内から発行されているSQLなのでヒント追加などで実行計画を変更できない。基本的にはパブリッシュすれば遅延は発生しないはずである。しかし、保留統計を使えば統計が蓄積されてしまうことは運用上発生し得るし、保留統計取得に時間がかかり困ることもあるだろう。
この問題の解決策をいろいろと考えたが、今のところ一番簡単で有効と思われるのは以下のようなSQLパッチを適用することである。SQLパッチは任意のSQLIDにヒントを入れることができる機能であり、19cではdbms_sqldiag.create_sql_patchとしてマニュアルに記載されている機能である。インスタンス再起動により揮発することはない。なお、下記SQLIDは19.3の結果であり、バージョンによりSQLIDは変わる可能性がある点はご留意頂きたい。保留統計取得が遅く、このSQLで時間がかかっている場合には試してみると良いだろう。
保留統計性能改善用SQLパッチ(19c)
以下は実際に手元の環境でこのSQLパッチを適用した後の実行計画である。HINTに指定した通り、I_WRI$_OPTSTAT_H_OBJ#_ICOL#_STの索引が使われており、かつNoteセクションにSQL patch "pend_del_patch" used for this statementとSQLパッチが使われていることがわかる。この実行計画ならOBJ#で絞り込めるため、いくら保留統計が蓄積したとしても遅延が発生することはないだろう。なお、このSQLパッチを削除するには、dbms_sqldiag.drop_sql_patch('pend_del_patch')を使えば良い。
本稿では保留統計の基本的操作方法のまとめと、保留統計取得遅延問題について記載した。保留統計遅延問題の本質を要約すると以下3点である。
・保留統計は蓄積するとヒストグラム削除で時間がかかることがある(仕様)
・上記遅延を解消するには適切にパブリッシュし保留統計を蓄積しない運用を心がけること
・どうしても遅延解消したい場合は、SQLパッチでチューニングは可能(自己責任)
以上
◆保留統計についてのおさらい
まず簡単に保留統計について記載しておく。Oracle12cから統計情報は取得したタイミングで即時反映するのではなく、一時的に保留状態にしておき、任意のタイミングで反映(パブリッシュ)することができる。保留統計で取得された実行計画を参照するようにセッションレベルで統計を切り替えることができるため、explain plan for等で実行計画を反映前に事前に確認することができる。これにより、統計情報取得によって突然実行計画が変わり性能劣化を招くような事態を未然に防ぐことができる。
保留統計の設定は以下の例のように表毎にプリファレンスで行う(スキーマレベルでプリファレンスを設定することも可能ではあるが、そのときにスキーマに存在するオブジェクトにしか影響しないため、注意が必要である)。
例)テーブルの保留統計の設定方法
SQL> exec dbms_stats.set_table_prefs('SCOTT','T1','PUBLISH','FALSE');
PL/SQL procedure successfully completed.
SQL> select dbms_stats.get_prefs('PUBLISH','SCOTT','T1') from dual;
DBMS_STATS.GET_PREFS('PUBLISH','SCOTT','T1')
--------------------------------------------
FALSE
保留統計を取得するには、通常の統計取得方法と変わらずdbms_stats.gather_table/index_statsを利用する。保留統計が取得されるとdba_tab_pending_statsやdba_ind_pending_statsで統計情報を確認することができる。この時点ではあくまで保留状態であるので、統計情報は変更されておらず、実行計画への影響はない。
例)テーブル・索引の保留統計の状態
SQL> exec dbms_stats.gather_table_stats('SCOTT','T1');
PL/SQL procedure successfully completed.
SQL> --- published statistics
SQL> select num_rows, last_analyzed from dba_tab_statistics where owner='SCOTT' and table_name='T1';
NUM_ROWS LAST_ANALYZED
---------- -------------------
1000 2021/06/20 10:14:50
SQL> select index_name, num_rows, last_analyzed from dba_ind_statistics where owner='SCOTT' and table_name='T1';
INDEX_NAME NUM_ROWS LAST_ANALYZED
---------- ---------- -------------------
T1_PK 1000 2021/06/20 10:14:50
T1_IDX1 1000 2021/06/20 10:14:50
T1_IDX2 1000 2021/06/20 10:14:50
SQL> -- pending statistics
SQL> select num_rows, last_analyzed from dba_tab_pending_stats where owner='SCOTT' and table_name='T1';
NUM_ROWS LAST_ANALYZED
---------- -------------------
10000 2021/06/20 10:14:55
SQL> select index_name, num_rows, last_analyzed from dba_ind_pending_stats where owner='SCOTT' and table_name='T1';
INDEX_NAME NUM_ROWS LAST_ANALYZED
---------- ---------- -------------------
T1_IDX1 10000 2021/06/20 10:14:55
T1_IDX2 10000 2021/06/20 10:14:56
T1_PK 10000 2021/06/20 10:14:55
保留統計に取得された統計で実行計画を確認するためには、以下のようにセッションレベルでoptimizer_use_pending_statisticsをtrueに設定すれば良い。下記例は、scott.t1を10000件にした状態の保留統計ではインデックスを使う実行計画になっていることがわかる。
例)
SQL> alter session set optimizer_use_pending_statistics=true;
Session altered.
SQL> explain plan for select * from scott.t1 where id<1000;
Explained.
SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
---------------------------------------------------------------------------------------------
Plan hash value: 1715750954
---------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 999 | 303K| 48 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| T1 | 999 | 303K| 48 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | T1_PK | 999 | | 3 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("ID"<1000)
実行計画に問題がないことを確認したら、保留統計を以下のようにパブリッシュし、通常の統計情報へ反映する。反映されれば保留統計はなくなる。パブリッシュは表にだけ実行でき、紐づく索引は同時にパブリッシュされる。索引のみパブリッシュすることはできない。
例)
SQL> exec dbms_stats.publish_pending_stats('SCOTT','T1');
PL/SQL procedure successfully completed.
SQL> --- published statistics
SQL> select num_rows, last_analyzed from dba_tab_statistics where owner='SCOTT' and table_name='T1';
NUM_ROWS LAST_ANALYZED
---------- -------------------
10000 2021/06/20 10:14:55
SQL> select index_name, num_rows, last_analyzed from dba_ind_statistics where owner='SCOTT' and table_name='T1';
INDEX_NAME NUM_ROWS LAST_ANALYZED
---------- ---------- -------------------
T1_PK 10000 2021/06/20 10:14:55
T1_IDX1 10000 2021/06/20 10:14:55
T1_IDX2 10000 2021/06/20 10:14:56
SQL> -- pending statistics
SQL> select num_rows, last_analyzed from dba_tab_pending_stats where owner='SCOTT' and table_name='T1';
no rows selected
SQL> select index_name, num_rows, last_analyzed from dba_ind_pending_stats where owner='SCOTT' and table_name='T1';
no rows selected
保留統計の削除はdbms_stats.delete_pending_statsを使う。検証用以外で実運用上は使うことは少ないと思うが、例えば保留に古い統計情報が残ってしまったときに有用だろう。
例)
SQL> exec dbms_stats.delete_pending_stats('SCOTT','T1');
PL/SQL procedure successfully completed.
◆保留統計取得遅延問題について
保留統計をあまりため込むと、統計取得に伴う過去保留統計(ヒストグラム)の削除処理に時間がかかり、統計取得が遅延することがある。ヒストグラムの保留統計はオブジェクト毎・カラム毎に取得されるため、テーブル数(パーティション数)xカラム数が多いと、保留統計が蓄積した際に遅延することがある。これは下記DocIDに記載されている通り仕様であり、保留統計はため込まないことが推奨されている。製品機能として運用の制約は規定していないものの、感覚としては、メンテナンスウィンドウで日次に取得された保留統計は、何カ月もため込むものではなく、取得したその日のうちにパブリッシュし、保留統計はなるべく空としておく程度が良い。
When Number of Pending Statistics Increases, It Takes Time to Collect Statistical Information (ドキュメントID 2642768.1)
上記の仕様は理解したとしても、実際に保留統計が蓄積してしまうケースはあるだろう。この保留統計の削除処理に伴う上記DocのDELETE文に時間がかかるのは実行計画の問題である。問題のdelete文と実行計画を見てほしい。I_WRI$_OPTSTAT_H_STを使ってWRI$_OPTSTAT_HISTGRM_HISTORYの絞り込みを行っている。
SQL> select * from table(dbms_xplan.display_cursor('d8yp8608d866z'));
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
SQL_ID d8yp8608d866z, child number 0
-------------------------------------
delete /* QOSH:PURGE_OLD_STS *//*+ dynamic_sampling(4) */ from
sys.wri$_optstat_histgrm_history where :1 = savtime and obj# = :2
and intcol# = nvl(:3, intcol#)
Plan hash value: 1890550155
--------------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop |
--------------------------------------------------------------------------------------------------------------------------------------------
| 0 | DELETE STATEMENT | | | | 2 (100)| | | |
| 1 | DELETE | WRI$_OPTSTAT_HISTGRM_HISTORY | | | | | | |
|* 2 | TABLE ACCESS BY GLOBAL INDEX ROWID BATCHED| WRI$_OPTSTAT_HISTGRM_HISTORY | 1 | 56 | 2 (0)| 00:00:01 | ROWID | ROWID |
|* 3 | INDEX RANGE SCAN | I_WRI$_OPTSTAT_H_ST★ | 3 | | 1 (0)| 00:00:01 | | |
--------------------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter(("OBJ#"=:2 AND "INTCOL#"=NVL(:3,"INTCOL#")))
3 - access("WRI$_OPTSTAT_HISTGRM_HISTORY"."SYS_NC00018$"=SYS_EXTRACT_UTC(:1))
この索引はタイムスタンプ型SAVTIMEカラムのファンクション索引(SYS_EXTRACT_UTC("SAVTIME"))である。SAVTIMEがほぼユニークに絞り込める状況では効率的であるが、逆に同じ値が大量に入っている場合は非効率である。
SQL> select * from dba_ind_expressions where table_name='WRI$_OPTSTAT_HISTGRM_HISTORY'
INDEX_OWNE INDEX_NAME TABLE_OWNE TABLE_NAME COLUMN_EXPRESSION COLUMN_POSITION
---------- ------------------------------ ---------- ------------------------------ --------------------------- ---------------
SYS I_WRI$_OPTSTAT_H_OBJ#_ICOL#_ST SYS WRI$_OPTSTAT_HISTGRM_HISTORY SYS_EXTRACT_UTC("SAVTIME") 3
SYS I_WRI$_OPTSTAT_H_ST SYS WRI$_OPTSTAT_HISTGRM_HISTORY SYS_EXTRACT_UTC("SAVTIME")★ 1
このテーブルの索引には、I_WRI$_OPTSTAT_H_OBJ#_ICOL#_STという別の索引があることがわかる。OBJ#で絞り込みができる場合はこちらの方が良い。
SQL> select index_name, column_name from dba_ind_columns where table_name='WRI$_OPTSTAT_HISTGRM_HISTORY' order by index_name,column_position INDEX_NAME COLUMN_NAME ----------------------------------- -------------------- I_WRI$_OPTSTAT_H_OBJ#_ICOL#_ST OBJ#★ I_WRI$_OPTSTAT_H_OBJ#_ICOL#_ST INTCOL# I_WRI$_OPTSTAT_H_OBJ#_ICOL#_ST SYS_NC00018$ I_WRI$_OPTSTAT_H_OBJ#_ICOL#_ST COLNAME I_WRI$_OPTSTAT_H_ST SYS_NC00018$
この表は、もともとヒストグラムのバックアップを保持している表で、SAVTIMEはバックアップ日時が入る。しかし、保留統計の場合は、テーブル毎、カラム毎にSAVTIME=3000年12月1日で記録される。様々な表のヒストグラムが全く同じSAVTIMEで記録されるため、ある表の保留統計のレコードを識別するためにSAVTIMEでは絞り込めない。このため、表の数(厳密にはヒストグラムが取得されているカラム数)が増えてくると、保留統計取得に伴う過去ヒストグラムの削除に時間がかかるようになるのである。
以下の例では3つの表の保留統計を取得した例であるが、表ごとに153件のヒストグラムが取得されており、すべて同じSAVTIMEである。1回の統計取得でこのdeleteが5回発行されているのは、表のカラム数に依存しているのだろう。仮にこの表が1000個あると、統計情報収集で15万件程度の規模の表をINDEX FULL SCANで5回走査する処理になるだろう。
SQL> exec dbms_stats.gather_table_stats('SCOTT','T1',method_opt=>'for all columns');
PL/SQL procedure successfully completed.
SQL> select to_char(savtime,'yyyymmdd hh24:mi:ss'), count(*) from WRI$_OPTSTAT_HISTGRM_HISTORY group by savtime order by 1;
TO_CHAR(SAVTIME,' COUNT(*)
----------------- ----------
30001201 01:00:00 153
SQL> select executions from v$sqlarea where sql_id='d8yp8608d866z';
EXECUTIONS
----------
5
SQL> exec dbms_stats.gather_table_stats('SCOTT','T2',method_opt=>'for all columns');
PL/SQL procedure successfully completed.
SQL> select to_char(savtime,'yyyymmdd hh24:mi:ss'), count(*) from WRI$_OPTSTAT_HISTGRM_HISTORY group by savtime order by 1;
TO_CHAR(SAVTIME,' COUNT(*)
----------------- ----------
30001201 01:00:00 306
SQL> select executions from v$sqlarea where sql_id='d8yp8608d866z';
EXECUTIONS
----------
10
SQL> exec dbms_stats.gather_table_stats('SCOTT','T3',method_opt=>'for all columns');
PL/SQL procedure successfully completed.
SQL> select to_char(savtime,'yyyymmdd hh24:mi:ss'), count(*) from WRI$_OPTSTAT_HISTGRM_HISTORY group by savtime order by 1;
TO_CHAR(SAVTIME,' COUNT(*)
----------------- ----------
30001201 01:00:00 459
SQL> select executions from v$sqlarea where sql_id='d8yp8608d866z';
EXECUTIONS
----------
15
なお、パブリッシュでもこのdeleteは発行されるが、表毎に1回しか発行されていなかった。特にカラムを絞り込むことなく削除できるからだろう。
SQL> exec dbms_stats.publish_pending_stats('SCOTT','T1');
select executions from v$sqlarea where sql_id='d8yp8608d866z';
PL/SQL procedure successfully completed.
SQL>
EXECUTIONS
----------
16
SQL> exec dbms_stats.publish_pending_stats('SCOTT','T2');
PL/SQL procedure successfully completed.
SQL> select executions from v$sqlarea where sql_id='d8yp8608d866z';
EXECUTIONS
----------
17
SQL> exec dbms_stats.publish_pending_stats('SCOTT','T3');
PL/SQL procedure successfully completed.
SQL> select executions from v$sqlarea where sql_id='d8yp8608d866z';
EXECUTIONS
----------
18
SQL> select to_char(savtime,'yyyymmdd hh24:mi:ss'), count(*) from WRI$_OPTSTAT_HISTGRM_HISTORY group by savtime order by 1;
TO_CHAR(SAVTIME,' COUNT(*)
----------------- ----------
20210622 06:23:55 153
20210622 06:23:55 153
20210622 06:23:57 153
SQL>
このdelete文はdbms_statsパッケージ内から発行されているSQLなのでヒント追加などで実行計画を変更できない。基本的にはパブリッシュすれば遅延は発生しないはずである。しかし、保留統計を使えば統計が蓄積されてしまうことは運用上発生し得るし、保留統計取得に時間がかかり困ることもあるだろう。
この問題の解決策をいろいろと考えたが、今のところ一番簡単で有効と思われるのは以下のようなSQLパッチを適用することである。SQLパッチは任意のSQLIDにヒントを入れることができる機能であり、19cではdbms_sqldiag.create_sql_patchとしてマニュアルに記載されている機能である。インスタンス再起動により揮発することはない。なお、下記SQLIDは19.3の結果であり、バージョンによりSQLIDは変わる可能性がある点はご留意頂きたい。保留統計取得が遅く、このSQLで時間がかかっている場合には試してみると良いだろう。
保留統計性能改善用SQLパッチ(19c)
declare patch_name varchar2(20); begin patch_name := dbms_sqldiag.create_sql_patch( sql_id=>'d8yp8608d866z', hint_text=>'index(@DEL$1 WRI$_OPTSTAT_HISTGRM_HISTORY@DEL$1 I_WRI$_OPTSTAT_H_OBJ#_ICOL#_ST)', name=>'pend_del_patch'); end; /
以下は実際に手元の環境でこのSQLパッチを適用した後の実行計画である。HINTに指定した通り、I_WRI$_OPTSTAT_H_OBJ#_ICOL#_STの索引が使われており、かつNoteセクションにSQL patch "pend_del_patch" used for this statementとSQLパッチが使われていることがわかる。この実行計画ならOBJ#で絞り込めるため、いくら保留統計が蓄積したとしても遅延が発生することはないだろう。なお、このSQLパッチを削除するには、dbms_sqldiag.drop_sql_patch('pend_del_patch')を使えば良い。
SQL> declare
2 patch_name varchar2(20);
3 begin
4 patch_name := dbms_sqldiag.create_sql_patch(
5 sql_id=>'d8yp8608d866z',
6 hint_text=>'index(@DEL$1 WRI$_OPTSTAT_HISTGRM_HISTORY@DEL$1 I_WRI$_OPTSTAT_H_OBJ#_ICOL#_ST)',
7 name=>'pend_del_patch');
8 end;
9 /
PL/SQL procedure successfully completed.
SQL> select name,sql_text, created from dba_sql_patches;
NAME SQL_TEXT CREATED
-------------------- ---------------------------------------- ---------------------------------------------------------------------------
pend_del_patch delete /* QOSH:PURGE_OLD_STS *//*+ dynam 22-JUN-21 06.31.42.940687 AM
ic_sampling(4) */ from sys.wri$_optstat
SQL> exec dbms_stats.publish_pending_stats('SCOTT','T1');
PL/SQL procedure successfully completed.
SQL> select * from table(dbms_xplan.display_cursor('d8yp8608d866z', null, 'ALL ALLSTATS LAST'));
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
SQL_ID d8yp8608d866z, child number 0
-------------------------------------
delete /* QOSH:PURGE_OLD_STS *//*+ dynamic_sampling(4) */ from
sys.wri$_optstat_histgrm_history where :1 = savtime and obj# = :2
and intcol# = nvl(:3, intcol#)
Plan hash value: 1545931696
-----------------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | E-Rows |E-Bytes| Cost (%CPU)| E-Time | Pstart| Pstop |
-----------------------------------------------------------------------------------------------------------------------------------------------
| 0 | DELETE STATEMENT | | | | 8 (100)| | | |
| 1 | DELETE | WRI$_OPTSTAT_HISTGRM_HISTORY | | | | | | |
| 2 | TABLE ACCESS BY GLOBAL INDEX ROWID BATCHED| WRI$_OPTSTAT_HISTGRM_HISTORY | 31 | 1767 | 8 (0)| 00:00:01 | ROWID | ROWID |
|* 3 | INDEX RANGE SCAN | I_WRI$_OPTSTAT_H_OBJ#_ICOL#_ST | 31 | | 6 (0)| 00:00:01 | | |
-----------------------------------------------------------------------------------------------------------------------------------------------
Query Block Name / Object Alias (identified by operation id):
-------------------------------------------------------------
1 - DEL$1
2 - DEL$1 / WRI$_OPTSTAT_HISTGRM_HISTORY@DEL$1
3 - DEL$1 / WRI$_OPTSTAT_HISTGRM_HISTORY@DEL$1
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("OBJ#"=:2 AND "WRI$_OPTSTAT_HISTGRM_HISTORY"."SYS_NC00018$"=SYS_EXTRACT_UTC(:1))
filter(("INTCOL#"=NVL(:3,"INTCOL#") AND "WRI$_OPTSTAT_HISTGRM_HISTORY"."SYS_NC00018$"=SYS_EXTRACT_UTC(:1)))
Column Projection Information (identified by operation id):
-----------------------------------------------------------
2 - (cmp=2,3,4; cpy=5) "WRI$_OPTSTAT_HISTGRM_HISTORY".ROWID[ROWID,10], "OBJ#"[NUMBER,22], "INTCOL#"[NUMBER,22], "SAVTIME"[TIMESTAMP
WITH TIME ZONE,13], "WRI$_OPTSTAT_HISTGRM_HISTORY"."COLNAME"[VARCHAR2,128], "WRI$_OPTSTAT_HISTGRM_HISTORY"."SYS_NC00018$"[TIMESTAMP,11]
3 - "WRI$_OPTSTAT_HISTGRM_HISTORY".ROWID[ROWID,10], "OBJ#"[NUMBER,22], "INTCOL#"[NUMBER,22],
"WRI$_OPTSTAT_HISTGRM_HISTORY"."SYS_NC00018$"[TIMESTAMP,11], "WRI$_OPTSTAT_HISTGRM_HISTORY"."COLNAME"[VARCHAR2,128]
Hint Report (identified by operation id / Query Block Name / Object Alias):
Total hints for statement: 2
---------------------------------------------------------------------------
1 - DEL$1
- dynamic_sampling(4)
2 - DEL$1 / WRI$_OPTSTAT_HISTGRM_HISTORY@DEL$1
- index(@DEL$1 WRI$_OPTSTAT_HISTGRM_HISTORY@DEL$1 I_WRI$_OPTSTAT_H_OBJ#_ICOL#_ST)
Note
-----
- SQL patch "pend_del_patch" used for this statement
- Warning: basic plan statistics not available. These are only collected when:
* hint 'gather_plan_statistics' is used for the statement or
* parameter 'statistics_level' is set to 'ALL', at session or system level
◆まとめ
本稿では保留統計の基本的操作方法のまとめと、保留統計取得遅延問題について記載した。保留統計遅延問題の本質を要約すると以下3点である。
・保留統計は蓄積するとヒストグラム削除で時間がかかることがある(仕様)
・上記遅延を解消するには適切にパブリッシュし保留統計を蓄積しない運用を心がけること
・どうしても遅延解消したい場合は、SQLパッチでチューニングは可能(自己責任)
以上
2021-06-22 08:27
ブロックチェンジトラッキングでDB遅延発生 [アーキテクチャ]
今年のお正月はStay Homeで家でゆっくりするかと思っていたら、夜に電話がかかってきてそのまま出社、翌朝までに何とか収束できたのは良かったものの、とても平和なお正月とは言えなかった。このときは収束に向けてに集中していたので全く考える余裕はなかったが、振り返ってそもそも何故平和なお正月を過ごせなかったのかを考えると、結局一つの結論、つまりlarge_pool_sizeに値を設定せず自動チューニングに任せていたのが敗因だったのではないか、という考えに至った。ということで、今年初の投稿は、年始早々対応したこのトラブルの備忘である。
ブロックチェンジトラッキング(BCT)とは、RMANの高速増分バックアップを取得する際に、どのブロックが前回バックアップから更新されたかを記録する仕組みである。この機能により、RMANは更新されたブロックだけを読み込み、バックアップを取得することができるため、バックアップ時間を短縮するために一般的に使われている機能である。
しかし、バックアップを取得することで、業務のSQL(フォアグラウンドプロセス)に遅延を発生させ得ることがあるのだろうか。alertログに出ていたpublic DBA bufferが不足したメッセージがあることから、少なくともRMANバックアップが引き金となりこのメモリ領域が枯渇し、それによりCKPTに待機が発生し、そこから業務に遅延が波及した可能性はあると考えた。また、状況からDBインスタンス再起動後の初めてのRMANバックアップであったことから、public DBA bufferが不足した原因はDBインスタンス再起動と何等かの関連があるのではないか、という仮説は立てられた。
その後、サポートと解析を進めたところ、少しずつブロックチェンジトラッキングの仕組みが分かってきた。Oracle Ace DirectorのAlexander Gorbachev氏の記事(参考1)の関連部分を要約すると概ね以下のような内容である(原文はBCTファイルのブロック構造を詳細に記載しており、理解が難しいが、より正確に理解する必要があれば読んでみるとよいだろう。ここまで解析できるものなのかと驚きを禁じ得ない)。
---参考[1]の抜粋(日本語訳)
データファイルブロックへの変更はREDOエントリを生成する。より具体的には、REDOチェンジベクターを生成し、それをブロックに適用する。この適用はディスク上のブロックに直接適用される訳ではなく、バッファキャッシュにまずブロックを読み込み、それからブロックの内容に変更を適用する(ダイレクトパスライトはこの限りではない)。バッファキャッシュ上のブロックは「ダーティ」となり、DBWRが非同期にディスクへフラッシュする。
ダーティとなったブロック(チャンク)をBCTファイルへ書き込むのは、CTWRの役目である。サーバプロセスがREDOエントリをログバッファに書き込むのと同時に、SGA上の特別なバッファにどのブロックが変更されたかを記録する。のちにCTWRはこの情報を用いてBCTファイルを更新する。CTWRがBCTファイルを書き込むタイミングはチェックポイントである。CKPTプロセスはCTWRプロセスへシグナルを送り、このバッファの内容をBCTファイルにフラッシュするよう促す。CKPTはCTWRの書き込みを待たず、CTWRがシグナルを受け取ったことを確認したら、後続のデータファイルヘッダと制御ファイルを更新しチェックポイントを完了する。これと並行して、CTWRはBCTファイルへの更新を行う。
RMAN増分バックアップが開始されるとき、RMANのシャドープロセスはBCTファイルを読み、BCTファイルヘッダを更新する(X$KRCCDR経由で確認できるblock 2176情報もあわせて)。次に、RMANはCTWRプロセスにシグナルを送り、新しい(バックアップの)バージョンを作る必要があることを知らせる。CTWRはBCTに新しいバージョンを作成し、新しいエクステントを作り、必要なら古いビットマップをパージする。その後、CTWRはRMANに制御を返す。
これで初めてRMANのシャドープロセスは必要な過去のすべてのビットマップを読み込み、どのチャンクがバックアップに必要なのかを識別できる。最後にメインの処理である、ダーティなチャンクを読み、変更されたブロックをバックアップピースに書き込む処理を行う。
---
上記の「SGA上の特別なバッファ」とは、まさにpublic DBA bufferのことではないかと考えられる。ここには明記されていないが、public DBA bufferとはCTWRがLarge Pool上に確保するバッファであり、public DBA bufferが不足した場合はサイズが自動拡張されるものらしい。私の手元の環境でBCTを有効にしてLarge Poolのメモリを確認すると、CTWR dba bufferが確認できる。
SQL> select * from v$sgastat where POOL ='large pool';
POOL NAME BYTES CON_ID
-------------- -------------------------- ---------- ----------
large pool free memory 745472 0
large pool PX msg pool 491520 1
large pool CTWR dba buffer 880640 1★
large pool krcc extent chunk 2076672 1
AWRのSGA breakdown differnce by Pool and NameDB/Instのセクションに上記メモリサイズが記録されている。今回の事象では、DB再起動によりpublic DBA bufferが初期値になっていたことがAWRから確認できた。
(1)年末年始のメンテナンス作業でDBインスタンスを再起動した。このとき、CTWRが使うパブリックDBAバッファがクリアされ、初期値のサイズになった。このサイズが小さかったのでLarge Poolも小さくなった(large_pool_sizeは指定せず自動調整としていたため)
(2)オンライン業務が開始され、更新のDMLが発行されると、サーバプロセスはREDO(チェンジベクター)を生成するとともに、CTWRへ更新ブロック情報を連携する。CTWRからBCTファイルへの書き込みは非同期なので、CTWRはIOを待つことなくサーバプロセスへACKを返す。CTWRはCKPTからチェックポイントのタイミングで書き込み要求を受け取り、BCTファイルへパブリックDBAバッファの内容をBCTへ書き込む
(3)RMANバックアップが開始される。このとき、BCTに新しいバージョンを作成する等の更新が発生するため、パブリックDBAバッファに書き込む(a)。このとき、パブリックDBAバッファが不足したため、CTWRは自動拡張を試みる(b)。拡張中はパブリックDBAバッファは排他ロックを獲得し、サーバプロセスからのパブリックDBAバッファへのアクセスは待たされる(e)
(4)CKPTは定期的にCTWRへ書き込み要求を出すが、自動拡張中はパブリックDBAバッファの排他ロックによりCTWRが要求を返却できず、待たされる(f)
(5)パブリックDBAバッファを拡張するため、Large Pool内に空きメモリを確保しようとする。ここで、Large Poolが不足したため、動的に拡張(GLOW/IMMEDIATE)しようと試みる。具体的にはバッファキャッシュから256MBを減らし(c)、Large Poolに同サイズを追加する(d)。これに要する時間が1分程度かかる
(6)Large Poolの拡張が完了し、パブリックDBAバッファの拡張が完了する。CTWRはパブリックDBAバッファへのロックを解放し、サーバプロセスやCKPTからの書き込み要求を受け付けるようになり、待機が解消する
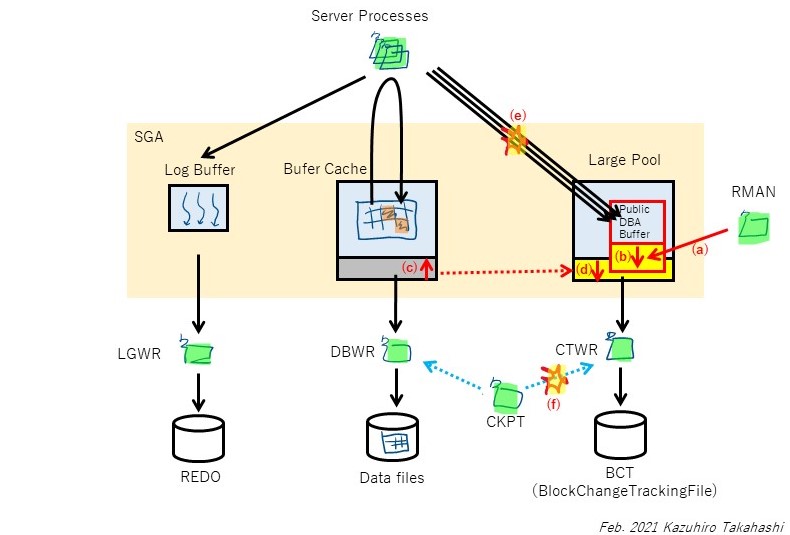
発生した状況からは概ねこのようなメカニズムで今回の事象は発生したのではないかと思っている。もちろん内部の動きは公開されておらず想像込みであるので、これで全容を把握できているとは思っていないし、正しさも保証できない。それでも、パブリックDBAバッファ、およびLarge Poolの動的拡張に時間がかかると、その間、更新を伴うトランザクションおよびCKPTがハングのような状態に陥るという関連性は理解できる。また、自動拡張で時間がかかったのは恐らく(c)(d)の動きとみている。(b)だけであれば、すでに確保されたプール内での拡張なので、目に見える待機が生じるとは思えない。
BCTを使っている場合は、インスタンス再起動後にLarge Poolが小さくならないように、再起動前にAWR等でサイズを確認しておき、large_pool_sizeに設定しておくとよい。large_pool_sizeは最低値を設定するものなので、再起動後にpublic DBA bufferが小さくなったとしても、Large Poolは少なくとも再起動前のサイズを維持しているので、初回RMANバックアップでpublic DBA bufferが自動調整され拡張されたとしても、Large Poolの自動拡張までに及ぶことはなく、遅延の影響は限定的にすることができると考える。large_pool_sizeはオンラインで変更できるし、運用中の現在の値に設定するだけなので、何らリスクはないはずである。
上記に加えpublic DBA bufferのサイズを固定化することも対策として有効である。これは隠しパラメータ(_bct_public_dba_buffer_size)で制御できるため、サポートに確認の上、対処することが望ましい。固定化すると自動調整が効かなくなるデメリットはあるものの、不足した場合はCTWRがBCTへ書き込みが追い付かず、block change tracking buffer space待機が出る可能性があるが、エラーとなるような状況にはならないはずである。AWRからこの待機が顕著に表れるようになれば、このパラメータをチューニングすればよいだけの話である。
また、そもそもインスタンス再起動でpublic DBA bufferのサイズが維持されないのは不具合らしく、すでにパッチ(BUG 30289516 BCT BUNDLED FIXES FOR EASE OF BACK PORTING)が出ているため、12c~19cでこれから対処が可能であれば、要否を含めサポートに確認するとよい。
本記事が、OracleのDBAにとって少しでも平和な正月を迎える一助になれば幸いである。
2021/8/19追記
発生メカニズムの図の(a)の矢印は、RMANから直接Public DBA Bufferを指しているが、これは正確ではない。参考[1]によれば、RMANが直接public DBA bufferへ書き込むのではなく、RMANがCTWRへシグナルを送信し、CTWRがバッファを必要に応じて確保(拡張)する動きとなるので、より正確にはRMAN→CTWR→Public DBA Bufferと記載すべきであった。いずれ図を書き換えたいが、ここに訂正しておく。
1.発生事象
オンラインが一時的(約1分程度)滞留し、これによるAPのタイムアウトエラーが発生。切り分けの結果、DBで遅延が発生していたことが判明した。AWRを見ると、該当時間帯に、顕著なCTWRの待機(enq: CT - CTWR process start/stop)が発生していた。ASHからも、該当時間帯、上記待機でSQLが待たされていることが分かった。また、alert.logにはCKPTが上記待機で1分程度待たされたログと、public dba bufferがあふれた旨のメッセージが記録されていた。2.解析
CTWRの待機(enq: CT - CTWR process start/stop)は、マニュアルに明確な記載はない。しかし、CTWR(Change Tracking Writer Process)はRMANのブロックチェンジトラッキング(BCT)のバックグラウンドプロセスであることから、これに関連した待機であることは想像できる。確かに遅延が発生した時間は、日次のRMANのバックアップ取得ジョブの実行開始時間であったため、RMANバックアップが直接的な引き金として、フォアグラウンドプロセスにブロックチェンジトラッキングの待機が発生したのだろう。ブロックチェンジトラッキング(BCT)とは、RMANの高速増分バックアップを取得する際に、どのブロックが前回バックアップから更新されたかを記録する仕組みである。この機能により、RMANは更新されたブロックだけを読み込み、バックアップを取得することができるため、バックアップ時間を短縮するために一般的に使われている機能である。
しかし、バックアップを取得することで、業務のSQL(フォアグラウンドプロセス)に遅延を発生させ得ることがあるのだろうか。alertログに出ていたpublic DBA bufferが不足したメッセージがあることから、少なくともRMANバックアップが引き金となりこのメモリ領域が枯渇し、それによりCKPTに待機が発生し、そこから業務に遅延が波及した可能性はあると考えた。また、状況からDBインスタンス再起動後の初めてのRMANバックアップであったことから、public DBA bufferが不足した原因はDBインスタンス再起動と何等かの関連があるのではないか、という仮説は立てられた。
その後、サポートと解析を進めたところ、少しずつブロックチェンジトラッキングの仕組みが分かってきた。Oracle Ace DirectorのAlexander Gorbachev氏の記事(参考1)の関連部分を要約すると概ね以下のような内容である(原文はBCTファイルのブロック構造を詳細に記載しており、理解が難しいが、より正確に理解する必要があれば読んでみるとよいだろう。ここまで解析できるものなのかと驚きを禁じ得ない)。
---参考[1]の抜粋(日本語訳)
データファイルブロックへの変更はREDOエントリを生成する。より具体的には、REDOチェンジベクターを生成し、それをブロックに適用する。この適用はディスク上のブロックに直接適用される訳ではなく、バッファキャッシュにまずブロックを読み込み、それからブロックの内容に変更を適用する(ダイレクトパスライトはこの限りではない)。バッファキャッシュ上のブロックは「ダーティ」となり、DBWRが非同期にディスクへフラッシュする。
ダーティとなったブロック(チャンク)をBCTファイルへ書き込むのは、CTWRの役目である。サーバプロセスがREDOエントリをログバッファに書き込むのと同時に、SGA上の特別なバッファにどのブロックが変更されたかを記録する。のちにCTWRはこの情報を用いてBCTファイルを更新する。CTWRがBCTファイルを書き込むタイミングはチェックポイントである。CKPTプロセスはCTWRプロセスへシグナルを送り、このバッファの内容をBCTファイルにフラッシュするよう促す。CKPTはCTWRの書き込みを待たず、CTWRがシグナルを受け取ったことを確認したら、後続のデータファイルヘッダと制御ファイルを更新しチェックポイントを完了する。これと並行して、CTWRはBCTファイルへの更新を行う。
RMAN増分バックアップが開始されるとき、RMANのシャドープロセスはBCTファイルを読み、BCTファイルヘッダを更新する(X$KRCCDR経由で確認できるblock 2176情報もあわせて)。次に、RMANはCTWRプロセスにシグナルを送り、新しい(バックアップの)バージョンを作る必要があることを知らせる。CTWRはBCTに新しいバージョンを作成し、新しいエクステントを作り、必要なら古いビットマップをパージする。その後、CTWRはRMANに制御を返す。
これで初めてRMANのシャドープロセスは必要な過去のすべてのビットマップを読み込み、どのチャンクがバックアップに必要なのかを識別できる。最後にメインの処理である、ダーティなチャンクを読み、変更されたブロックをバックアップピースに書き込む処理を行う。
---
上記の「SGA上の特別なバッファ」とは、まさにpublic DBA bufferのことではないかと考えられる。ここには明記されていないが、public DBA bufferとはCTWRがLarge Pool上に確保するバッファであり、public DBA bufferが不足した場合はサイズが自動拡張されるものらしい。私の手元の環境でBCTを有効にしてLarge Poolのメモリを確認すると、CTWR dba bufferが確認できる。
SQL> select * from v$sgastat where POOL ='large pool';
POOL NAME BYTES CON_ID
-------------- -------------------------- ---------- ----------
large pool free memory 745472 0
large pool PX msg pool 491520 1
large pool CTWR dba buffer 880640 1★
large pool krcc extent chunk 2076672 1
AWRのSGA breakdown differnce by Pool and NameDB/Instのセクションに上記メモリサイズが記録されている。今回の事象では、DB再起動によりpublic DBA bufferが初期値になっていたことがAWRから確認できた。
3.DB遅延発生メカニズム
上記から、本事象の遅延発生メカニズムは以下のようなものと考えられる。(1)年末年始のメンテナンス作業でDBインスタンスを再起動した。このとき、CTWRが使うパブリックDBAバッファがクリアされ、初期値のサイズになった。このサイズが小さかったのでLarge Poolも小さくなった(large_pool_sizeは指定せず自動調整としていたため)
(2)オンライン業務が開始され、更新のDMLが発行されると、サーバプロセスはREDO(チェンジベクター)を生成するとともに、CTWRへ更新ブロック情報を連携する。CTWRからBCTファイルへの書き込みは非同期なので、CTWRはIOを待つことなくサーバプロセスへACKを返す。CTWRはCKPTからチェックポイントのタイミングで書き込み要求を受け取り、BCTファイルへパブリックDBAバッファの内容をBCTへ書き込む
(3)RMANバックアップが開始される。このとき、BCTに新しいバージョンを作成する等の更新が発生するため、パブリックDBAバッファに書き込む(a)。このとき、パブリックDBAバッファが不足したため、CTWRは自動拡張を試みる(b)。拡張中はパブリックDBAバッファは排他ロックを獲得し、サーバプロセスからのパブリックDBAバッファへのアクセスは待たされる(e)
(4)CKPTは定期的にCTWRへ書き込み要求を出すが、自動拡張中はパブリックDBAバッファの排他ロックによりCTWRが要求を返却できず、待たされる(f)
(5)パブリックDBAバッファを拡張するため、Large Pool内に空きメモリを確保しようとする。ここで、Large Poolが不足したため、動的に拡張(GLOW/IMMEDIATE)しようと試みる。具体的にはバッファキャッシュから256MBを減らし(c)、Large Poolに同サイズを追加する(d)。これに要する時間が1分程度かかる
(6)Large Poolの拡張が完了し、パブリックDBAバッファの拡張が完了する。CTWRはパブリックDBAバッファへのロックを解放し、サーバプロセスやCKPTからの書き込み要求を受け付けるようになり、待機が解消する
発生した状況からは概ねこのようなメカニズムで今回の事象は発生したのではないかと思っている。もちろん内部の動きは公開されておらず想像込みであるので、これで全容を把握できているとは思っていないし、正しさも保証できない。それでも、パブリックDBAバッファ、およびLarge Poolの動的拡張に時間がかかると、その間、更新を伴うトランザクションおよびCKPTがハングのような状態に陥るという関連性は理解できる。また、自動拡張で時間がかかったのは恐らく(c)(d)の動きとみている。(b)だけであれば、すでに確保されたプール内での拡張なので、目に見える待機が生じるとは思えない。
4.教訓
RMANでBCTを使っていても、オンライン処理と重ならなければ、1分程度の待機は気づくことないかもしれない。本事象はクリティカルなオンライン処理において、BCTを使っており、large_pool_sizeを設定していないシステムに限定されるだろう。言うまでもなく、バックアップでRMANを使っていなければ、BCTを使う必要はない。ストレージのスナップショット機能等を使ってバックアップをしているなら関係ない。BCTを使っている場合は、インスタンス再起動後にLarge Poolが小さくならないように、再起動前にAWR等でサイズを確認しておき、large_pool_sizeに設定しておくとよい。large_pool_sizeは最低値を設定するものなので、再起動後にpublic DBA bufferが小さくなったとしても、Large Poolは少なくとも再起動前のサイズを維持しているので、初回RMANバックアップでpublic DBA bufferが自動調整され拡張されたとしても、Large Poolの自動拡張までに及ぶことはなく、遅延の影響は限定的にすることができると考える。large_pool_sizeはオンラインで変更できるし、運用中の現在の値に設定するだけなので、何らリスクはないはずである。
上記に加えpublic DBA bufferのサイズを固定化することも対策として有効である。これは隠しパラメータ(_bct_public_dba_buffer_size)で制御できるため、サポートに確認の上、対処することが望ましい。固定化すると自動調整が効かなくなるデメリットはあるものの、不足した場合はCTWRがBCTへ書き込みが追い付かず、block change tracking buffer space待機が出る可能性があるが、エラーとなるような状況にはならないはずである。AWRからこの待機が顕著に表れるようになれば、このパラメータをチューニングすればよいだけの話である。
また、そもそもインスタンス再起動でpublic DBA bufferのサイズが維持されないのは不具合らしく、すでにパッチ(BUG 30289516 BCT BUNDLED FIXES FOR EASE OF BACK PORTING)が出ているため、12c~19cでこれから対処が可能であれば、要否を含めサポートに確認するとよい。
本記事が、OracleのDBAにとって少しでも平和な正月を迎える一助になれば幸いである。
◆参考文献
[1]ORACLE 10G BLOCK CHANGE TRACKING INSIDE OUT (Doc ID 1528510.1)2021/8/19追記
発生メカニズムの図の(a)の矢印は、RMANから直接Public DBA Bufferを指しているが、これは正確ではない。参考[1]によれば、RMANが直接public DBA bufferへ書き込むのではなく、RMANがCTWRへシグナルを送信し、CTWRがバッファを必要に応じて確保(拡張)する動きとなるので、より正確にはRMAN→CTWR→Public DBA Bufferと記載すべきであった。いずれ図を書き換えたいが、ここに訂正しておく。
2021-02-04 07:26
Autonomous Database (ADB)はどこまで使えるか [アーキテクチャ]
1.はじめに
私の周りでは更改前のオンプレの運用中のトラブルの話がまだ多く、クラウドを実感することはさほど多くない。しかし、レビュー等でAWS RDSを使う案件の増加を実感するところでもある。私も遅ればせながら、今年春から実際にADBやOCIを触り始めている。今のところ私がやったのは、以下のリンクから、Autonomouse databaseとOCI architectの動画を一通り見て、実際にOCIを使ってみて学習した。3~4か月程度の学習の結果、Autonomous databaseやOCI architect associateまでは取得できた。残念ながらarchitect professionalは不合格だったが、これは2年の実務経験と謳っているだけに妥当なところかもしれない。
Oracle Ramps Up Free Online Learning and Certifications for Oracle Cloud Infrastructure and Oracle Autonomous Database
実際ADBやOCIを触ってみて、その使い方を学ぶことはたいして難しくないことはよくわかる。例えば、DBの構築はDBのタイプ、CPU数や領域サイズ等を指定すれば、数クリックでインスタンスが上がってしまう。バックアップは自動で取得されており、リストアはリカバリポイントを選択してクリックするのみ。時代は確実に現場のDBAの定型作業をコモディティ化する方向に進んでいると感じる。逆に定型作業に落ちない部分、例えばクラウドへの移行や、サービスの制約とオンプレのギャップを埋める作業、性能チューニング、障害の切り分けなどは、難しくなるかもしれないと感じている。その意味でも、やはりクラウドサービスの理解とその制約を正しく理解することは、避けることができないと感じている。
2.ADBで運用上気になること
Autonomous Database (ADB)で気になったのは、オンプレ運用に慣れた感覚からすると制約があることである。特にOSへのアクセスが制限されていることは思いのほか不便で、例えばディレクトリオブジェクト経由で入出力するファイルをOSから直接アクセスできない。DBMS_CLOUDパッケージでデータロードしたときのエラーログファイルも、OSから直接アクセスする方法がないため、DBMS_CLOUDパッケージを使って、都度オブジェクトストレージを介してファイルをやりとりする必要がある。実際運用で使った経験がないのであくまで想像でしかないが、DBAとしては結構面倒なのではないかと思う。AWSのRDSも同様のコンセプトであるので、これに関していえばOracleが、というよりクラウドPaaSの共通の課題かもしれない。
また、DBの障害解析でalert.logや各種トレースファイルを見たい場合にどうすればよいのかという点も気になる。フルマネージドなクラウドサービスとはいえ、単純なハード障害でなければ、オンプレと同じように問題の切り分けを行うためにログを見なければならない状況になり得るだろう。検知はOEMでできるとして、いままでのようにユーザ側で生ログ見てMOSで調べて切り分けることは難しくなるかもしれない。ユーザはよりアプリケーションに近い問題(AWRやASHを使ったSQL性能改善やORA-1555など)に注力し、ORA-600などのトラシューは隠蔽され、定期パッチ適用でいつのまにか自然に修正されているという世界が一般的になっていくのかもしれない。いずれにしても、ログ一式をまとめてSRへ送付する必要がなくなるのは本当にありがたい。
3.もし今のシステムでADBを使うことになったら
今回勉強を通して分かったことをベースに、実際どこまでこのサービスが使えるのか、今現在自分の関わっているシステムで考察してみよう。本システムはExadata上に3つの異なるDBを構成(OLTP用、バッチ用、DWH用)し、規模はそれぞれ数TB程度、バックアップはRMANでZFSへ、監視はOEMを用いている。これをADBに移行するとした場合の構成、課題を考えてみたい。
◇ATPかADWか
初めの選択は、それぞれのDBをATP、ADWどちらへ移行するか、という点である。ATPはOLTP用、ADWはDWH用なので、オンライン、バッチメインのDBはATPで問題ないだろう。しかしDWHは単純にADWを選択すればよい、ということではない。ADWはカラムストア、デフォルトでEHCC(圧縮)が有効、デフォルトでHINTは効かない、といった違いがあることから、移行する上ではどのような動きになるのか予想が難しい。APになるべく手を入れず現行の動きを踏襲したいなら、ATPを選択すべきだろう。ADWを選択するなら、SQLのチューニングやアーキテクチャ(利用しているミドルの設定)を見直す覚悟が必要だろう。
◇sharedかdedicatedか
続いての選択は、sharedがdedicatedかである。言うまでもなくsharedは複数のユーザ(テナント)でDBサーバを共有するため、必然的に運用に制約が生じる。例えば、四半期に一度のパッチ適用のタイミングは今のところsharedではカスタマイズできない。実際、私のADWの環境では、Next Maintenance: Sat, Sep 5, 2020, 09:00:00 UTC -13:00:00 UTC(日本時間なら18時~24時)というように、次回のメンテナンスのタイミングが示されている(通常この4時間全部がメンテナンスにかかる訳ではなく、実際は2時間以下らしい)。実際のシステム運用では、データベース毎に停止調整可能な日や時間帯が決まっているので、そのタイミングを狙って計画する。オンラインでメンテナンスされるとはいえ、sharedの選択はなく、やはりdedicated一択であろう。
◇CPUのサイジング
CPUサイジングは、オンプレExadataのコア数をベースに必要なOCPUを算出するが、メモリがOCPUベースで決まってしまうので、両方満たすようなシェイプにする必要がある。現在ADBのハードとして選択可能なExadataX8-2 halfのスペックを見ると、CPUは200コア、メモリは2,880GBメモリ/4ノード(50コア、720GBメモリ/ノード)であり、現在オンプレで動いているOracleではなかなか使い切れない程の高スペックである。なお、フラッシュキャッシュがRAWで179.2TBということは、3冗長(WriteBack)でおおむね論理50TB以上使えることになるので、数TBレベルのDBはすべてフラッシュキャッシュに乗ってしまう。現在、バッチ処理等でシングルブロックリードの待機でI/Oネックとなっていた処理は、I/Oレイテンシの向上により性能向上の恩恵を受けられるはずである。
A Characteristics of Infrastructure Shapes
◇接続性
本システムはオンラインはAPサーバからはJDBC接続、バッチサーバやBIツールからはOracle*Netの接続がある。移行に際し、ADBの接続に必要な資格証明ファイルをクライアントに配置し適切な設定をする必要がある。実際に資格証明をダウンロードするとWallet_(DB名).zipというファイルが得られるが、この中には以下のファイルが含まれる。Oracleクライアントからの接続は、?/network/admin配下にcwallet.ssoを配置し、既存のtnsnames.oraの接続情報を下記tnsnames.oraの内容に書き換え、sqlnet.oraにWALLET_LOCATIONを追加すればADBに接続できるようになる。JDBCでは"jdbc:oracle:thin:@接続識別子?TNS_ADMIN=XXX"のように、TNS_ADMINでウォレットの格納場所をデフォルトから変更すれば良いようだ。
tnsnames.oraには以下のようにhigh、low、mediumの3種類のサービスに接続できるよう、接続識別子が用意されている(以下はADWの例。ATPではこれに加え、tpurgentとtpが追加される)。既存の接続識別子を踏襲し、接続内容だけ下記に書き換えれば、既存クライアント資材への影響を少なくDB接続先をADBに変更できる。
移行の際には接続毎にどれを使うかを考えなければならない。上記それぞれのサービスの違いは以下マニュアルに記載されている。OLTP系の接続は同時実行性が求められるため、一律tpurgentで良いだろう。バッチ系APはtpでも良さそうだが、paralellismが使えないので、やはりtpurgentしかない。そもそもリソースマネージャに依存せずに設計されたシステムでは、一律tpurgentでの接続と割り切っても良いのではないか。なお、もしADWを使う場合は少し注意が必要である。ADWのhighはparallelismはCPU_COUNTまでであるが、Concurrent Statements(同時実行できるSQL数)が3に限定されている。DWH系アプリケーションの夜間バッチは多重実行されるため、ここはmediumを選択し、parallelismは4に制限されるが、Concurrent Statementsがparallelismが1.25 × CPU_COUNTとなるのが良いだろう。
Predefined Database Service Names for Autonomous Transaction Processing
Predefined Database Service Names for Autonomous Data Warehouse Dedicated Databases
◇バックアップ
ADBのバックアップは、保持期間60日、PITRでいつでも任意のタイミングにリカバリできる。しかし、sharedではバックアップのタイミングや保持期間がカスタマイズできない。例えば私のADWの環境ではUTCで12時頃(JSTで21時頃)にインクリメンタルバックアップが取得されているが、今のシステムでは、この時間は月次の重要バッチと重なってしまう。この点、dedicatedならバックアップタイミングがカスタマイズが可能、かつ、保持期間も7、15、30、60日から選択できるようになる。また、マニュアルバックアップを取得できるので、特定のリリースのタイミング等でのバックアップに利用できる。実運用上は主要なバッチと重ならないように制御することを考えると、オブジェクトストレージへのバックアップ性能を見極め、現在のバックアップウィンドウに収まるかを見切る必要がある。このあたりは実際に性能を検証して確認する必要があるだろう。
一点気になるのは、開発期間中のバックアップ・リカバリである。例えば性能試験では、特定のDBのデータ断面バックアップしておき、試験後にその断面をリストアする。試験を同じデータの条件で実行するために、何度も同じ断面にリストア(フラッシュバックDB)する。夜間にシナリオを流せるよう、リストアもジョブに組み込み自動化する。このような使い方をするには、マニュアルバックアップとフラッシュバックDBを組み合わせればできそうな気はするが、フラッシュバックの保持期間が24時間では土日かけて流すシナリオに耐えられないとか、自動化のために外部インタフェースからフラッシュバックDBを起動する仕組みづくりを考えないといけないといった解決すべき課題はいくつか出てきそうである。複数断面を任意のタイミングにリカバリすることの難しさを経験した方なら、これがクラウドで簡単に実現できる日を待っているに違いない。
◇監視
現時点ではATP dedicatedのみだが、OCIマーケットプレイスのOEMが使えるので、これで一通りの監視が可能と思われる。alert.logでORA-エラーが発生したことの検知や、メモリや領域等のリソース(閾値)監視は基本的に用意されたテンプレートを利用して作りこめばよいだろう。拡張メトリックで作りこんだ部分のカスタマイズがどの程度許されるのか、あたりが若干懸念としてある。また、OEMで検知したメッセージをJP1/IMの統合監視に連携する必要があるので、この実現方式は要検討である。
Administrator's Guide for Oracle Autonomous Databases
◇その他懸念点
まず気になった点はDBのキャラクタセットである。本システムのDBのキャラクタセットはSJIS(外字あり)なので、ADBへの移行に際しても同じキャラクタセットが好ましい。sharedはAL32UTF8となってしまうのでこの意味も採用は難しい。sharedの場合、CDBを共有しPDBをテナントとして提供しているはずで、この場合、CDBとPDBの文字コードは合わせておきたいのは理解できる。その意味でdedicatedだとカスタマイズできるのではないかと期待したが、現時点では難しいようだ。これはかなり厳しい制約で、文字コード変換を伴う移行は難易度が格段に上がることを考えると、今後の対応に期待したい。
Developer’s Guide to Oracle Autonomous Transaction Processing on Dedicated Exadata Infrastructure
次に気になった点はDBLINKである。本システムでは、異なるDB間でDBLINKを使って表への参照・更新を行っている。ADB間のDBLINKの作成は可能なので、この点は問題なさそうである(tnsnames.oraが使えないので、create database linkで指定するのは接続識別子ではなく、Easy Connectの書式で指定する)。ただ、現状PL/SQLプロシージャでDBLINKの使用はできないという制約がある。本システムではPro*CやMVIEWのほか、PL/SQLでもDBLINKを使用しているため、この制約はかなり厳しい。今後の対応に期待したい。
4.まとめ
ADBについて最近学んだことをベースに、現在私の関わっているシステムへADBはどの程度使えるのかを考察してみたが、やはり今の運用を変えずに移行するのは難しいと感じた。クラウドサービスをベースに運用を見直す前提で考え直す必要があるので、まずそこのハードルをクリアできるかがポイントと感じる。私の感覚として、変わらないことを是とする企業風土の中では、このハードルは決して低いものではない。この他、文字コードやDBLINKに関しては、現時点では厳しい制約がある点もあることがわかった。このような技術的な問題については、クラウドサービスの拡充に伴い解消していくのではという期待もあるので、今後も継続して注視していきたいと思う。なお、本記事内容は現時点で私が知ったことをベースに記載しているため、正確でない部分があるかもしれない旨、ご容赦頂きたい。
以上
私の周りでは更改前のオンプレの運用中のトラブルの話がまだ多く、クラウドを実感することはさほど多くない。しかし、レビュー等でAWS RDSを使う案件の増加を実感するところでもある。私も遅ればせながら、今年春から実際にADBやOCIを触り始めている。今のところ私がやったのは、以下のリンクから、Autonomouse databaseとOCI architectの動画を一通り見て、実際にOCIを使ってみて学習した。3~4か月程度の学習の結果、Autonomous databaseやOCI architect associateまでは取得できた。残念ながらarchitect professionalは不合格だったが、これは2年の実務経験と謳っているだけに妥当なところかもしれない。
Oracle Ramps Up Free Online Learning and Certifications for Oracle Cloud Infrastructure and Oracle Autonomous Database
実際ADBやOCIを触ってみて、その使い方を学ぶことはたいして難しくないことはよくわかる。例えば、DBの構築はDBのタイプ、CPU数や領域サイズ等を指定すれば、数クリックでインスタンスが上がってしまう。バックアップは自動で取得されており、リストアはリカバリポイントを選択してクリックするのみ。時代は確実に現場のDBAの定型作業をコモディティ化する方向に進んでいると感じる。逆に定型作業に落ちない部分、例えばクラウドへの移行や、サービスの制約とオンプレのギャップを埋める作業、性能チューニング、障害の切り分けなどは、難しくなるかもしれないと感じている。その意味でも、やはりクラウドサービスの理解とその制約を正しく理解することは、避けることができないと感じている。
2.ADBで運用上気になること
Autonomous Database (ADB)で気になったのは、オンプレ運用に慣れた感覚からすると制約があることである。特にOSへのアクセスが制限されていることは思いのほか不便で、例えばディレクトリオブジェクト経由で入出力するファイルをOSから直接アクセスできない。DBMS_CLOUDパッケージでデータロードしたときのエラーログファイルも、OSから直接アクセスする方法がないため、DBMS_CLOUDパッケージを使って、都度オブジェクトストレージを介してファイルをやりとりする必要がある。実際運用で使った経験がないのであくまで想像でしかないが、DBAとしては結構面倒なのではないかと思う。AWSのRDSも同様のコンセプトであるので、これに関していえばOracleが、というよりクラウドPaaSの共通の課題かもしれない。
また、DBの障害解析でalert.logや各種トレースファイルを見たい場合にどうすればよいのかという点も気になる。フルマネージドなクラウドサービスとはいえ、単純なハード障害でなければ、オンプレと同じように問題の切り分けを行うためにログを見なければならない状況になり得るだろう。検知はOEMでできるとして、いままでのようにユーザ側で生ログ見てMOSで調べて切り分けることは難しくなるかもしれない。ユーザはよりアプリケーションに近い問題(AWRやASHを使ったSQL性能改善やORA-1555など)に注力し、ORA-600などのトラシューは隠蔽され、定期パッチ適用でいつのまにか自然に修正されているという世界が一般的になっていくのかもしれない。いずれにしても、ログ一式をまとめてSRへ送付する必要がなくなるのは本当にありがたい。
3.もし今のシステムでADBを使うことになったら
今回勉強を通して分かったことをベースに、実際どこまでこのサービスが使えるのか、今現在自分の関わっているシステムで考察してみよう。本システムはExadata上に3つの異なるDBを構成(OLTP用、バッチ用、DWH用)し、規模はそれぞれ数TB程度、バックアップはRMANでZFSへ、監視はOEMを用いている。これをADBに移行するとした場合の構成、課題を考えてみたい。
◇ATPかADWか
初めの選択は、それぞれのDBをATP、ADWどちらへ移行するか、という点である。ATPはOLTP用、ADWはDWH用なので、オンライン、バッチメインのDBはATPで問題ないだろう。しかしDWHは単純にADWを選択すればよい、ということではない。ADWはカラムストア、デフォルトでEHCC(圧縮)が有効、デフォルトでHINTは効かない、といった違いがあることから、移行する上ではどのような動きになるのか予想が難しい。APになるべく手を入れず現行の動きを踏襲したいなら、ATPを選択すべきだろう。ADWを選択するなら、SQLのチューニングやアーキテクチャ(利用しているミドルの設定)を見直す覚悟が必要だろう。
◇sharedかdedicatedか
続いての選択は、sharedがdedicatedかである。言うまでもなくsharedは複数のユーザ(テナント)でDBサーバを共有するため、必然的に運用に制約が生じる。例えば、四半期に一度のパッチ適用のタイミングは今のところsharedではカスタマイズできない。実際、私のADWの環境では、Next Maintenance: Sat, Sep 5, 2020, 09:00:00 UTC -13:00:00 UTC(日本時間なら18時~24時)というように、次回のメンテナンスのタイミングが示されている(通常この4時間全部がメンテナンスにかかる訳ではなく、実際は2時間以下らしい)。実際のシステム運用では、データベース毎に停止調整可能な日や時間帯が決まっているので、そのタイミングを狙って計画する。オンラインでメンテナンスされるとはいえ、sharedの選択はなく、やはりdedicated一択であろう。
◇CPUのサイジング
CPUサイジングは、オンプレExadataのコア数をベースに必要なOCPUを算出するが、メモリがOCPUベースで決まってしまうので、両方満たすようなシェイプにする必要がある。現在ADBのハードとして選択可能なExadataX8-2 halfのスペックを見ると、CPUは200コア、メモリは2,880GBメモリ/4ノード(50コア、720GBメモリ/ノード)であり、現在オンプレで動いているOracleではなかなか使い切れない程の高スペックである。なお、フラッシュキャッシュがRAWで179.2TBということは、3冗長(WriteBack)でおおむね論理50TB以上使えることになるので、数TBレベルのDBはすべてフラッシュキャッシュに乗ってしまう。現在、バッチ処理等でシングルブロックリードの待機でI/Oネックとなっていた処理は、I/Oレイテンシの向上により性能向上の恩恵を受けられるはずである。
A Characteristics of Infrastructure Shapes
Specification:Exadata X8-2 Half Rack
Shape Name:Exadata.Half3.200
Number of Compute Nodes:4
・Total Maximum Number of Enabled CPU Cores:200
・Total RAM Capacity:2880 GB
◇接続性
本システムはオンラインはAPサーバからはJDBC接続、バッチサーバやBIツールからはOracle*Netの接続がある。移行に際し、ADBの接続に必要な資格証明ファイルをクライアントに配置し適切な設定をする必要がある。実際に資格証明をダウンロードするとWallet_(DB名).zipというファイルが得られるが、この中には以下のファイルが含まれる。Oracleクライアントからの接続は、?/network/admin配下にcwallet.ssoを配置し、既存のtnsnames.oraの接続情報を下記tnsnames.oraの内容に書き換え、sqlnet.oraにWALLET_LOCATIONを追加すればADBに接続できるようになる。JDBCでは"jdbc:oracle:thin:@接続識別子?TNS_ADMIN=XXX"のように、TNS_ADMINでウォレットの格納場所をデフォルトから変更すれば良いようだ。
- README ・・・この資格証明のダウンロード日時と有効期限(5年)が記載されいている
- cwallet.sso ・・・パスワード不要で自動ログイン可能とするためのウォレット
- ewallet.p12 ・・・パスワードが必要なPKCS#12ウォレット
- tnsnames.ora ・・・接続先ADBの接続識別子情報。サービス(high, medium, low等)に応じてエントリがそれぞれ用意されている
- sqlnet.ora ・・・WALLET_LOCATIONのDIRECTORYに資格証明の格納場所ディレクトリを指定する
- ojdbc.properties ・・・wallet_locationDIRECTORYに資格証明の格納場所ディレクトリを指定する
- keystore.jks、truststore.jks ・・・JKSを使う場合に必要なファイル
tnsnames.oraには以下のようにhigh、low、mediumの3種類のサービスに接続できるよう、接続識別子が用意されている(以下はADWの例。ATPではこれに加え、tpurgentとtpが追加される)。既存の接続識別子を踏襲し、接続内容だけ下記に書き換えれば、既存クライアント資材への影響を少なくDB接続先をADBに変更できる。
orcl_high = (description= (retry_count=20)(retry_delay=3)(address=(protocol=tcps)(port=1522)(host=xxx.ap-tokyo-1.oraclecloud.com))(connect_data=(service_name=xxxxxxxxxxxxxxx_orcl_high.adwc.oraclecloud.com))(security=(ssl_server_cert_dn="CN=adb.ap-tokyo-1.oraclecloud.com,OU=Oracle ADB TOKYO,O=Oracle Corporation,L=Redwood City,ST=California,C=US"))) orcl_low = (description= (retry_count=20)(retry_delay=3)(address=(protocol=tcps)(port=1522)(host=xxx.ap-tokyo-1.oraclecloud.com))(connect_data=(service_name=xxxxxxxxxxxxxxx_orcl_low.adwc.oraclecloud.com))(security=(ssl_server_cert_dn="CN=adb.ap-tokyo-1.oraclecloud.com,OU=Oracle ADB TOKYO,O=Oracle Corporation,L=Redwood City,ST=California,C=US"))) orcl_medium = (description= (retry_count=20)(retry_delay=3)(address=(protocol=tcps)(port=1522)(host=xxx.ap-tokyo-1.oraclecloud.com))(connect_data=(service_name=xxxxxxxxxxxxxxx_orcl_medium.adwc.oraclecloud.com))(security=(ssl_server_cert_dn="CN=adb.ap-tokyo-1.oraclecloud.com,OU=Oracle ADB TOKYO,O=Oracle Corporation,L=Redwood City,ST=California,C=US")))
移行の際には接続毎にどれを使うかを考えなければならない。上記それぞれのサービスの違いは以下マニュアルに記載されている。OLTP系の接続は同時実行性が求められるため、一律tpurgentで良いだろう。バッチ系APはtpでも良さそうだが、paralellismが使えないので、やはりtpurgentしかない。そもそもリソースマネージャに依存せずに設計されたシステムでは、一律tpurgentでの接続と割り切っても良いのではないか。なお、もしADWを使う場合は少し注意が必要である。ADWのhighはparallelismはCPU_COUNTまでであるが、Concurrent Statements(同時実行できるSQL数)が3に限定されている。DWH系アプリケーションの夜間バッチは多重実行されるため、ここはmediumを選択し、parallelismは4に制限されるが、Concurrent Statementsがparallelismが1.25 × CPU_COUNTとなるのが良いだろう。
Predefined Database Service Names for Autonomous Transaction Processing
Predefined Database Service Names for Autonomous Data Warehouse Dedicated Databases
◇バックアップ
ADBのバックアップは、保持期間60日、PITRでいつでも任意のタイミングにリカバリできる。しかし、sharedではバックアップのタイミングや保持期間がカスタマイズできない。例えば私のADWの環境ではUTCで12時頃(JSTで21時頃)にインクリメンタルバックアップが取得されているが、今のシステムでは、この時間は月次の重要バッチと重なってしまう。この点、dedicatedならバックアップタイミングがカスタマイズが可能、かつ、保持期間も7、15、30、60日から選択できるようになる。また、マニュアルバックアップを取得できるので、特定のリリースのタイミング等でのバックアップに利用できる。実運用上は主要なバッチと重ならないように制御することを考えると、オブジェクトストレージへのバックアップ性能を見極め、現在のバックアップウィンドウに収まるかを見切る必要がある。このあたりは実際に性能を検証して確認する必要があるだろう。
一点気になるのは、開発期間中のバックアップ・リカバリである。例えば性能試験では、特定のDBのデータ断面バックアップしておき、試験後にその断面をリストアする。試験を同じデータの条件で実行するために、何度も同じ断面にリストア(フラッシュバックDB)する。夜間にシナリオを流せるよう、リストアもジョブに組み込み自動化する。このような使い方をするには、マニュアルバックアップとフラッシュバックDBを組み合わせればできそうな気はするが、フラッシュバックの保持期間が24時間では土日かけて流すシナリオに耐えられないとか、自動化のために外部インタフェースからフラッシュバックDBを起動する仕組みづくりを考えないといけないといった解決すべき課題はいくつか出てきそうである。複数断面を任意のタイミングにリカバリすることの難しさを経験した方なら、これがクラウドで簡単に実現できる日を待っているに違いない。
◇監視
現時点ではATP dedicatedのみだが、OCIマーケットプレイスのOEMが使えるので、これで一通りの監視が可能と思われる。alert.logでORA-エラーが発生したことの検知や、メモリや領域等のリソース(閾値)監視は基本的に用意されたテンプレートを利用して作りこめばよいだろう。拡張メトリックで作りこんだ部分のカスタマイズがどの程度許されるのか、あたりが若干懸念としてある。また、OEMで検知したメッセージをJP1/IMの統合監視に連携する必要があるので、この実現方式は要検討である。
Administrator's Guide for Oracle Autonomous Databases
◇その他懸念点
まず気になった点はDBのキャラクタセットである。本システムのDBのキャラクタセットはSJIS(外字あり)なので、ADBへの移行に際しても同じキャラクタセットが好ましい。sharedはAL32UTF8となってしまうのでこの意味も採用は難しい。sharedの場合、CDBを共有しPDBをテナントとして提供しているはずで、この場合、CDBとPDBの文字コードは合わせておきたいのは理解できる。その意味でdedicatedだとカスタマイズできるのではないかと期待したが、現時点では難しいようだ。これはかなり厳しい制約で、文字コード変換を伴う移行は難易度が格段に上がることを考えると、今後の対応に期待したい。
Developer’s Guide to Oracle Autonomous Transaction Processing on Dedicated Exadata Infrastructure
Characteristics of an Autonomous Transaction Processing dedicated database include:- The default data and temporary tablespaces for the database are configured automatically.
- The name of the default data tablespace is DATA.
- The database character set is Unicode AL32UTF8.
...
次に気になった点はDBLINKである。本システムでは、異なるDB間でDBLINKを使って表への参照・更新を行っている。ADB間のDBLINKの作成は可能なので、この点は問題なさそうである(tnsnames.oraが使えないので、create database linkで指定するのは接続識別子ではなく、Easy Connectの書式で指定する)。ただ、現状PL/SQLプロシージャでDBLINKの使用はできないという制約がある。本システムではPro*CやMVIEWのほか、PL/SQLでもDBLINKを使用しているため、この制約はかなり厳しい。今後の対応に期待したい。
4.まとめ
ADBについて最近学んだことをベースに、現在私の関わっているシステムへADBはどの程度使えるのかを考察してみたが、やはり今の運用を変えずに移行するのは難しいと感じた。クラウドサービスをベースに運用を見直す前提で考え直す必要があるので、まずそこのハードルをクリアできるかがポイントと感じる。私の感覚として、変わらないことを是とする企業風土の中では、このハードルは決して低いものではない。この他、文字コードやDBLINKに関しては、現時点では厳しい制約がある点もあることがわかった。このような技術的な問題については、クラウドサービスの拡充に伴い解消していくのではという期待もあるので、今後も継続して注視していきたいと思う。なお、本記事内容は現時点で私が知ったことをベースに記載しているため、正確でない部分があるかもしれない旨、ご容赦頂きたい。
以上
2020-09-07 01:21
ORA-4036でPGA_AGGREGATE_LIMITを上げた話 [アーキテクチャ]
いつになっても夜に電話で起こされるのは辛いものである。先日も夜にORA-4036が出た!と電話がかかってきた。状況はこうである。夜ORA-4036が出た。他に業務影響は出ていない。どんな状況なのかわからない。翌営対応とはいえPGAのことが頭から離れない。明日どう対応しようか、切り分けするためにはどのような方法がよいのか、そもそも原因は何なのだろうか、、、コロナによる外出規制は解除になったものの、なかなか商用環境に触れない状況は続いており、その限られた時間で結果を出さなければならない、と思うと不安は募るばかりである。
この状況で翌日どう考え対処したか、をメモしておく。
ORA-4036はPGA_AGGREGATE_LIMITを超えたことを示すエラーである。PGAは通常セッションが終了すれば解放されるため、おそらくその時間帯になんらかの負荷の高い処理、特にソートやハッシュ結合を伴う処理が行われたのに違いない。したがって、明日調査確認すべきは、まずDBの正常性を確認することである。監視(EnterpriseManager)で問題が検出されていないこと、PGAの空きが十分確保されていることである。次に問題のあった時間帯の原因となるSQLの特定である。業務APまたは運用作業のSQLを特定できれば、あとは試験環境で再現させ、どう修正するか、という議論ができるようになる。ここまでが私が頭におおまかに描いていた障害対応のシナリオだった。朝の出かける前に、PGAの情報取得について書籍[1]でAWRレポートのPGAセクションの確認ポイントを予習しておく。現場での引き出しは少しでも多いほうがよい。
しかし現実は思い通りにならないものである。朝は予定通り、まず正常性確認から始めた。EMの画面でオールグリーンであることを確認する。問題ないのは想定通りである。次にv$pgastatを確認した。これはPGAの状態を確認する動的パフォーマンスビューであり、現在アロケート済みのPGAサイズ"total PGA allocated"が確認できる。通常はこのサイズがpga_aggregate_limitのパラメータ値よりずっと小さいはずである。しかし、実際はほぼ同じ値(pga_aggregate_limitの9割以上のサイズ)であった。こうなると、一過性の問題と考えることはできない。いつ、このタイミングでも、ソート処理を行うバッチが流れれば、ORA-4036で異常終了するかもしれない、という状況である。この時点で、早くも私が思い描いていたシナリオは崩れ去ったのである。
ここで、具体的にv$pgastatの結果がどんなものか確認しておこう。以下は手元のノートPC上のVMの環境での実行結果、バージョンは19.3である。下記の例であれば、total PGA allocatedが現在のPGA利用サイズ267MB(★1)に対し、ハードリミットであるpga_aggregate_limitが2GB(★2)なので、ORA-4036発生まで十分余裕があることがわかる。
さて、PGAが高止まりしているということは何らかのサーバープロセスが掴み続けているということである。では一体何のプロセスなのか。それを確認するにはv$processを見ればよい。意外なことにMMONのスレーブプロセス(m000などの5つ)がそれぞれ大きなPGAをアロケートしていることがわかった。そのサイズは1つのプロセスで4GB程度、5つの合計で20GB程度であった。ちなみにOracleのMMONはAWRのスナップショットを取得したりする管理系のバックグラウンドプロセスである。
ここで、v$processの例を見てみよう。私の手元の環境でPGAのアロケートサイズで降順にソートしている。この例ではM000~M004の4つのMMONスレーブプロセスがあり、その合計はたかだかが22MB程度である。
次にalert.logを確認する。事象発生時間に、「PGA_AGGREGATE_LIMITを超えたが、最もPGAを使っているプロセスはORA-4036の割り込みを受け取れるプロセスではないので、今後の発生はDBRMトレースファイルに記録する」旨のメッセージが出力されていた。DBRMのトレースと言われてもピンとこないが、同じディレクトリに確かにSID_dbrm_XXX.trcというトレースファイルがある。中を確認してみると、ORA-4036の発生したpidが記録されている。そして、psでこのpidを持つプロセスを探すと、m000というMMONのスレーブプロセスであった。
この挙動はリファレンスマニュアル[2]のPGA_AGGREGATE_LIMITパラメータのActions Taken When PGA_AGGREGATE_LIMIT is Exceededに記載されている(下記★の部分)。「most untunable memory」というのが、具体的にPGAをどう使っている状態なのかがイメージできないが、少なくともPGAを一番使っているプロセスは、LIMITに達すると制約を受け、最悪の場合はセッションが終了させられるように読み取れる。今回はバックグラウンドプロセスだったのでその制約を受けなかったが、通常の業務APであれば、セッション停止により異常終了するという事態になりかねない。
---
Actions Taken When PGA_AGGREGATE_LIMIT is Exceeded →PGA_AGGREGATE_LIMITを超えたときの挙動
Parallel queries will be treated as a unit. First, the sessions that are using the most untunable memory will have their calls aborted. Then, if the total PGA memory usage is still over the limit, the sessions that are using the most untunable memory will be terminated.
→パラレルクエリーは一つの単位として扱われる。一番チューニングできないメモリを使っているセッションは呼び出しを中止させられる。それでもPGAの使用量がリミットを超えていれば、そのセッションは停止させられる。
SYS processes and background processes other than job queue processes will not be subjected to any of the actions described in this section. Instead, if they are using the most untunable memory, they will periodically write a brief summary of their PGA usage to a trace file.
→★SYSプロセスとバックグラウンドプロセス(ジョブキュープロセス以外)は上記のアクションの対象外である。もしそれらが一番チューニングできないメモリを使っていたら、定期的にPGAの利用状況についてトレースファイルに出力する。
---
ここまでで大まかな状況と直接原因がわかったので、次は根本原因の特定である。MOSで19cの類似事象を確認し、以下の既知不具合を見つけた。(1)はMMONのスレーブプロセスがPGAを多く使ってしまう、という事象についてのドキュメントであり、その根本原因が(2)の不具合である。XMLFORESTを使う問い合わせでPGAを使ってしまうというもので、これは特にMMON固有という訳ではないようだ。ワークアラウンドとしてはeventを設定してインスタンスのバウンスとあるので、パッチは回避できそうであるものの、すぐには実施できない、ということもわかった。
(1)Standard Mmon Slave Process Using High PGA (Doc ID 2641033.1)
(2)Bug 30611650 : HIGH PGA USAGE FOR A QUERY USING XMLFOREST
※XMLFORESTとは以下のようにカラム名で問い合わせの結果をXML化する関数。詳細は[5]参照
ここまでの切り分けで午前中は終了。根本原因については上記の見立てが正しいかどうかサポートに問い合わせるとして、何よりもまず今の危険な状況を暫定対処する必要がある。ORA-4036の直接原因はPGA_AGGREGATE_LIMITに達したことによるものであるため、すぐに思いつくのはこの値を上げることである。方法としては以下の2通りがあると考えた。
案1:PGA_AGGREGATE_LIMITを上げる
例)alter system set pga_aggregate_limit=XXG
案2:PGA_AGGREGATE_LIMITを外す
例)alter system set pga_aggregate_limit=0;
案1の場合はMMONのスレーブプロセスの肥大化により本来使えるべきPGA領域が使えなくなっているので、その分を考慮して上げればよい。しかし、肥大化が続いているとすると、やがてまた同じこととなるので、あくまで時間稼ぎでしかない。一方、案2はPGAのハードリミット制御を止めてしまう、という対処であり、不測の処理の負荷増等でDBのメモリを使いきらないようなガードがなくなる。しかし、リファレンスマニュアル[2]を見ると以下のように記載があり、物理メモリサイズからSGAのサイズを引いた90%になるらしい。この場合Hugepageは考慮されるのか、とか挙動として若干不安な点もあるため、今回は結果として案1を選択し、値は案2と同じ結果になるように明示的に値を設定することとした。
---
Default value
... If MEMORY_TARGET is not set, and PGA_AGGREGATE_TARGET is explicitly set to 0, then the value of PGA_AGGREGATE_LIMIT is set to 90% of the physical memory size minus the total SGA size.
→もしMEMORY_TARGETが設定されておらず、PGA_AGGREGATE_TARGETが明示的に0に設定されていれば、PGA_AGGREGATE_LIMITは物理メモリサイズからSGAのサイズを引いた90%に設定される
---
続いて他のDBでも同様のことが発生していないかを確認する。同様に、v$pgastatとv$processを見るだけですぐ判断できるだろう。結果、同様のPGAの肥大化が発生していることと、幸運なことにそれほどPGA_AGGREGATE_LIMITのサイズまで切迫していない状況が確認できた。さらにリークの傾向を確認しなければならない。これが突発的に大きくなるものであれば、今大丈夫でも明日はダメかもしれないからである。pgastatの履歴はDBA_HIST_PGASTATで確認できる(前日夜に調べておいてよかった)。name列がtotal PGA allocatedのものだけを抜いて、結果をExcelに張り付け、snap_idを横軸、value列を縦軸にプロットすると、ゆるやかな右肩上がりのグラフになった。突発性の増加傾向はない。暫定対処する対象としては今回問題が発生したDBだけでも大丈夫だろうと判断した。
なお、手元の環境でのDBA_HIST_PGASTATの出力結果は以下の通りである。手元の環境では手動でsnap取得したが、通常であればAWRは定期的(30分や1時間おき)に取得されているだろうから、これで過去から現在までのPGAのアロケート済みサイズの推移が確認できる。なお、RACならINSTANCE_NUMBER毎に集計することは言うまでもない。
平行してサポートから、事象が発生した時間帯のash(dba_hist_active_sess_history)から、MMONが発行していたSQL_IDが特定ができたとの連絡があった。v$sqlからこのsql_idのsql_fulltextを抜き、内容を確認すると、果たしてリークする条件となるXMLFORESTを使っていることが判明した。この不具合に合致することはほぼ間違いないだろう、あとはサポートの裏どりだけだ。
ここまでの対応で1日が終了。とりあえず枕を高くして眠ることができる状態までにはできた。しかしまだ暫定対処が終わっただけであり、根本対処をどうするか、という話はこれからである。ORA-4036は避けられる状態にはなったがMMONスレーブプロセスは大きいままである。インスタンスバウンスは避けたいが、プロセスは小さくしたい。少し調べてみた限り、DBを一度制限モードにすることでMMONプロセスを再起動できる方法があるらしいとわかった。しかし、制限モードにすると既存セッションはkillされてしまう[3]ため、実質的にバウンスと大差ない。コミュニティではMMONをkillすれば自動起動する、という意見もある[4]が、サポートされない上に、起動に失敗する不具合(Doc ID 2023652.1)があったりと、勧められる方法ではないだろう。
なお、手元の環境で制限モードにしてみたところ、MMONだけでなく、そのスレーブプロセスも再起動されることは確認できた(pidが変更されていることから明らか)。★の部分で数秒待たされたので、セッションが多い場合はそれなりに時間がかかるだろう。お試しならともかく、商用でやることはあまり想像できない。当面、様子見しかないのだろうか。
今回の経験を通し、PGA_AGGREGATE_LIMITの設計はそもそもどうあるべきかを考えさせられる。いままで、デフォルトでPGA_AGGREGATE_TARGETの2倍になるので、上限としては十分余裕がある設計になっていると思っていた。今回の場合もバックグラウンドプロセスによるPGA肥大化が起きなければ問題はなかっただろう。しかし、そもそもオンプレの場合、OSの上限まで余裕があるにも関わらず、クエリが異常終了する、ということを望むことは少ないだろう。その意味では0に設定する、またはSGA(Hugepage)サイズを除いたユーザ領域のサイズに対し、若干の安全率を残した値を明示的に設定するという考え方でもよいように思う。あえて2倍という中途半端なリミットを設けることに意味はないのではないか。この機能はむしろDB統合やクラウドなど、複数DBでリソースをシェアする状況において、それぞれのリソース制限をかけたい場合に積極的に活用すべきだろうと思う。
◆参考
[1]Oracle Database Problem Solving and Troubleshooting Handbook (English Edition),pp.240-244
[2]Database Reference 19c, PGA_AGGREGATE_LIMIT
[3]Database Administrator’s Guide, Restricting Access to an Open Database
[4]Is it possible to explicitly restart MMON without bouncing a database?
[5]SQL Language Reference, XMLFOREST
以上
この状況で翌日どう考え対処したか、をメモしておく。
ORA-4036はPGA_AGGREGATE_LIMITを超えたことを示すエラーである。PGAは通常セッションが終了すれば解放されるため、おそらくその時間帯になんらかの負荷の高い処理、特にソートやハッシュ結合を伴う処理が行われたのに違いない。したがって、明日調査確認すべきは、まずDBの正常性を確認することである。監視(EnterpriseManager)で問題が検出されていないこと、PGAの空きが十分確保されていることである。次に問題のあった時間帯の原因となるSQLの特定である。業務APまたは運用作業のSQLを特定できれば、あとは試験環境で再現させ、どう修正するか、という議論ができるようになる。ここまでが私が頭におおまかに描いていた障害対応のシナリオだった。朝の出かける前に、PGAの情報取得について書籍[1]でAWRレポートのPGAセクションの確認ポイントを予習しておく。現場での引き出しは少しでも多いほうがよい。
しかし現実は思い通りにならないものである。朝は予定通り、まず正常性確認から始めた。EMの画面でオールグリーンであることを確認する。問題ないのは想定通りである。次にv$pgastatを確認した。これはPGAの状態を確認する動的パフォーマンスビューであり、現在アロケート済みのPGAサイズ"total PGA allocated"が確認できる。通常はこのサイズがpga_aggregate_limitのパラメータ値よりずっと小さいはずである。しかし、実際はほぼ同じ値(pga_aggregate_limitの9割以上のサイズ)であった。こうなると、一過性の問題と考えることはできない。いつ、このタイミングでも、ソート処理を行うバッチが流れれば、ORA-4036で異常終了するかもしれない、という状況である。この時点で、早くも私が思い描いていたシナリオは崩れ去ったのである。
ここで、具体的にv$pgastatの結果がどんなものか確認しておこう。以下は手元のノートPC上のVMの環境での実行結果、バージョンは19.3である。下記の例であれば、total PGA allocatedが現在のPGA利用サイズ267MB(★1)に対し、ハードリミットであるpga_aggregate_limitが2GB(★2)なので、ORA-4036発生まで十分余裕があることがわかる。
SQL> select * from v$pgastat; NAME VALUE UNIT CON_ID ---------------------------------------- ---------- ------------ ---------- aggregate PGA target parameter 209715200 bytes 0 aggregate PGA auto target 13107200 bytes 0 global memory bound 41943040 bytes 0 total PGA inuse 240287744 bytes 0 total PGA allocated 280586240 bytes 0★1 maximum PGA allocated 456682496 bytes 0 total freeable PGA memory 16908288 bytes 0 MGA allocated (under PGA) 0 bytes 0 maximum MGA allocated 0 bytes 0 process count 107 0 max processes count 121 0 PGA memory freed back to OS 169869312 bytes 0 total PGA used for auto workareas 0 bytes 0 maximum PGA used for auto workareas 5061632 bytes 0 total PGA used for manual workareas 0 bytes 0 maximum PGA used for manual workareas 0 bytes 0 over allocation count 152 0 bytes processed 220843008 bytes 0 extra bytes read/written 0 bytes 0 cache hit percentage 100 percent 0 recompute count (total) 155 0 21 rows selected. SQL> show parameter pga_aggregate_limit NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ pga_aggregate_limit big integer 2G ★2 SQL>
さて、PGAが高止まりしているということは何らかのサーバープロセスが掴み続けているということである。では一体何のプロセスなのか。それを確認するにはv$processを見ればよい。意外なことにMMONのスレーブプロセス(m000などの5つ)がそれぞれ大きなPGAをアロケートしていることがわかった。そのサイズは1つのプロセスで4GB程度、5つの合計で20GB程度であった。ちなみにOracleのMMONはAWRのスナップショットを取得したりする管理系のバックグラウンドプロセスである。
ここで、v$processの例を見てみよう。私の手元の環境でPGAのアロケートサイズで降順にソートしている。この例ではM000~M004の4つのMMONスレーブプロセスがあり、その合計はたかだかが22MB程度である。
SQL> select program, pga_alloc_mem,pga_freeable_mem from v$process order by 2 desc PROGRAM PGA_ALLOC_MEM PGA_FREEABLE_MEM ------------------------------------------------ ------------- ---------------- oracle@localhost.localdomain (TT00) 20610133 0 oracle@localhost.localdomain (DBW0) 13769925 3735552 oracle@localhost.localdomain (M001) 11893845 6094848★ oracle@localhost.localdomain (MMON) 9537069 4259840 oracle@localhost.localdomain (M000) 6764981 2293760★ oracle@localhost.localdomain (CJQ0) 5932589 1572864 ・・・ oracle@localhost.localdomain (W002) 2128981 0 oracle@localhost.localdomain (M003) 2128981 0★ oracle@localhost.localdomain (DIAG) 2123101 0 ・・・ oracle@localhost.localdomain (W000) 1932373 0 oracle@localhost.localdomain (M002) 1932373 0★ oracle@localhost.localdomain (SCMN) 1932373 0 ・・・ 88 rows selected.
次にalert.logを確認する。事象発生時間に、「PGA_AGGREGATE_LIMITを超えたが、最もPGAを使っているプロセスはORA-4036の割り込みを受け取れるプロセスではないので、今後の発生はDBRMトレースファイルに記録する」旨のメッセージが出力されていた。DBRMのトレースと言われてもピンとこないが、同じディレクトリに確かにSID_dbrm_XXX.trcというトレースファイルがある。中を確認してみると、ORA-4036の発生したpidが記録されている。そして、psでこのpidを持つプロセスを探すと、m000というMMONのスレーブプロセスであった。
alert_SID.log PGA_AGGREGATE_LIMIT has been exceeded but some processes using the most PGA memory are not eligible to receive ORA-4036 interrupts. Further occurrences of this condition will be written to the trace file of the DBRM process. SID_dbrm_XXX.trc PGA LIMIT: pid XXX is a top contributor to going over PGA_AGGREGATE_LIMIT PGA LIMIT: pid XXX is ineligible for an ORA-4036 interrupt System processes and most backgroud processes cannot receive ORA-4036 interrupts. When they are contributing to the instance exceeding PGA_AGGREGATE_LIMIT, they will periodically dump their PGA usage.
この挙動はリファレンスマニュアル[2]のPGA_AGGREGATE_LIMITパラメータのActions Taken When PGA_AGGREGATE_LIMIT is Exceededに記載されている(下記★の部分)。「most untunable memory」というのが、具体的にPGAをどう使っている状態なのかがイメージできないが、少なくともPGAを一番使っているプロセスは、LIMITに達すると制約を受け、最悪の場合はセッションが終了させられるように読み取れる。今回はバックグラウンドプロセスだったのでその制約を受けなかったが、通常の業務APであれば、セッション停止により異常終了するという事態になりかねない。
---
Actions Taken When PGA_AGGREGATE_LIMIT is Exceeded →PGA_AGGREGATE_LIMITを超えたときの挙動
Parallel queries will be treated as a unit. First, the sessions that are using the most untunable memory will have their calls aborted. Then, if the total PGA memory usage is still over the limit, the sessions that are using the most untunable memory will be terminated.
→パラレルクエリーは一つの単位として扱われる。一番チューニングできないメモリを使っているセッションは呼び出しを中止させられる。それでもPGAの使用量がリミットを超えていれば、そのセッションは停止させられる。
SYS processes and background processes other than job queue processes will not be subjected to any of the actions described in this section. Instead, if they are using the most untunable memory, they will periodically write a brief summary of their PGA usage to a trace file.
→★SYSプロセスとバックグラウンドプロセス(ジョブキュープロセス以外)は上記のアクションの対象外である。もしそれらが一番チューニングできないメモリを使っていたら、定期的にPGAの利用状況についてトレースファイルに出力する。
---
ここまでで大まかな状況と直接原因がわかったので、次は根本原因の特定である。MOSで19cの類似事象を確認し、以下の既知不具合を見つけた。(1)はMMONのスレーブプロセスがPGAを多く使ってしまう、という事象についてのドキュメントであり、その根本原因が(2)の不具合である。XMLFORESTを使う問い合わせでPGAを使ってしまうというもので、これは特にMMON固有という訳ではないようだ。ワークアラウンドとしてはeventを設定してインスタンスのバウンスとあるので、パッチは回避できそうであるものの、すぐには実施できない、ということもわかった。
(1)Standard Mmon Slave Process Using High PGA (Doc ID 2641033.1)
(2)Bug 30611650 : HIGH PGA USAGE FOR A QUERY USING XMLFOREST
※XMLFORESTとは以下のようにカラム名で問い合わせの結果をXML化する関数。詳細は[5]参照
SQL> select xmlforest(dummy) from dual; XMLFOREST(DUMMY) ----------------X
ここまでの切り分けで午前中は終了。根本原因については上記の見立てが正しいかどうかサポートに問い合わせるとして、何よりもまず今の危険な状況を暫定対処する必要がある。ORA-4036の直接原因はPGA_AGGREGATE_LIMITに達したことによるものであるため、すぐに思いつくのはこの値を上げることである。方法としては以下の2通りがあると考えた。
案1:PGA_AGGREGATE_LIMITを上げる
例)alter system set pga_aggregate_limit=XXG
案2:PGA_AGGREGATE_LIMITを外す
例)alter system set pga_aggregate_limit=0;
案1の場合はMMONのスレーブプロセスの肥大化により本来使えるべきPGA領域が使えなくなっているので、その分を考慮して上げればよい。しかし、肥大化が続いているとすると、やがてまた同じこととなるので、あくまで時間稼ぎでしかない。一方、案2はPGAのハードリミット制御を止めてしまう、という対処であり、不測の処理の負荷増等でDBのメモリを使いきらないようなガードがなくなる。しかし、リファレンスマニュアル[2]を見ると以下のように記載があり、物理メモリサイズからSGAのサイズを引いた90%になるらしい。この場合Hugepageは考慮されるのか、とか挙動として若干不安な点もあるため、今回は結果として案1を選択し、値は案2と同じ結果になるように明示的に値を設定することとした。
---
Default value
... If MEMORY_TARGET is not set, and PGA_AGGREGATE_TARGET is explicitly set to 0, then the value of PGA_AGGREGATE_LIMIT is set to 90% of the physical memory size minus the total SGA size.
→もしMEMORY_TARGETが設定されておらず、PGA_AGGREGATE_TARGETが明示的に0に設定されていれば、PGA_AGGREGATE_LIMITは物理メモリサイズからSGAのサイズを引いた90%に設定される
---
続いて他のDBでも同様のことが発生していないかを確認する。同様に、v$pgastatとv$processを見るだけですぐ判断できるだろう。結果、同様のPGAの肥大化が発生していることと、幸運なことにそれほどPGA_AGGREGATE_LIMITのサイズまで切迫していない状況が確認できた。さらにリークの傾向を確認しなければならない。これが突発的に大きくなるものであれば、今大丈夫でも明日はダメかもしれないからである。pgastatの履歴はDBA_HIST_PGASTATで確認できる(前日夜に調べておいてよかった)。name列がtotal PGA allocatedのものだけを抜いて、結果をExcelに張り付け、snap_idを横軸、value列を縦軸にプロットすると、ゆるやかな右肩上がりのグラフになった。突発性の増加傾向はない。暫定対処する対象としては今回問題が発生したDBだけでも大丈夫だろうと判断した。
なお、手元の環境でのDBA_HIST_PGASTATの出力結果は以下の通りである。手元の環境では手動でsnap取得したが、通常であればAWRは定期的(30分や1時間おき)に取得されているだろうから、これで過去から現在までのPGAのアロケート済みサイズの推移が確認できる。なお、RACならINSTANCE_NUMBER毎に集計することは言うまでもない。
SQL> select * from dba_hist_pgastat where name ='total PGA allocated' order by snap_id;
★SNAP_ID DBID ★INSTANCE_NUMBER NAME ★VALUE CON_DBID CON_ID
---------- ---------- --------------- ------------------------------ ---------- ---------- ----------
112 2780785463 1 total PGA allocated 380929024 2780785463 0
113 2780785463 1 total PGA allocated 223073280 2780785463 0
114 2780785463 1 total PGA allocated 223990784 2780785463 0
115 2780785463 1 total PGA allocated 262359040 2780785463 0
116 2780785463 1 total PGA allocated 263014400 2780785463 0
117 2780785463 1 total PGA allocated 263014400 2780785463 0
118 2780785463 1 total PGA allocated 263014400 2780785463 0
119 2780785463 1 total PGA allocated 286373888 2780785463 0
120 2780785463 1 total PGA allocated 284532736 2780785463 0
121 2780785463 1 total PGA allocated 248374272 2780785463 0
122 2780785463 1 total PGA allocated 202958848 2780785463 0
123 2780785463 1 total PGA allocated 229661696 2780785463 0
124 2780785463 1 total PGA allocated 208464896 2780785463 0
125 2780785463 1 total PGA allocated 265885696 2780785463 0
126 2780785463 1 total PGA allocated 253380608 2780785463 0
127 2780785463 1 total PGA allocated 216879104 2780785463 0
128 2780785463 1 total PGA allocated 236321792 2780785463 0
平行してサポートから、事象が発生した時間帯のash(dba_hist_active_sess_history)から、MMONが発行していたSQL_IDが特定ができたとの連絡があった。v$sqlからこのsql_idのsql_fulltextを抜き、内容を確認すると、果たしてリークする条件となるXMLFORESTを使っていることが判明した。この不具合に合致することはほぼ間違いないだろう、あとはサポートの裏どりだけだ。
ここまでの対応で1日が終了。とりあえず枕を高くして眠ることができる状態までにはできた。しかしまだ暫定対処が終わっただけであり、根本対処をどうするか、という話はこれからである。ORA-4036は避けられる状態にはなったがMMONスレーブプロセスは大きいままである。インスタンスバウンスは避けたいが、プロセスは小さくしたい。少し調べてみた限り、DBを一度制限モードにすることでMMONプロセスを再起動できる方法があるらしいとわかった。しかし、制限モードにすると既存セッションはkillされてしまう[3]ため、実質的にバウンスと大差ない。コミュニティではMMONをkillすれば自動起動する、という意見もある[4]が、サポートされない上に、起動に失敗する不具合(Doc ID 2023652.1)があったりと、勧められる方法ではないだろう。
なお、手元の環境で制限モードにしてみたところ、MMONだけでなく、そのスレーブプロセスも再起動されることは確認できた(pidが変更されていることから明らか)。★の部分で数秒待たされたので、セッションが多い場合はそれなりに時間がかかるだろう。お試しならともかく、商用でやることはあまり想像できない。当面、様子見しかないのだろうか。
[oracle@localhost ~]$ ps -ef | grep mmon oracle 7097 1 0 07:17 ? 00:00:05 ora_mmon_orclcdb oracle 28559 18645 0 11:53 pts/2 00:00:00 grep --color=auto mmon [oracle@localhost ~]$ ps -ef | grep m00 oracle 27386 1 0 11:34 ? 00:00:01 ora_m000_orclcdb oracle 27395 1 0 11:34 ? 00:00:01 ora_m002_orclcdb oracle 27808 1 0 11:40 ? 00:00:00 ora_m001_orclcdb oracle 28035 1 0 11:44 ? 00:00:00 ora_m004_orclcdb oracle 28568 18645 0 11:53 pts/2 00:00:00 grep --color=auto m00 [oracle@localhost ~]$ sqlplus / as sysdba SQL*Plus: Release 19.0.0.0.0 - Production on Thu May 28 11:54:02 2020 Version 19.3.0.0.0 Copyright (c) 1982, 2019, Oracle. All rights reserved. Connected to: Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Version 19.3.0.0.0 SQL> grant restricted session to public; Grant succeeded. SQL> alter system enable restricted session; ★ System altered. SQL> alter system disable restricted session; System altered. SQL> revoke restricted session from public; Revoke succeeded. SQL> exit Disconnected from Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Version 19.3.0.0.0 [oracle@localhost ~]$ ps -ef | grep mmon oracle 28639 1 0 11:54 ? 00:00:00 ora_mmon_orclcdb oracle 28733 18645 0 11:55 pts/2 00:00:00 grep --color=auto mmon [oracle@localhost ~]$ ps -ef | grep m00 oracle 28644 1 0 11:54 ? 00:00:00 ora_m000_orclcdb oracle 28646 1 0 11:54 ? 00:00:00 ora_m001_orclcdb oracle 28648 1 0 11:54 ? 00:00:00 ora_m002_orclcdb oracle 28676 1 0 11:54 ? 00:00:00 ora_m003_orclcdb oracle 28701 1 0 11:54 ? 00:00:00 ora_m004_orclcdb oracle 28745 18645 0 11:55 pts/2 00:00:00 grep --color=auto m00 [oracle@localhost ~]$
今回の経験を通し、PGA_AGGREGATE_LIMITの設計はそもそもどうあるべきかを考えさせられる。いままで、デフォルトでPGA_AGGREGATE_TARGETの2倍になるので、上限としては十分余裕がある設計になっていると思っていた。今回の場合もバックグラウンドプロセスによるPGA肥大化が起きなければ問題はなかっただろう。しかし、そもそもオンプレの場合、OSの上限まで余裕があるにも関わらず、クエリが異常終了する、ということを望むことは少ないだろう。その意味では0に設定する、またはSGA(Hugepage)サイズを除いたユーザ領域のサイズに対し、若干の安全率を残した値を明示的に設定するという考え方でもよいように思う。あえて2倍という中途半端なリミットを設けることに意味はないのではないか。この機能はむしろDB統合やクラウドなど、複数DBでリソースをシェアする状況において、それぞれのリソース制限をかけたい場合に積極的に活用すべきだろうと思う。
◆参考
[1]Oracle Database Problem Solving and Troubleshooting Handbook (English Edition),pp.240-244
[2]Database Reference 19c, PGA_AGGREGATE_LIMIT
[3]Database Administrator’s Guide, Restricting Access to an Open Database
[4]Is it possible to explicitly restart MMON without bouncing a database?
[5]SQL Language Reference, XMLFOREST
以上
2020-05-29 12:25
log file syncのトラブルシューティング [アーキテクチャ]
現場で発生したlog file syncの性能遅延をトラシューしたときのメモである。2019年9月に一度上げたが、解析が誤っていたためいったん記事を取り下げたもののリバイスした。
ある日、業務チームか性能遅延解析依頼があった。内容はlog file syncが大量発生して性能遅延が発生しているみたいなので、見て欲しいということであった。AWRを見ると、なるほど確かにlog file syncが待機イベントの上位(トップ)に来ていた。ちなみに、この業務は現行でも動いているもので、このような待機は出ていない。現行はOracle11.1で30分程度の処理が、この問題発生しているOracle19.2 (Exadata)の環境では110分以上かかっており、そのほとんど(80%以上)がlog file syncで占められており、1待機あたりのレイテンシは50msecを越えるという、とてつもなく遅い状態であった。
問題のAPは、以下の特徴を持っていた。
・母体テーブルの中から処理対象レコードに対して1件ずつループ処理を行う
・ループ処理の中で母体テーブルの更新と、dblink越しに他DBへの更新を行う
・1ループ毎にコミットする(母体、他DBともに1件ずつのコミット)
1件ずつコミットする、というAPのつくりはOracle的にはイマイチではあるが、それはそれで現行では性能要件を満たして動いている訳なので、ここでは特に問題視はしていない。問題は、なぜ19cでは同じAPがこれだけlog file syncで待機してしまうのか、ということである。ちなみに、事象を再現させるためのサンプルAPで、dblink越しの更新を行わないよう変更すると、log file syncによる遅延事象は発生しなかった。
この記事を読んでいる方には言うまでもないと思うが、log file syncとはLGWR(ログライター)がログバッファに書き込んだredoチェンジベクターをREDOログファイルに書き込む際に発生する待機である。具体的にはサーバプロセスがコミットを発行しLGWRに書き込み要求をしてから、書き込み完了を受け取るまでの待機である。このうち、純粋にディスクへの書き込み(I/O)に要した待機はlog file parallel write待機イベントである。
log file sync待機の原因にはさまざまな要因が考えられる。一番明らかなのは、REDOログファイルへの書き込みが純粋に遅い場合である。プアなストレージや3rdベンダのストレージとの相性問題を心配するような状況では被疑箇所として考えられるが、今回の場合はExadataであり、REDOログファイルへの書き込みはフラッシュキャッシュで折り返されるため、これが原因とは考えにくい。実際、log file parallel write待機はほとんど発生していないし、レイテンシも良好であった。
次に考えられるのは、頻繁なREDOログファイルスイッチによる影響である。限りあるREDOログファイルが一巡してしまうと、アーカイブログに出力されるまではREDOログへの上書きができなく待機が発生する場合がある。しかし、今回の場合は十分に大きなREDOログファイルとしていたため、これが原因とは考えられない。実際、ログスイッチが何度も発生していないことはAWRやアーカイブログを見ても明らかである。
一般的にはAPのつくりもlog file sync待機の要因となる。log file syncはコミットを発行する度に発生する待機イベントであり、コミットしないAPはないことから、ある意味、log file syncの発生自体が問題ではない。問題はこれが多発することによりそのオーバーヘッドによりAPが本来の性能を出せないことが問題なのだ。従って、たとえば10000件単位にコミットするようにAPを改修すれば、当然待機イベントを減らせるし、待機時間も減らせる。今回のケースでも確かに有効ではあろう。しかし、問題の本質は待機回数ではなく、待機時間、つまり1コミットあたりのレイテンシが19.2では極端に遅いという事象であると考えられるため、これは本質的な解決になっていない。
とすると、他は何か。。。LGWR周りで考えられるのは以下2つの機能である。
(1)adaptive log file sync ・・・従来LGWRへの書き込み要求はpost/wait方式(書き込み要求を出してLGWRが完了を通知する方式)であったが、新しくpolling方式(書き込み要求を出して、要求を出した側が再びLGWRに完了を確認する方式)が使えるようになった。11.2.0.3よりデフォルトで有効(2つの方式をLGWRの負荷に応じて動的に切り替える)ようになっている。_use_adaptive_log_file_syncで制御可能(MOS1541136.1参照)
(2)scalable log writer ・・・従来はLGWRはシングルプロセスで動作していたが、LGWRのI/O処理をパラレルで実行できるよう、複数のワーカープロセス(LGnn)を立ち上げ、REDOログファイルへのI/Oを複数のCPUで分散して処理する方式が使えるようになった。12.1から、LGWRへの負荷に応じて動的に従来の方式とを切り替えるようになっている。_use_single_log_writerパラメータで制御可能
どちらの方式も、ポイントは動的に切り替わるという点である。LGWRのトレースログを見ると、確かに切り替わった痕跡が確認できるが、その理由、つまり切り替わりの条件がわからないのである。従って、性能試験をする中では問題なくても、運用中になんらかの条件で切り替わったことにより性能への影響が発生することがあり得るということである。もちろん、通常はポジティブな効果が得られ運用は楽になるのかもしれない。しかし逆の場合、トラシューは困難となり、また、運用中にこれを変更することは、DBの根幹に影響するプロセスだけに慎重にならざるを得ない。いずれにしても、どちらもWriteインテンシブな使い方を想定した機能改善だとは思うが、これが有効に働くケースを見極める必要がある。
なお、上記の解析をするにあたり、新久保氏によるJPOUGの講演資料は非常に参考になった。上記2つのような重要なアーキテクチャ上の変更を2013年に既に気付き、課題としてコミュニティに対して提起していた点は大変有意義なことと思うし、自分も見習いたいと感じた。以前のJPOUGの懇親会でお話させていただいたが、この場を借りてお礼申し上げたい。
結局、本事象はサポートの解析の結果、製品不具合であることが判明したが、このlog file syncのトラシューを通し、OracleのREDOの仕組みは枯れたアーキテクチャではなく、バージョンが上がるにつれ確実に改良されてきていることがよく分かった。
以上
ある日、業務チームか性能遅延解析依頼があった。内容はlog file syncが大量発生して性能遅延が発生しているみたいなので、見て欲しいということであった。AWRを見ると、なるほど確かにlog file syncが待機イベントの上位(トップ)に来ていた。ちなみに、この業務は現行でも動いているもので、このような待機は出ていない。現行はOracle11.1で30分程度の処理が、この問題発生しているOracle19.2 (Exadata)の環境では110分以上かかっており、そのほとんど(80%以上)がlog file syncで占められており、1待機あたりのレイテンシは50msecを越えるという、とてつもなく遅い状態であった。
問題のAPは、以下の特徴を持っていた。
・母体テーブルの中から処理対象レコードに対して1件ずつループ処理を行う
・ループ処理の中で母体テーブルの更新と、dblink越しに他DBへの更新を行う
・1ループ毎にコミットする(母体、他DBともに1件ずつのコミット)
1件ずつコミットする、というAPのつくりはOracle的にはイマイチではあるが、それはそれで現行では性能要件を満たして動いている訳なので、ここでは特に問題視はしていない。問題は、なぜ19cでは同じAPがこれだけlog file syncで待機してしまうのか、ということである。ちなみに、事象を再現させるためのサンプルAPで、dblink越しの更新を行わないよう変更すると、log file syncによる遅延事象は発生しなかった。
この記事を読んでいる方には言うまでもないと思うが、log file syncとはLGWR(ログライター)がログバッファに書き込んだredoチェンジベクターをREDOログファイルに書き込む際に発生する待機である。具体的にはサーバプロセスがコミットを発行しLGWRに書き込み要求をしてから、書き込み完了を受け取るまでの待機である。このうち、純粋にディスクへの書き込み(I/O)に要した待機はlog file parallel write待機イベントである。
log file sync待機の原因にはさまざまな要因が考えられる。一番明らかなのは、REDOログファイルへの書き込みが純粋に遅い場合である。プアなストレージや3rdベンダのストレージとの相性問題を心配するような状況では被疑箇所として考えられるが、今回の場合はExadataであり、REDOログファイルへの書き込みはフラッシュキャッシュで折り返されるため、これが原因とは考えにくい。実際、log file parallel write待機はほとんど発生していないし、レイテンシも良好であった。
次に考えられるのは、頻繁なREDOログファイルスイッチによる影響である。限りあるREDOログファイルが一巡してしまうと、アーカイブログに出力されるまではREDOログへの上書きができなく待機が発生する場合がある。しかし、今回の場合は十分に大きなREDOログファイルとしていたため、これが原因とは考えられない。実際、ログスイッチが何度も発生していないことはAWRやアーカイブログを見ても明らかである。
一般的にはAPのつくりもlog file sync待機の要因となる。log file syncはコミットを発行する度に発生する待機イベントであり、コミットしないAPはないことから、ある意味、log file syncの発生自体が問題ではない。問題はこれが多発することによりそのオーバーヘッドによりAPが本来の性能を出せないことが問題なのだ。従って、たとえば10000件単位にコミットするようにAPを改修すれば、当然待機イベントを減らせるし、待機時間も減らせる。今回のケースでも確かに有効ではあろう。しかし、問題の本質は待機回数ではなく、待機時間、つまり1コミットあたりのレイテンシが19.2では極端に遅いという事象であると考えられるため、これは本質的な解決になっていない。
とすると、他は何か。。。LGWR周りで考えられるのは以下2つの機能である。
(1)adaptive log file sync ・・・従来LGWRへの書き込み要求はpost/wait方式(書き込み要求を出してLGWRが完了を通知する方式)であったが、新しくpolling方式(書き込み要求を出して、要求を出した側が再びLGWRに完了を確認する方式)が使えるようになった。11.2.0.3よりデフォルトで有効(2つの方式をLGWRの負荷に応じて動的に切り替える)ようになっている。_use_adaptive_log_file_syncで制御可能(MOS1541136.1参照)
(2)scalable log writer ・・・従来はLGWRはシングルプロセスで動作していたが、LGWRのI/O処理をパラレルで実行できるよう、複数のワーカープロセス(LGnn)を立ち上げ、REDOログファイルへのI/Oを複数のCPUで分散して処理する方式が使えるようになった。12.1から、LGWRへの負荷に応じて動的に従来の方式とを切り替えるようになっている。_use_single_log_writerパラメータで制御可能
どちらの方式も、ポイントは動的に切り替わるという点である。LGWRのトレースログを見ると、確かに切り替わった痕跡が確認できるが、その理由、つまり切り替わりの条件がわからないのである。従って、性能試験をする中では問題なくても、運用中になんらかの条件で切り替わったことにより性能への影響が発生することがあり得るということである。もちろん、通常はポジティブな効果が得られ運用は楽になるのかもしれない。しかし逆の場合、トラシューは困難となり、また、運用中にこれを変更することは、DBの根幹に影響するプロセスだけに慎重にならざるを得ない。いずれにしても、どちらもWriteインテンシブな使い方を想定した機能改善だとは思うが、これが有効に働くケースを見極める必要がある。
なお、上記の解析をするにあたり、新久保氏によるJPOUGの講演資料は非常に参考になった。上記2つのような重要なアーキテクチャ上の変更を2013年に既に気付き、課題としてコミュニティに対して提起していた点は大変有意義なことと思うし、自分も見習いたいと感じた。以前のJPOUGの懇親会でお話させていただいたが、この場を借りてお礼申し上げたい。
結局、本事象はサポートの解析の結果、製品不具合であることが判明したが、このlog file syncのトラシューを通し、OracleのREDOの仕組みは枯れたアーキテクチャではなく、バージョンが上がるにつれ確実に改良されてきていることがよく分かった。
以上


