Oracle19cでメンテナンスウィンドウのCPU高騰をチューニングした話 [アーキテクチャ]
OCIのBaseDB(Oracle19c)でメンテナンスウィンドウ時間帯のCPU高騰をチューニングしたので、メモを残しておく。結論から言うと、統計情報取得処理の中で、カラム統計の保留統計を削除するdelete文(5hud5urmn39bx)の実行計画が非効率だったので、SQLパッチを適用して回避したという話である。以下、事象、原因、対処について簡単に記載する。
OCIのBaseDB(19.11)で、メンテナンス時間帯にDBサーバのCPU使用率がかなり上がっていることが問題になっていた。メンテナンスウィンドウは平日7時~11時までに設定されていたが、メンテナンス時間中に複数のPDBで同時に以下のSQLが長時間化しており、CPUをほぼ使い切ってしまっている状況であった。
wri$_optstat_histhead_history表は、日次のパーティション表で、カラム統計のバックアップを保持する。通常はSAVTIMEはバックアップ日時が入るが、保留統計を使っている場合は、テーブル毎、カラム毎にSAVTIME=3000年12月1日で記録される。つまり、保留統計は全て同じパーティションに入る。
このdelete文は、savtime, obj#, intcol#の3つのプレディケートで削除対象を特定し、(保留)統計情報取得の際に、不要となった保留統計情報を削除していると思われる。様々な表のカラム統計が全く同じSAVTIMEで記録されるため、ある表の保留統計のレコードを識別するためにSAVTIMEでは絞り込めない。このため、表の数が増えてくると、保留統計取得に伴う過去カラム統計の削除に時間がかかるようになるのである。
SQLの実行計画は以下の通り。
◆非効率な実行計画
グローバルファンクション索引I_WRI$_OPTSTAT_HH_STでsavtimeで絞り込み、obj#とintcol#でフィルタをかけて削除対象のレコードを特定していることがわかる。この実行計画だと、同じSAVTIMEを持つレコードの件数が多いと、フィルタの絞り込みに時間がかる。
AWRレポートから、SQLの実行回数は6,571で、平均実行時間は0.48秒、論理読み込みブロック数は8,196.7である。保留統計の削除は全てsavtimeが同一であることから、パーティションのフルスキャンを繰り返し、結果としてバッファキャッシュ上のブロック読み込みでCPUを使ってしまう。そして、この処理が複数PDB(メンテナンス時間が一緒)で並列実行されるため、DBサーバのCPUが上昇してしまう、という状況を作り出していたのだろう。
他に有効な索引がないか確認したところ、以下のようにI_WRI$_OPTSTAT_HH_OBJ_ICOL_STという索引があった。これはobj#、intcol#、SYS_NC00027$で構成されているので、savtimeだけの絞り込みより効果がありそうである。
ちなみにSYS_NC00027$は仮想列で、TIMESTAMP WITH TIME ZONE型のsavtimeから、UTC時間を取り出していることが確認できる。
このdelete文は統計情報取得のプロシージャ内部で発行されているため、直接ヒントは使えない。SQLパッチで直接SQL_IDを指定して、I_WRI$_OPTSTAT_HH_OBJ_ICOL_STの索引を使うように誘導する。
SQLパッチ作成には、SQL_IDがv$sqlに存在している必要がある。遅延が発生している状況であれば、メンテナンス時間帯またはその直後ならライブラリキャッシュに確認できるはずである。統計情報を手動で取得すればこのdelete文も内部から発行されるはずである。当該SQLパッチは、PDB毎に設定する必要がある点に注意が必要である(CDBに設定してもPDBには効果がない)。
SQLパッチを適用した後、実行計画を確認したところ、期待通りI_WRI$_OPTSTAT_HH_OBJ_ICOL_STの索引が使われている。こちらの実行計画では索引でobj#とsavtimeを絞り込んでから、savtimeとintcol#でフィルターする形になる(索引だけではsavtimeを絞り込み切れないため、フィルタにも現れていると思われる)。
◆改善後の実行計画
上記の状態で、後日メンテナンスウィンドウ時間帯のリソースを確認したところ、このDMLによるCPU張り付きの事象は解消することができた。AWRのSQL ordered by...に現れない状態になった。
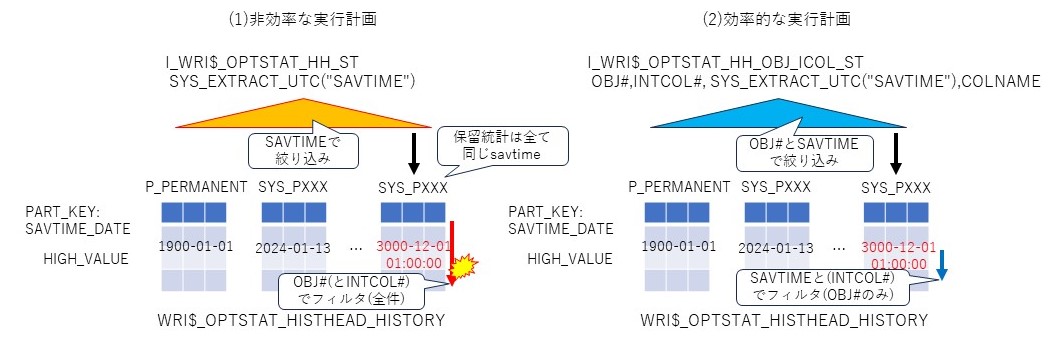
今回の事象を簡単に図に示す。遅延は(1)のI_WRI$_OPTSTAT_HH_STの索引を使ったとき、索引でsavtimeで絞り込んだ後、行をobj#(およびintcol#)で絞り込む部分で発生していたと考えられる。実際は保留統計の場合、savtimeは全て同じ値になっているので、全く絞り込みは効かない。(2)は、I_WRI$_OPTSTAT_HH_OBJ_ICOL_STの索引でobj#とsavtimeで絞り込み、行をsavtime(およびintcol#)で絞り込むため、効率が良い。
根本的な問いは、SQL_ID:5hud5urmn39bxにおいてI_WRI$_OPTSTAT_HH_OBJ_ICOL_ST ではなくI_WRI$_OPTSTAT_HH_ST が利用されていた要因は何か、という点である。10053トレース確認したところ、オプティマイザは両者の索引を比較して、I_WRI$_OPTSTAT_HH_STの方がコストが少ないと判断している。実際のトレースを見てみよう。
オプティマイザは★aでI_WRI$_OPTSTAT_HH_OBJ_ICOL_STのコスト計算を開始している。★bで索引の選択率を0.005435と推定し、★cでコストを4と推定している。その後、★dでI_WRI$_OPTSTAT_HH_STのコスト計算を開始し、★eで索引の選択率を7.3638e-04=0.00073と推定し、コストを2.001352と推定している。以上の結果から★fでI_WRI$_OPTSTAT_HH_STの方がコストが低いため、★gでこの索引を使う実行計画(非効率な実行計画)を選択している。問題は★eの部分において、保留統計の場合はsavtimeが全て同じ値になってしまう点が考慮されていないことではないかと感じている。col#27のヒストグラムが取得されており、バインドピークが有効になっていれば、適切な実行計画が選択されるかもしれない、という期待はあるが、本環境ではバインドピークは無効化しているため、そこまでの確認は行っていない。
本稿では、統計情報履歴削除のdelete文(5hud5urmn39bx)遅延の原因と対処方法について記載した。これは過去に保留統計でヒストグラムの統計履歴削除で遅延した事象(参考[1])と類似事象である。今回はヒストグラム統計は取得しない設定にしていたため、この問題には該当しなかった。
本件をサポートに問い合わせたところ、対処方法についてはSQLパッチが妥当とのことであった。改善要望として、当該回避方法を公開ドキュメント化していただけるようなので、そのうち、公になるかもしれない。
保留統計を使って、マルチテナントでPDBを多く抱えているようなDBでは、このCPU高騰の事象が顕在化しやすいので留意した方が良いかもしれない。
[1]保留統計との闘い~統計取得遅延問題
[2]WRI$_OPTSTAT_HISTHEAD_HISTORYの構成情報
・表・パーティション構成
・索引の構成
以上
1.事象
OCIのBaseDB(19.11)で、メンテナンス時間帯にDBサーバのCPU使用率がかなり上がっていることが問題になっていた。メンテナンスウィンドウは平日7時~11時までに設定されていたが、メンテナンス時間中に複数のPDBで同時に以下のSQLが長時間化しており、CPUをほぼ使い切ってしまっている状況であった。
Elapsed Elapsed Time
Time (s) Executions per Exec (s) %Total %CPU %IO SQL Id
---------------- -------------- ------------- ------ ------ ------ -------------
3,148.5 6,571 0.48 36.4 94.2 .0 5hud5urmn39bx
PDB: XXX
delete /* QOSH:PURGE_OLD_STS *//*+ dynamic_sampling(4) */ from sys.wri$_optstat_histhead_history
where :1 = savtime and obj# = :2 and intcol# = nvl(:3, intcol#)
Buffer Gets Elapsed
Gets Executions per Exec %Total Time (s) %CPU %IO SQL Id
----------- ----------- ------------ ------ ---------- ----- ----- -------------
53,860,231 6,571 8,196.7 30.6 3,148.5 94.2 .0 5hud5urmn39bx
PDB: XXX
delete /* QOSH:PURGE_OLD_STS *//*+ dynamic_sampling(4) */ from sys.wri$_optstat_histhead_history
where :1 = savtime and obj# = :2 and intcol# = nvl(:3, intcol#)
2.解析
wri$_optstat_histhead_history表は、日次のパーティション表で、カラム統計のバックアップを保持する。通常はSAVTIMEはバックアップ日時が入るが、保留統計を使っている場合は、テーブル毎、カラム毎にSAVTIME=3000年12月1日で記録される。つまり、保留統計は全て同じパーティションに入る。
このdelete文は、savtime, obj#, intcol#の3つのプレディケートで削除対象を特定し、(保留)統計情報取得の際に、不要となった保留統計情報を削除していると思われる。様々な表のカラム統計が全く同じSAVTIMEで記録されるため、ある表の保留統計のレコードを識別するためにSAVTIMEでは絞り込めない。このため、表の数が増えてくると、保留統計取得に伴う過去カラム統計の削除に時間がかかるようになるのである。
SQLの実行計画は以下の通り。
◆非効率な実行計画
Plan hash value: 120054584
--------------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop |
--------------------------------------------------------------------------------------------------------------------------------------------
| 0 | DELETE STATEMENT | | 1 | 85 | 4 (0)| 00:00:01 | | |
| 1 | DELETE | WRI$_OPTSTAT_HISTHEAD_HISTORY | | | | | | |
|* 2 | TABLE ACCESS BY GLOBAL INDEX ROWID BATCHED| WRI$_OPTSTAT_HISTHEAD_HISTORY | 1 | 85 | 4 (0)| 00:00:01 | ROWID | ROWID |
|* 3 | INDEX RANGE SCAN | I_WRI$_OPTSTAT_HH_ST | 19 | | 3 (0)| 00:00:01 | | |
--------------------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("OBJ#"=TO_NUMBER(:2) AND "INTCOL#"=NVL(:3,"INTCOL#"))
3 - access(SYS_EXTRACT_UTC("SAVTIME")=SYS_EXTRACT_UTC(TO_TIMESTAMP_TZ(:1)))
グローバルファンクション索引I_WRI$_OPTSTAT_HH_STでsavtimeで絞り込み、obj#とintcol#でフィルタをかけて削除対象のレコードを特定していることがわかる。この実行計画だと、同じSAVTIMEを持つレコードの件数が多いと、フィルタの絞り込みに時間がかる。
AWRレポートから、SQLの実行回数は6,571で、平均実行時間は0.48秒、論理読み込みブロック数は8,196.7である。保留統計の削除は全てsavtimeが同一であることから、パーティションのフルスキャンを繰り返し、結果としてバッファキャッシュ上のブロック読み込みでCPUを使ってしまう。そして、この処理が複数PDB(メンテナンス時間が一緒)で並列実行されるため、DBサーバのCPUが上昇してしまう、という状況を作り出していたのだろう。
他に有効な索引がないか確認したところ、以下のようにI_WRI$_OPTSTAT_HH_OBJ_ICOL_STという索引があった。これはobj#、intcol#、SYS_NC00027$で構成されているので、savtimeだけの絞り込みより効果がありそうである。
SQL> select index_name, column_name from user_ind_columns where table_name='WRI$_OPTSTAT_HISTHEAD_HISTORY' order by index_name, column_position; INDEX_NAME COLUMN_NAME ------------------------------ ------------------------------ I_WRI$_OPTSTAT_HH_OBJ_ICOL_ST OBJ# I_WRI$_OPTSTAT_HH_OBJ_ICOL_ST INTCOL# I_WRI$_OPTSTAT_HH_OBJ_ICOL_ST SYS_NC00027$ I_WRI$_OPTSTAT_HH_OBJ_ICOL_ST COLNAME I_WRI$_OPTSTAT_HH_ST SYS_NC00027$
ちなみにSYS_NC00027$は仮想列で、TIMESTAMP WITH TIME ZONE型のsavtimeから、UTC時間を取り出していることが確認できる。
SQL> select index_name, column_position, column_expression from user_ind_expressions where table_name='WRI$_OPTSTAT_HISTHEAD_HISTORY';
INDEX_NAME COLUMN_POSITION COLUMN_EXPRESSION
------------------------------ --------------- --------------------------------------------------------------------------------
I_WRI$_OPTSTAT_HH_OBJ_ICOL_ST 3 SYS_EXTRACT_UTC("SAVTIME")
I_WRI$_OPTSTAT_HH_ST 1 SYS_EXTRACT_UTC("SAVTIME")
3.対処(チューニング)
このdelete文は統計情報取得のプロシージャ内部で発行されているため、直接ヒントは使えない。SQLパッチで直接SQL_IDを指定して、I_WRI$_OPTSTAT_HH_OBJ_ICOL_STの索引を使うように誘導する。
SQLパッチ作成には、SQL_IDがv$sqlに存在している必要がある。遅延が発生している状況であれば、メンテナンス時間帯またはその直後ならライブラリキャッシュに確認できるはずである。統計情報を手動で取得すればこのdelete文も内部から発行されるはずである。当該SQLパッチは、PDB毎に設定する必要がある点に注意が必要である(CDBに設定してもPDBには効果がない)。
declare patch_name varchar2(20); begin patch_name := dbms_sqldiag.create_sql_patch( sql_id=>'5hud5urmn39bx', hint_text=>'index(@DEL$1 WRI$_OPTSTAT_HISTHEAD_HISTORY@DEL$1 I_WRI$_OPTSTAT_HH_OBJ_ICOL_ST)', name=>'5hud5urmn39bx_patch'); end; /
SQLパッチを適用した後、実行計画を確認したところ、期待通りI_WRI$_OPTSTAT_HH_OBJ_ICOL_STの索引が使われている。こちらの実行計画では索引でobj#とsavtimeを絞り込んでから、savtimeとintcol#でフィルターする形になる(索引だけではsavtimeを絞り込み切れないため、フィルタにも現れていると思われる)。
◆改善後の実行計画
Plan hash value: 3378320514
---------------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop |
---------------------------------------------------------------------------------------------------------------------------------------------
| 0 | DELETE STATEMENT | | 1 | 72 | 4 (0)| 00:00:01 | | |
| 1 | DELETE | WRI$_OPTSTAT_HISTHEAD_HISTORY | | | | | | |
| 2 | TABLE ACCESS BY GLOBAL INDEX ROWID BATCHED| WRI$_OPTSTAT_HISTHEAD_HISTORY | 1 | 72 | 4 (0)| 00:00:01 | ROWID | ROWID |
|* 3 | INDEX RANGE SCAN | I_WRI$_OPTSTAT_HH_OBJ_ICOL_ST | 1 | | 3 (0)| 00:00:01 | | |
---------------------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("OBJ#"=TO_NUMBER(:2) AND SYS_EXTRACT_UTC("SAVTIME")=SYS_EXTRACT_UTC(TO_TIMESTAMP_TZ(:1)))
filter("INTCOL#"=NVL(:3,"INTCOL#") AND SYS_EXTRACT_UTC("SAVTIME")=SYS_EXTRACT_UTC(TO_TIMESTAMP_TZ(:1)))
上記の状態で、後日メンテナンスウィンドウ時間帯のリソースを確認したところ、このDMLによるCPU張り付きの事象は解消することができた。AWRのSQL ordered by...に現れない状態になった。
4.考察
今回の事象を簡単に図に示す。遅延は(1)のI_WRI$_OPTSTAT_HH_STの索引を使ったとき、索引でsavtimeで絞り込んだ後、行をobj#(およびintcol#)で絞り込む部分で発生していたと考えられる。実際は保留統計の場合、savtimeは全て同じ値になっているので、全く絞り込みは効かない。(2)は、I_WRI$_OPTSTAT_HH_OBJ_ICOL_STの索引でobj#とsavtimeで絞り込み、行をsavtime(およびintcol#)で絞り込むため、効率が良い。
根本的な問いは、SQL_ID:5hud5urmn39bxにおいてI_WRI$_OPTSTAT_HH_OBJ_ICOL_ST ではなくI_WRI$_OPTSTAT_HH_ST が利用されていた要因は何か、という点である。10053トレース確認したところ、オプティマイザは両者の索引を比較して、I_WRI$_OPTSTAT_HH_STの方がコストが少ないと判断している。実際のトレースを見てみよう。
****** Costing Index I_WRI$_OPTSTAT_HH_OBJ_ICOL_ST ★a (2)I_WRI$_OPTSTAT_HH_OBJ_ICOL_ST索引のコスト計算(効率的な実行計画)
SPD: Return code in qosdDSDirSetup: NOCTX, estType = INDEX_SCAN
SPD: Return code in qosdDSDirSetup: NOCTX, estType = INDEX_FILTER
ColGroup Usage:: PredCnt: 2 Matches Full: Partial:
Estimated selectivity: 0.005435 , col: #1 →obj#の選択率
Estimated selectivity: 7.3638e-04 , col: #27 →savtime(仮想列)の選択率:7.3638e-04=0.00073
Estimated selectivity: 0.009434 , col: #2 →intcol#の選択率
Access Path: index (RangeScan)
Index: I_WRI$_OPTSTAT_HH_OBJ_ICOL_ST
resc_io: 4.000000 resc_cpu: 57356
ix_sel: 0.005435 ix_sel_with_filters: 3.7755e-08 ★b (2)の索引の検索率(ix_sel)はobj#と同じ
***** Virtual column Adjustment ******
Column name SYS_NC00027$
Adjusted cost_cpu 250
Adjusted cost_io 0.000000
***** End virtual column Adjustment ******
Cost: 4.004604 Resp: 4.004604 Degree: 1 ★c (2)のコストは4
****** Costing Index I_WRI$_OPTSTAT_HH_ST★d (1)I_WRI$_OPTSTAT_HH_ST索引のコスト計算(非効率な実行計画)
SPD: Return code in qosdDSDirSetup: NOCTX, estType = INDEX_SCAN
SPD: Return code in qosdDSDirSetup: NOCTX, estType = INDEX_FILTER
Estimated selectivity: 7.3638e-04 , col: #27 →savtime(仮想列)の選択率
Access Path: index (AllEqRange)
Index: I_WRI$_OPTSTAT_HH_ST
resc_io: 2.000000 resc_cpu: 29484
ix_sel: 7.3638e-04 ix_sel_with_filters: 7.3638e-04 ★e (1)の索引の検索率(ix_sel)はsavtime
Cost: 2.001352 Resp: 2.001352 Degree: 1
Best:: AccessPath: IndexRange ★f (1)の方が良い(いままでのうちベスト)と判定している
Index: I_WRI$_OPTSTAT_HH_ST
Cost: 2.001352 Degree: 1 Resp: 2.001352 Card: 0.000983 Bytes: 0.000000 ★g (1)の索引の実行計画を選定
オプティマイザは★aでI_WRI$_OPTSTAT_HH_OBJ_ICOL_STのコスト計算を開始している。★bで索引の選択率を0.005435と推定し、★cでコストを4と推定している。その後、★dでI_WRI$_OPTSTAT_HH_STのコスト計算を開始し、★eで索引の選択率を7.3638e-04=0.00073と推定し、コストを2.001352と推定している。以上の結果から★fでI_WRI$_OPTSTAT_HH_STの方がコストが低いため、★gでこの索引を使う実行計画(非効率な実行計画)を選択している。問題は★eの部分において、保留統計の場合はsavtimeが全て同じ値になってしまう点が考慮されていないことではないかと感じている。col#27のヒストグラムが取得されており、バインドピークが有効になっていれば、適切な実行計画が選択されるかもしれない、という期待はあるが、本環境ではバインドピークは無効化しているため、そこまでの確認は行っていない。
5.まとめ
本稿では、統計情報履歴削除のdelete文(5hud5urmn39bx)遅延の原因と対処方法について記載した。これは過去に保留統計でヒストグラムの統計履歴削除で遅延した事象(参考[1])と類似事象である。今回はヒストグラム統計は取得しない設定にしていたため、この問題には該当しなかった。
本件をサポートに問い合わせたところ、対処方法についてはSQLパッチが妥当とのことであった。改善要望として、当該回避方法を公開ドキュメント化していただけるようなので、そのうち、公になるかもしれない。
保留統計を使って、マルチテナントでPDBを多く抱えているようなDBでは、このCPU高騰の事象が顕在化しやすいので留意した方が良いかもしれない。
参考
[1]保留統計との闘い~統計取得遅延問題
[2]WRI$_OPTSTAT_HISTHEAD_HISTORYの構成情報
・表・パーティション構成
SQL> select internal_column_id, column_name, nullable, data_type, virtual_column from user_tab_cols where table_name='WRI$_OPTSTAT_HISTHEAD_HISTORY' order by 1;
INTERNAL_COLUMN_ID COLUMN_NAME N DATA_TYPE VIR
------------------ -------------------- - ------------------------------ ---
1 OBJ# N NUMBER NO
2 INTCOL# N NUMBER NO
3 SAVTIME Y TIMESTAMP(6) WITH TIME ZONE NO
4 FLAGS Y NUMBER NO
5 NULL_CNT Y NUMBER NO
6 MINIMUM Y NUMBER NO
7 MAXIMUM Y NUMBER NO
8 DISTCNT Y NUMBER NO
9 DENSITY Y NUMBER NO
10 LOWVAL Y RAW NO
11 HIVAL Y RAW NO
12 AVGCLN Y NUMBER NO
13 SAMPLE_DISTCNT Y NUMBER NO
14 SAMPLE_SIZE Y NUMBER NO
15 TIMESTAMP# Y DATE NO
16 EXPRESSION Y CLOB NO
17 COLNAME Y VARCHAR2 NO
18 SAVTIME_DATE Y DATE YES
19 SPARE1 Y NUMBER NO
20 SPARE2 Y NUMBER NO
21 SPARE3 Y NUMBER NO
22 SPARE4 Y VARCHAR2 NO
23 SPARE5 Y VARCHAR2 NO
24 SPARE6 Y TIMESTAMP(6) WITH TIME ZONE NO
25 MINIMUM_ENC Y RAW NO
26 MAXIMUM_ENC Y RAW NO
27 SYS_NC00027$ Y TIMESTAMP(6) YES
SQL> select partition_name, high_value from user_tab_partitions where table_name='WRI$_OPTSTAT_HISTHEAD_HISTORY';
PARTITION_NAME HIGH_VALUE
---------------- --------------------------------------------------------------------------------
P_PERMANENT TO_DATE(' 1900-01-01 00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIA
SYS_P1907 TO_DATE(' 2024-01-25 00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIA
SYS_P1922 TO_DATE(' 2024-01-27 00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIA
SYS_P1931 TO_DATE(' 2024-01-28 00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIA
SYS_P1942 TO_DATE(' 2024-01-29 00:00:00', 'SYYYY-MM-DD HH24:MI:SS', 'NLS_CALENDAR=GREGORIA
・索引の構成
SQL> select index_name, column_name from user_ind_columns where table_name='WRI$_OPTSTAT_HISTHEAD_HISTORY' order by index_name, column_position;
INDEX_NAME COLUMN_NAME
------------------------------ ------------------------------
I_WRI$_OPTSTAT_HH_OBJ_ICOL_ST OBJ#
I_WRI$_OPTSTAT_HH_OBJ_ICOL_ST INTCOL#
I_WRI$_OPTSTAT_HH_OBJ_ICOL_ST SYS_NC00027$
I_WRI$_OPTSTAT_HH_OBJ_ICOL_ST COLNAME
I_WRI$_OPTSTAT_HH_ST SYS_NC00027$
SQL> select index_name, column_position, column_expression from user_ind_expressions where table_name='WRI$_OPTSTAT_HISTHEAD_HISTORY';
INDEX_NAME COLUMN_POSITION COLUMN_EXPRESSION
------------------------------ --------------- --------------------------------------------------------------------------------
I_WRI$_OPTSTAT_HH_OBJ_ICOL_ST 3 SYS_EXTRACT_UTC("SAVTIME")
I_WRI$_OPTSTAT_HH_ST 1 SYS_EXTRACT_UTC("SAVTIME")
以上
2024-01-28 20:46


