ExadataのI/O統計を整理する [アーキテクチャ]
#2019/2/27変更:図を追加
#2021/2/10変更:図を清書
花粉が飛び始めて春の気配を感じる今日この頃である。
先月、性能TmからExadata特有の統計(AWRから確認できるv$sysstatの統計)について問い合わせがあり、smart scanやflash cacheについて取得すべき統計を洗い出した。知っているつもりではあったが、1つ1つの統計を改めて眺めてみると、その示す意味が意外とよくわかっていないことに気がついたた。マニュアルとExpert Exadataを読みながら、1つ1つの統計の意味を調べてみたので、備忘までここに記しておく。
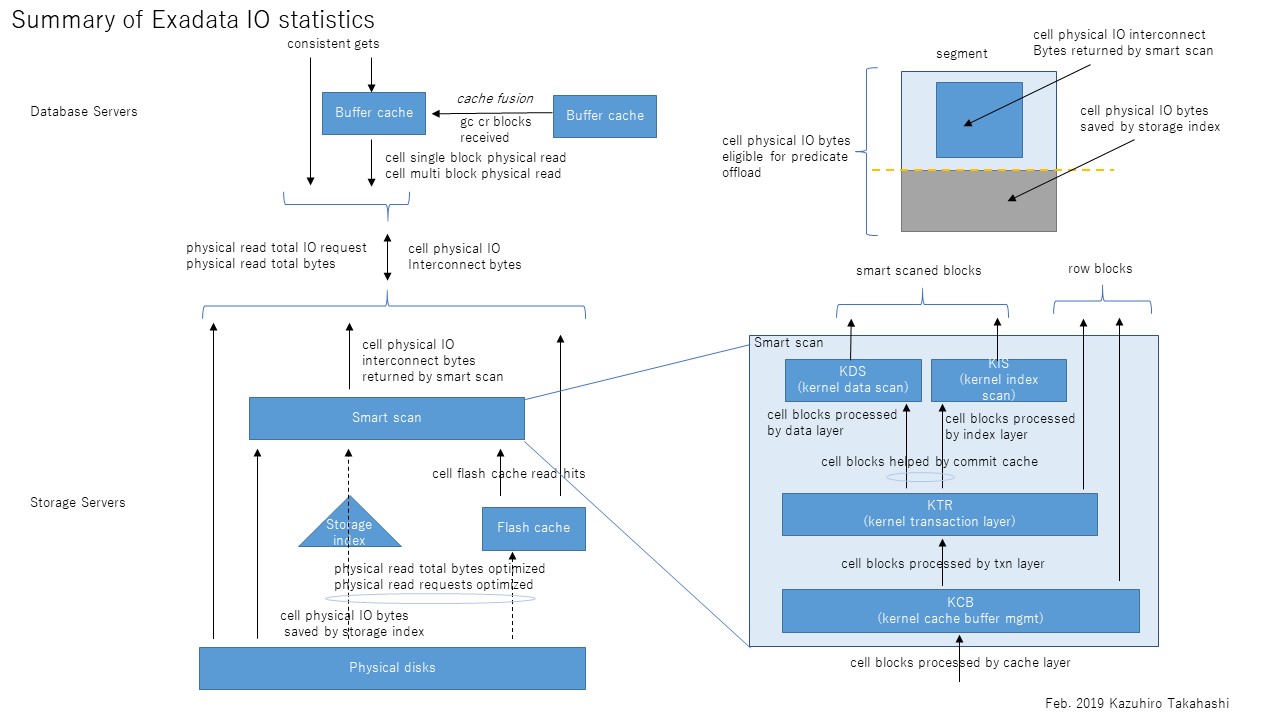
まずExadataのI/Oの全体のアーキテクチャをおさらいしておく。たぶん大体正しい図を書いてみたので、上から順に説明していく。
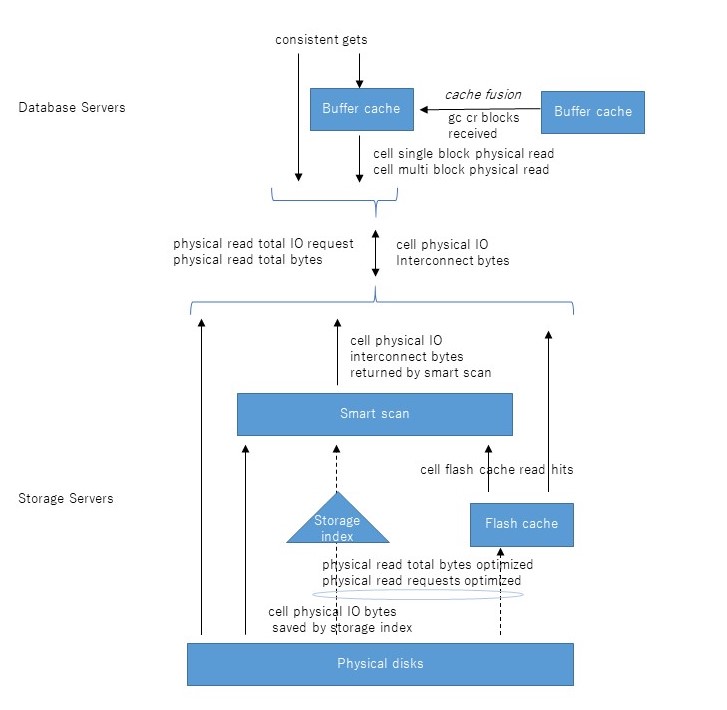
DBサーバでSELECT文を発行するとconsistent gets、すなわち読み取り一貫性を保障するブロック読み込みが発生する。これはローカルDBサーバのバッファキャッシュ上にそのブロックが存在していれば当然そこから読み取られるが、ない場合はcache fusionで他のDBサーバから転送される(gc cr received)。そこにもなければ初めて物理読み込み(physical read bytes等)が発生することとなる。一方、ダイレクトパスリードの場合はバッファキャッシュをバイパスするので、上記の流れはスキップして直接物理読み込みが発生することとなる。
さて、物理読み込みの先は複数のストレージサーバであるが、ここから先がちょっと複雑になる。まず、DBサーバとストレージサーバの間のI/Oを示すのが、cell physical IO interconnect bytesである。これは読み込みだけでなく書き込みも含む、すべてのI/Oのやりとり量を示す統計である。このうち、スマートスキャンにより返却されたI/O量がcell physical IO interconnect bytes returned by smart scanである。これはストレージインデックスやpredicate filtering、column projection等によって削減された後の量である。これらの削減される前のI/O量を示すのがcell physical IO bytes eligible for predicate offloadである。端的には、スマートスキャンがなければDBサーバに返却されたであろうセグメントの全ブロックサイズを示す。従ってスマートスキャンのI/O削減率は以下のように求めることができると考える。
スマートスキャンによるI/O削減率=1- cell physical IO interconnect bytes returned by smart scan / cell physical IO bytes eligible for predicate
これも図にするとイメージし易いだろう。
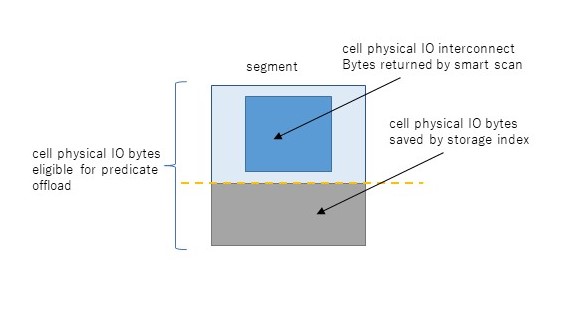
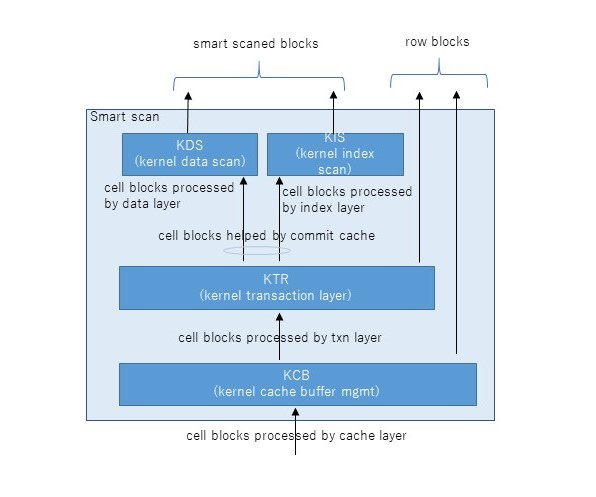
ちなみに話はそれるが、cell physical IO bytes eligible for predicate offloadが0の場合はそもそもスマートスキャンが発生していない状況であることを示す。逆に上記I/O削減率が0の場合はどう考えればよいのだろうか。実はスマートスキャンの3条件が揃っていてスマートスキャンが発生していても、スマートスキャンができずブロックをそのままDBサーバに返却することがある。これはスマートスキャンは読み取り一貫性を保障しつつ、単一ストレージサーバで処理を独立して完結しなければならないこととに関連している。例えば、読み取り一貫性を保障するためにUNDOブロックを読まなければならない場合、ストレージサーバ(cellsrv)はスマートスキャンをあきらめブロックをそのままDBサーバに返却する。同様のことが行連鎖(複数ブロックにレコードがまたがった状態)した表へのアクセスでも発生する。連鎖した先のブロックはASMによる分散で同じストレージサーバ上にある保障はないためである。これらDBサーバへブロックがそのまま返却された場合、スマートスキャンによるI/O削減率が悪化し、DBサーバから大量のsingle block physical readが発生するということが発生する。以下の図はスマートスキャンの部分の内部の流れを示したものだが、右側2つの流れがスマートスキャンにならず、DBサーバへブロックをそのまま返却する流れである。
フラッシュキャッシュにヒットしたI/O数はcell flash cache read hitsで確認できる。physical read total IO requestsに対してどの程度キャッシュヒットしたかがわかる。なお、このtotalの意味はアプリケーション(SQL)だけでなく、バックアップ、リカバリおよびその他のユーティリティを含むIOを示している。totalのないphysical read IO requestsはアプリケーション(SQL)のみのI/Oを示す。従って、フラッシュキャッシュのヒット率は以下の式で求められると考える。
フラッシュキャッシュのヒット率=cell flash cache read hits / physical read total IO requests
フラッシュキャッシュおよびストレージ索引により削減されたI/O量はphysical read total bytes optimizedで確認できる。うち、ストレージインデックス分はcell physical IO bytes saved by storage indexである。ストレージインデックスはスマートスキャンのときだけ使われるが、フラッシュキャッシュは通常のブロックI/Oでも使われる点に留意したい。
なお、上記多くの内容は以下の参考文献に記載されたものをベースに自らの考察を加えたものなので、正確性は保障できないのであしからず。下図はリファレンスとして使うために上記全体を1枚にまとめてみたものである。
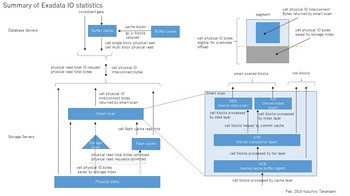
参考文献

#2021/2/10変更:図を清書
花粉が飛び始めて春の気配を感じる今日この頃である。
先月、性能TmからExadata特有の統計(AWRから確認できるv$sysstatの統計)について問い合わせがあり、smart scanやflash cacheについて取得すべき統計を洗い出した。知っているつもりではあったが、1つ1つの統計を改めて眺めてみると、その示す意味が意外とよくわかっていないことに気がついたた。マニュアルとExpert Exadataを読みながら、1つ1つの統計の意味を調べてみたので、備忘までここに記しておく。
まずExadataのI/Oの全体のアーキテクチャをおさらいしておく。たぶん大体正しい図を書いてみたので、上から順に説明していく。
DBサーバでSELECT文を発行するとconsistent gets、すなわち読み取り一貫性を保障するブロック読み込みが発生する。これはローカルDBサーバのバッファキャッシュ上にそのブロックが存在していれば当然そこから読み取られるが、ない場合はcache fusionで他のDBサーバから転送される(gc cr received)。そこにもなければ初めて物理読み込み(physical read bytes等)が発生することとなる。一方、ダイレクトパスリードの場合はバッファキャッシュをバイパスするので、上記の流れはスキップして直接物理読み込みが発生することとなる。
さて、物理読み込みの先は複数のストレージサーバであるが、ここから先がちょっと複雑になる。まず、DBサーバとストレージサーバの間のI/Oを示すのが、cell physical IO interconnect bytesである。これは読み込みだけでなく書き込みも含む、すべてのI/Oのやりとり量を示す統計である。このうち、スマートスキャンにより返却されたI/O量がcell physical IO interconnect bytes returned by smart scanである。これはストレージインデックスやpredicate filtering、column projection等によって削減された後の量である。これらの削減される前のI/O量を示すのがcell physical IO bytes eligible for predicate offloadである。端的には、スマートスキャンがなければDBサーバに返却されたであろうセグメントの全ブロックサイズを示す。従ってスマートスキャンのI/O削減率は以下のように求めることができると考える。
スマートスキャンによるI/O削減率=1- cell physical IO interconnect bytes returned by smart scan / cell physical IO bytes eligible for predicate
これも図にするとイメージし易いだろう。
ちなみに話はそれるが、cell physical IO bytes eligible for predicate offloadが0の場合はそもそもスマートスキャンが発生していない状況であることを示す。逆に上記I/O削減率が0の場合はどう考えればよいのだろうか。実はスマートスキャンの3条件が揃っていてスマートスキャンが発生していても、スマートスキャンができずブロックをそのままDBサーバに返却することがある。これはスマートスキャンは読み取り一貫性を保障しつつ、単一ストレージサーバで処理を独立して完結しなければならないこととに関連している。例えば、読み取り一貫性を保障するためにUNDOブロックを読まなければならない場合、ストレージサーバ(cellsrv)はスマートスキャンをあきらめブロックをそのままDBサーバに返却する。同様のことが行連鎖(複数ブロックにレコードがまたがった状態)した表へのアクセスでも発生する。連鎖した先のブロックはASMによる分散で同じストレージサーバ上にある保障はないためである。これらDBサーバへブロックがそのまま返却された場合、スマートスキャンによるI/O削減率が悪化し、DBサーバから大量のsingle block physical readが発生するということが発生する。以下の図はスマートスキャンの部分の内部の流れを示したものだが、右側2つの流れがスマートスキャンにならず、DBサーバへブロックをそのまま返却する流れである。
フラッシュキャッシュにヒットしたI/O数はcell flash cache read hitsで確認できる。physical read total IO requestsに対してどの程度キャッシュヒットしたかがわかる。なお、このtotalの意味はアプリケーション(SQL)だけでなく、バックアップ、リカバリおよびその他のユーティリティを含むIOを示している。totalのないphysical read IO requestsはアプリケーション(SQL)のみのI/Oを示す。従って、フラッシュキャッシュのヒット率は以下の式で求められると考える。
フラッシュキャッシュのヒット率=cell flash cache read hits / physical read total IO requests
フラッシュキャッシュおよびストレージ索引により削減されたI/O量はphysical read total bytes optimizedで確認できる。うち、ストレージインデックス分はcell physical IO bytes saved by storage indexである。ストレージインデックスはスマートスキャンのときだけ使われるが、フラッシュキャッシュは通常のブロックI/Oでも使われる点に留意したい。
なお、上記多くの内容は以下の参考文献に記載されたものをベースに自らの考察を加えたものなので、正確性は保障できないのであしからず。下図はリファレンスとして使うために上記全体を1枚にまとめてみたものである。
参考文献
- 作者: Martin Bach
- 出版社/メーカー: Apress
- 発売日: 2015/08/13
- メディア: ペーパーバック
Exadataスマートスキャンの基本 [アーキテクチャ]
スマートスキャンとは、Exadata特有のクエリの高速化技術である。この挙動については非公開の部分が多く、また、ストレージサーバソフトウェアのバージョンによって挙動が異なるため、一般的な技術資料も概要レベルにとどまっていることが多い。ここでは書籍等から得られたスマートスキャンのアーキテクチャについて記載する。内容についての正確性は保証できないのであくまで参考まで。
Exadataのスマートスキャンは、もともとDWHなど大規模DBほどストーレジとDB層間のブロック転送が性能のボトルネックになるという課題から、ストレージ層でDBサーバの処理に必要なブロックを絞って転送する技術である。実際には広くはストレージ層への処理の「オフローディング」する概念であり、その中にはブロックの解凍やカラムに対する関数の計算といった機能も含まれるが、特にフルスキャン時のI/Oの最適化をスマートスキャンと呼んでいる。
スマートスキャンにより提供される基本機能は以下の3つである。
(1)Predicate Filtering
WHERE句で絞られた必要なレコードのみDBサーバへ返却する機能。ストレージサーバ層でfilter操作を行う
(2)Column Projection
SELECT句で指定されたカラムのみDBサーバへ返却する機能。ストレージサーバ層でSELECTやWHERE句の結合カラムを絞る
(3)Storage Indexes
1MBディスクブロック毎の最大・最小値の情報を利用し、ストレージサーバ層の読み込みブロック量を削減する
上記のほかに、HASH結合におけるBloomFilter、単一行関数(数値、文字列操作)やHCCブロックの解凍もストレージサーバ側にオフロードできたりする。ポイントはこれらすべての機能はスマートスキャンが動作するときに有効になる、ということである。
なお、ストレージインデックスはあまりなじみがない機能であるため、少しここで触れておこう。巣トレージインデックスはストレージサーバ上で管理する1MB毎のストレージ領域ごとに、その最小・最大・NULLの存在を格納したものである。昔は8カラム/表までしか格納できなかったらしいが、今は255までいけるらしい(前回OOWで技術者の方から直接聞いた)。この情報はストレージサーバのメモリに格納されており、スマートスキャンのときpredicate(WHERE句)がストレージインデックスに対してチェックされ、必要なブロックを絞り込む。例えば、
select * from emp where sal > 65
というクエリを発行した場合、SQLのWHERE句からsalカラムのストレージインデックスのmin/maxが検索され、sal>65を満たす1MBブロックのみが抽出されDBサーバ層に返却されることとなる。なお、比較に使える操作は決まっており、=, <, >, BETWEEN, >=, <=, IN, IS NULL, IN NOT NULLである。ストレージインデックスで削減されたブロックはcell physical IO bytes saved by storage indexから確認できる。
スマートスキャンの発生条件は以下の3つである。
(1)セグメントのフルスキャンであること(表・パーティション・索引・マテビュー)
(2)ダイレクトパスリードであること
(3)オブジェクトはExadataに格納されていること
上記条件のうち、(1)は実行計画から確認可能、(3)は自明であるが、(2)が一番わかりにくい。ダイレクトパスリードでないとならない理由は、このスマートスキャンを実現する関数(kcfis_read... kernel cache file intelligent storage)の実装がCのコールスタックにおいてダイレクトパスリードの関数(kcbldrget... kernel cache block direct read get)の下にあるからに過ぎない。ダイレクトパスリードの発動条件については以前の記事(ダイレクトパスリードについて思うこと)にある程度記載されているのでここでは割愛する。
スマートスキャンの発生を確認する方法としては、以下の4つである。
(1)SQLトレース... cell smart table scanの待機イベントを確認できる
(2)セッション性能統計... v$sesstat, v$mystat(v$statname)でcell scansの増加を確認できる
(3)v$sqlのoffload eligible bytes... IO_CELL_OFFLOAD_ELIGIBLE_BYTESでoffloadにより削減されたI/Oが確認できる
(4)SQLモニタリング(要Diagnostic Tuning packライセンス) ... DBMS_SQL_MONITOR.REPORT_SQL_MONITORのCell Offload%で実行計画のどこがスマートスキャンか確認できる(実行中・実行直後に確認が必要)
例) set long 10000 longchuksize 10000; select dbms_sql_monitor.report_sql_monitor( sql_id=> 'xxx', report_level=>'ALL', type=>'TEXT') as report from dual;
スマートスキャンを制御する上で重要な初期化パラメータは以下3つである。商用で使うかどうかは別として、検証には非常に便利であるので、押さえておきたい。
(1) cell_offload_processing (デフォルトTRUE) ... オフロード機能を制御するパラメータ。FALSEでスマートスキャンの発生を抑止できる
(2)_serial_direct_read (デフォルトAUTO) ... シリアルダイレクトパスリードを制御する。パラメータ値としては、ALWAYS, AUTO, TRUE, FALSE, NEVERであるが、12c以降であればALWAYSとNEVERで制御できる。
(3)_kcfis_storageidx_disabled (デフォルトFALSE) ... ストレージインデックス機能を制御する。TRUEにすればストレージインデックスは使われなくなる
最後にcellsrvの複雑な挙動がある点を記載しておく。いずれもいままで経験したことはないが、スマートスキャンを期待して作りこまれた処理が、突然性能遅延が発生するようなことが起こりうる。これが発生している状況にあった場合は、解析・対処はかなり難しい状況だろう。
(1)cellsrvがoffloadをやめることがある
断片化ブロックの読み込みやconsistent readのためのUNDOブロック読み込みで発生する。ストレージサーバはお互いに通信できないため、他のストレージサーバのブロックを読み込む必要があると、DBサーバにブロックを返却せざるを得ない。この場合、smart scanとなっていても待機イベントとしてはcell single block physical readが発生する。
(2)CPU負荷が高いとcellsrvが一部のオフロード処理をしないことがある
HCCの解凍処理など、ストレージサーバのCPU負荷が高い場合、圧縮された状態でDBサーバへブロックを返却してしまう。HCC使っていなければ気にすることはないだろう
(3)cellsrvがパススルーモードになることがある
ストレージサーバがパススルーモードとなると、predicate filteringをやめてすべてのブロックをDBサーバに返却するため、cell smart table scan待機が突然大きくなる。cell num smart IO sessions using passthru mode due to cellsrvに痕跡が残るらしい。
以上
◆参考
Exadataのスマートスキャンは、もともとDWHなど大規模DBほどストーレジとDB層間のブロック転送が性能のボトルネックになるという課題から、ストレージ層でDBサーバの処理に必要なブロックを絞って転送する技術である。実際には広くはストレージ層への処理の「オフローディング」する概念であり、その中にはブロックの解凍やカラムに対する関数の計算といった機能も含まれるが、特にフルスキャン時のI/Oの最適化をスマートスキャンと呼んでいる。
スマートスキャンにより提供される基本機能は以下の3つである。
(1)Predicate Filtering
WHERE句で絞られた必要なレコードのみDBサーバへ返却する機能。ストレージサーバ層でfilter操作を行う
(2)Column Projection
SELECT句で指定されたカラムのみDBサーバへ返却する機能。ストレージサーバ層でSELECTやWHERE句の結合カラムを絞る
(3)Storage Indexes
1MBディスクブロック毎の最大・最小値の情報を利用し、ストレージサーバ層の読み込みブロック量を削減する
上記のほかに、HASH結合におけるBloomFilter、単一行関数(数値、文字列操作)やHCCブロックの解凍もストレージサーバ側にオフロードできたりする。ポイントはこれらすべての機能はスマートスキャンが動作するときに有効になる、ということである。
なお、ストレージインデックスはあまりなじみがない機能であるため、少しここで触れておこう。巣トレージインデックスはストレージサーバ上で管理する1MB毎のストレージ領域ごとに、その最小・最大・NULLの存在を格納したものである。昔は8カラム/表までしか格納できなかったらしいが、今は255までいけるらしい(前回OOWで技術者の方から直接聞いた)。この情報はストレージサーバのメモリに格納されており、スマートスキャンのときpredicate(WHERE句)がストレージインデックスに対してチェックされ、必要なブロックを絞り込む。例えば、
select * from emp where sal > 65
というクエリを発行した場合、SQLのWHERE句からsalカラムのストレージインデックスのmin/maxが検索され、sal>65を満たす1MBブロックのみが抽出されDBサーバ層に返却されることとなる。なお、比較に使える操作は決まっており、=, <, >, BETWEEN, >=, <=, IN, IS NULL, IN NOT NULLである。ストレージインデックスで削減されたブロックはcell physical IO bytes saved by storage indexから確認できる。
スマートスキャンの発生条件は以下の3つである。
(1)セグメントのフルスキャンであること(表・パーティション・索引・マテビュー)
(2)ダイレクトパスリードであること
(3)オブジェクトはExadataに格納されていること
上記条件のうち、(1)は実行計画から確認可能、(3)は自明であるが、(2)が一番わかりにくい。ダイレクトパスリードでないとならない理由は、このスマートスキャンを実現する関数(kcfis_read... kernel cache file intelligent storage)の実装がCのコールスタックにおいてダイレクトパスリードの関数(kcbldrget... kernel cache block direct read get)の下にあるからに過ぎない。ダイレクトパスリードの発動条件については以前の記事(ダイレクトパスリードについて思うこと)にある程度記載されているのでここでは割愛する。
スマートスキャンの発生を確認する方法としては、以下の4つである。
(1)SQLトレース... cell smart table scanの待機イベントを確認できる
(2)セッション性能統計... v$sesstat, v$mystat(v$statname)でcell scansの増加を確認できる
(3)v$sqlのoffload eligible bytes... IO_CELL_OFFLOAD_ELIGIBLE_BYTESでoffloadにより削減されたI/Oが確認できる
(4)SQLモニタリング(要Diagnostic Tuning packライセンス) ... DBMS_SQL_MONITOR.REPORT_SQL_MONITORのCell Offload%で実行計画のどこがスマートスキャンか確認できる(実行中・実行直後に確認が必要)
例) set long 10000 longchuksize 10000; select dbms_sql_monitor.report_sql_monitor( sql_id=> 'xxx', report_level=>'ALL', type=>'TEXT') as report from dual;
スマートスキャンを制御する上で重要な初期化パラメータは以下3つである。商用で使うかどうかは別として、検証には非常に便利であるので、押さえておきたい。
(1) cell_offload_processing (デフォルトTRUE) ... オフロード機能を制御するパラメータ。FALSEでスマートスキャンの発生を抑止できる
(2)_serial_direct_read (デフォルトAUTO) ... シリアルダイレクトパスリードを制御する。パラメータ値としては、ALWAYS, AUTO, TRUE, FALSE, NEVERであるが、12c以降であればALWAYSとNEVERで制御できる。
(3)_kcfis_storageidx_disabled (デフォルトFALSE) ... ストレージインデックス機能を制御する。TRUEにすればストレージインデックスは使われなくなる
最後にcellsrvの複雑な挙動がある点を記載しておく。いずれもいままで経験したことはないが、スマートスキャンを期待して作りこまれた処理が、突然性能遅延が発生するようなことが起こりうる。これが発生している状況にあった場合は、解析・対処はかなり難しい状況だろう。
(1)cellsrvがoffloadをやめることがある
断片化ブロックの読み込みやconsistent readのためのUNDOブロック読み込みで発生する。ストレージサーバはお互いに通信できないため、他のストレージサーバのブロックを読み込む必要があると、DBサーバにブロックを返却せざるを得ない。この場合、smart scanとなっていても待機イベントとしてはcell single block physical readが発生する。
(2)CPU負荷が高いとcellsrvが一部のオフロード処理をしないことがある
HCCの解凍処理など、ストレージサーバのCPU負荷が高い場合、圧縮された状態でDBサーバへブロックを返却してしまう。HCC使っていなければ気にすることはないだろう
(3)cellsrvがパススルーモードになることがある
ストレージサーバがパススルーモードとなると、predicate filteringをやめてすべてのブロックをDBサーバに返却するため、cell smart table scan待機が突然大きくなる。cell num smart IO sessions using passthru mode due to cellsrvに痕跡が残るらしい。
以上
◆参考
- 作者: Martin Bach
- 出版社/メーカー: Apress
- 発売日: 2015/08/13
- メディア: ペーパーバック
Exadataフラッシュキャッシュの謎 [アーキテクチャ]
相変わらずExadataのフラッシュキャッシュの性能問題に悩まされている。その解析を進める中で、そもそもそのアーキテクチャを書籍等で調査したので、その内容を以下に記載する。
◆Exadataフラッシュキャッシュとは
ExadataはRACを構成する複数のDBサーバと、ASM上にディスクグループを構成する複数のストレージサーバから構成される。例えば現在のモデルであるX7-2のハーフラックではDBサーバ4台、ストレージサーバ7台という具合である。このストレージサーバは12本のHDDと4本のフラッシュキャッシュで構成される。HDDは10TBのSAS、フラッシュキャッシュは6.4TBのPCIeカードである。このフラッシュキャッシュをExadata Smart Flash Cache (ESFC)という。ここでは単にフラッシュキャッシュと記す。
このフラッシュキャッシュであるが、Exadataのモデルチェンジ毎に倍になってきている。一方、HDDの方は概ね1.5倍ずつ増加していることと比べると、フラッシュキャッシュの進化の速度の早さを感じざるを得ない。また、容量の点でも、フラッシュキャッシュと言いつつ、X7-2ハーフラックでは物理で全179TBとなり、冗長度を考慮したとしてもかなりの規模のDBならすべてフラッシュキャッシュ上に載せたままにすることが可能な状況になってきている。当然、性能(IOPS)はHDDに比べて2桁程高い(Exadataのデータシート)ため、オンライン処理などのシングルブロックリードのワークロードに高い性能を発揮できる。
X4:F80 (800GB) vs 4TB HDD
X5:F160 (1.6TB) vs 4TB HDD
X6:F320 (3.2TB) vs 8TB HDD
X7:F640 (6.4TB) vs 10TB HDD
X7-2のフラッシュキャッシュはストレージサーバからどのように認識されているかはcellclie -e list physicaldisk where disktype=flashdiskで確認できる。4枚のフラッシュキャッシュがあり、1枚のフラッシュキャッシュが2.9TBの2つのデバイスで構成されていることがわかる。従って、実際は5.8TB/毎程度なので、物理の90%程度のサイズで認識されている。
◆Exadataフラッシュキャッシュのアーキテクチャ
フラッシュキャッシュのアーキテクチャを理解する上で、ここでは2ノードRAC構成を考える。DBサーバ#1でSELECTによりシングルブロックリードを行う単純なケースを考えてみよう。Exadataでは以下のように必要なブロックを探す。
(1)ローカルのバッファキャッシュ上からブロックを探す
(2)なければ、CacheFusionでクラスタ内のグローバルキャッシュから探す
(3)なければ、ストレージサーバへブロック要求を出す
(4)ストレージサーバがフラッシュキャッシュからブロックを探す。なければディスクから読む
(5)ストレージサーバはDBサーバへブロックを返却する
(6)ブロックがフラッシュキャッシュ上にないときは、フラッシュキャッシュへブロックを配置する
ここで特筆すべきは、(6)は非同期であるということである。ディスクから読み込まれてからフラッシュキャッシュに乗るまでにタイムラグがあることである。通常のブロックデバイスのストレージキャッシュはキャッシュを「経由」するアーキテクチャであるため、Exadata特有のクセとして認識しておいた方が良いだろう。
また、I/Oの特性によりフラッシュキャッシュに乗せる・乗せないを制御している点も興味深い。例えば、RMANバックアップやexpdp、アーカイブログ等のI/Oはフラッシュキャッシュに乗らない。さらに、フラッシュキャッシュに乗せたブロックは、どのテーブルやインデックスのオブジェクトなのかストレージサーバは知っている。フラッシュキャッシュ上のブロックはdba_objectsのdata_object_idで緋付けられている。従って、data_object_idが変更されるようなalter table文などを実行するとフラッシュキャッシュから落ちる。これも特性として理解しておく必要があるだろう。
そして、上記(4)~(6)の動作を制御しているのがcellservというプロセスであることも理解しておく必要がある。ストレージサーバでのオフロード機能(smartscan等)は恐らくすべてこのcellservで実現されていると言っても過言ではないだろう。
◆WriteBackについて
ストレージサーバへの書き込みは通常、ディスクまで書き込みを行ってから制御を戻すWriteThroughモードがデフォルトの挙動である。しかし、フラッシュキャッシュをWriteBackキャッシュとして構成することが可能である。これにより、ストレージサーバへの書き込み要求はフラッシュキャッシュへの書き込みで制御を戻すことが可能となり、ディスクへの書き込みは非同期となる。これによりOracleデータファイルの書き込みI/Oのボトルネックを解消することが可能となる。
WriteBackキャッシュはASMの冗長化が必要なため、WriteThroughモードより論理容量は減る(ASM3冗長ならWriteBackは1/3の容量となる)。また、そもそもDBWRに待機が発生していないような状況では、性能向上への効果は限定的であると考えるべきであろう。通常、DBは読み込み(特にシングルブロックリード)がI/Oのネックとなり易いため、通常はフラッシュキャッシュの領域が大きいメリットを享受できるWriteThroughが良いだろう。SGAに対して十分大きなセグメントの大量更新など、Free buffer waitsなどDBWRの書き込みの待機が発生する状況においては、WriteBackの効果が得られるだろう。
なお、現在どちらのモードになっているかは、cellcli -e list cell attributes flashcachemode detailでflashCacheModeを確認すればよい。また、構成方法についてはMOSのDocID:1500257.1が参考になる。
◆CELL_FLASH_CACHEストレージ句について
セグメントのSTORAGE句CELL_FLASH_CACHEでフラッシュキャッシュに乗せるブロックの優先度を制御することが可能である。具体的に指定可能なのは以下3つである。
・NONE:フラッシュキャッシュを使わない
・DEFAULT:小さいI/O(single block read)のブロックをフラッシュキャッシュに乗せる。デフォルトの挙動
・KEEP:フルスキャンのブロックをフラッシュキャッシュに乗せる。溢れた場合、KEEPされたブロックは最後に消される
ただしストレージサーバソフトウェアのバージョンによって挙動が違うので注意が必要である。少なくともX7-2ではDEFAULTであってもフルスキャンのブロックはフラッシュキャッシュに乗る。また、昔は24時間でKEEPはexpireされるという仕様も見直されており、残り続けるらしい。このあたりの細かな挙動には謎が多く、仕様も公開されていない。OOWでExadataの開発者に話を聞いた限り、最近ではほとんどのケースにおいてDEFAULTのままで問題ないそうだ。
常識的にKEEPを多用することで、フラッシュキャッシュが溢れるような使い方をすることは好ましくない。フラッシュキャッシュはブロックの変更をするために、内部的には空きブロックを新規に確保し既存ブロックは不要マークを付けて、非同期にガベージコレクトする方式となっているらしい。このため、溢れるような状況になると性能劣化の要因となる可能性がある。KEEPを使う場合は、KEEPすべきオブジェクトの選定し、十分に収まる範囲で使うのが良いだろう。
フラッシュキャッシュが一杯になったときの挙動はまったくの謎である。恐らくLRUにより古いブロックをパージし、新しいブロックを書き込むはずであるが、実際はそんなに単純ではない。まずフラッシュキャッシュ内の構造が謎である。Default/Keepバッファ等があり、各領域の比率もなんらかの制約があるだろう。また、アクセスパターンも読み込み(HDDからフラッシュキャッシュ)、書き込み(DBサーバからフラッシュキャッシュ)によって落とし方に違いがあるかもしれない。このあたりの挙動はmetriccurrent fc_XXXの統計を追いかけない限りわからないかもしれない。
なお、CELL_FLASH_CACHEストレージ句の設定方法は簡単である。alter table/index xxx storage (cell_flash_cache keep)すればよい。DBA_SEGMENTSのCELL_FLASH_CACHEカラムで現在の設定の状態が確認できる。
◆フラッシュキャッシュの確認方法
備忘まで、確認方法のコマンドを記載しておく。cellcliはストレージサーバ側で実行すること。
・フラッシュキャッシュに乗っている容量
cellcli -e list flashcache detail | grep effect
cellcli -e list metriccurrent fc_by_allocated, fc_by_used, fc_bykeep_used
・フラッシュキャッシュに乗っているオブジェクトの確認
SQL> select data_object_id from dba_objects where object_name='xxx'; ←テーブル名など
cellcli -e list flashcachecontent detail where objectNumber=999 detail ←999が上記SQLで返却されたdata_object_id
※objectNumberがdba_objectsのdata_object_idと紐付く
以上
◆参考文献
")
◆Exadataフラッシュキャッシュとは
ExadataはRACを構成する複数のDBサーバと、ASM上にディスクグループを構成する複数のストレージサーバから構成される。例えば現在のモデルであるX7-2のハーフラックではDBサーバ4台、ストレージサーバ7台という具合である。このストレージサーバは12本のHDDと4本のフラッシュキャッシュで構成される。HDDは10TBのSAS、フラッシュキャッシュは6.4TBのPCIeカードである。このフラッシュキャッシュをExadata Smart Flash Cache (ESFC)という。ここでは単にフラッシュキャッシュと記す。
このフラッシュキャッシュであるが、Exadataのモデルチェンジ毎に倍になってきている。一方、HDDの方は概ね1.5倍ずつ増加していることと比べると、フラッシュキャッシュの進化の速度の早さを感じざるを得ない。また、容量の点でも、フラッシュキャッシュと言いつつ、X7-2ハーフラックでは物理で全179TBとなり、冗長度を考慮したとしてもかなりの規模のDBならすべてフラッシュキャッシュ上に載せたままにすることが可能な状況になってきている。当然、性能(IOPS)はHDDに比べて2桁程高い(Exadataのデータシート)ため、オンライン処理などのシングルブロックリードのワークロードに高い性能を発揮できる。
X4:F80 (800GB) vs 4TB HDD
X5:F160 (1.6TB) vs 4TB HDD
X6:F320 (3.2TB) vs 8TB HDD
X7:F640 (6.4TB) vs 10TB HDD
X7-2のフラッシュキャッシュはストレージサーバからどのように認識されているかはcellclie -e list physicaldisk where disktype=flashdiskで確認できる。4枚のフラッシュキャッシュがあり、1枚のフラッシュキャッシュが2.9TBの2つのデバイスで構成されていることがわかる。従って、実際は5.8TB/毎程度なので、物理の90%程度のサイズで認識されている。
◆Exadataフラッシュキャッシュのアーキテクチャ
フラッシュキャッシュのアーキテクチャを理解する上で、ここでは2ノードRAC構成を考える。DBサーバ#1でSELECTによりシングルブロックリードを行う単純なケースを考えてみよう。Exadataでは以下のように必要なブロックを探す。
(1)ローカルのバッファキャッシュ上からブロックを探す
(2)なければ、CacheFusionでクラスタ内のグローバルキャッシュから探す
(3)なければ、ストレージサーバへブロック要求を出す
(4)ストレージサーバがフラッシュキャッシュからブロックを探す。なければディスクから読む
(5)ストレージサーバはDBサーバへブロックを返却する
(6)ブロックがフラッシュキャッシュ上にないときは、フラッシュキャッシュへブロックを配置する
ここで特筆すべきは、(6)は非同期であるということである。ディスクから読み込まれてからフラッシュキャッシュに乗るまでにタイムラグがあることである。通常のブロックデバイスのストレージキャッシュはキャッシュを「経由」するアーキテクチャであるため、Exadata特有のクセとして認識しておいた方が良いだろう。
また、I/Oの特性によりフラッシュキャッシュに乗せる・乗せないを制御している点も興味深い。例えば、RMANバックアップやexpdp、アーカイブログ等のI/Oはフラッシュキャッシュに乗らない。さらに、フラッシュキャッシュに乗せたブロックは、どのテーブルやインデックスのオブジェクトなのかストレージサーバは知っている。フラッシュキャッシュ上のブロックはdba_objectsのdata_object_idで緋付けられている。従って、data_object_idが変更されるようなalter table文などを実行するとフラッシュキャッシュから落ちる。これも特性として理解しておく必要があるだろう。
そして、上記(4)~(6)の動作を制御しているのがcellservというプロセスであることも理解しておく必要がある。ストレージサーバでのオフロード機能(smartscan等)は恐らくすべてこのcellservで実現されていると言っても過言ではないだろう。
◆WriteBackについて
ストレージサーバへの書き込みは通常、ディスクまで書き込みを行ってから制御を戻すWriteThroughモードがデフォルトの挙動である。しかし、フラッシュキャッシュをWriteBackキャッシュとして構成することが可能である。これにより、ストレージサーバへの書き込み要求はフラッシュキャッシュへの書き込みで制御を戻すことが可能となり、ディスクへの書き込みは非同期となる。これによりOracleデータファイルの書き込みI/Oのボトルネックを解消することが可能となる。
WriteBackキャッシュはASMの冗長化が必要なため、WriteThroughモードより論理容量は減る(ASM3冗長ならWriteBackは1/3の容量となる)。また、そもそもDBWRに待機が発生していないような状況では、性能向上への効果は限定的であると考えるべきであろう。通常、DBは読み込み(特にシングルブロックリード)がI/Oのネックとなり易いため、通常はフラッシュキャッシュの領域が大きいメリットを享受できるWriteThroughが良いだろう。SGAに対して十分大きなセグメントの大量更新など、Free buffer waitsなどDBWRの書き込みの待機が発生する状況においては、WriteBackの効果が得られるだろう。
なお、現在どちらのモードになっているかは、cellcli -e list cell attributes flashcachemode detailでflashCacheModeを確認すればよい。また、構成方法についてはMOSのDocID:1500257.1が参考になる。
◆CELL_FLASH_CACHEストレージ句について
セグメントのSTORAGE句CELL_FLASH_CACHEでフラッシュキャッシュに乗せるブロックの優先度を制御することが可能である。具体的に指定可能なのは以下3つである。
・NONE:フラッシュキャッシュを使わない
・DEFAULT:小さいI/O(single block read)のブロックをフラッシュキャッシュに乗せる。デフォルトの挙動
・KEEP:フルスキャンのブロックをフラッシュキャッシュに乗せる。溢れた場合、KEEPされたブロックは最後に消される
ただしストレージサーバソフトウェアのバージョンによって挙動が違うので注意が必要である。少なくともX7-2ではDEFAULTであってもフルスキャンのブロックはフラッシュキャッシュに乗る。また、昔は24時間でKEEPはexpireされるという仕様も見直されており、残り続けるらしい。このあたりの細かな挙動には謎が多く、仕様も公開されていない。OOWでExadataの開発者に話を聞いた限り、最近ではほとんどのケースにおいてDEFAULTのままで問題ないそうだ。
常識的にKEEPを多用することで、フラッシュキャッシュが溢れるような使い方をすることは好ましくない。フラッシュキャッシュはブロックの変更をするために、内部的には空きブロックを新規に確保し既存ブロックは不要マークを付けて、非同期にガベージコレクトする方式となっているらしい。このため、溢れるような状況になると性能劣化の要因となる可能性がある。KEEPを使う場合は、KEEPすべきオブジェクトの選定し、十分に収まる範囲で使うのが良いだろう。
フラッシュキャッシュが一杯になったときの挙動はまったくの謎である。恐らくLRUにより古いブロックをパージし、新しいブロックを書き込むはずであるが、実際はそんなに単純ではない。まずフラッシュキャッシュ内の構造が謎である。Default/Keepバッファ等があり、各領域の比率もなんらかの制約があるだろう。また、アクセスパターンも読み込み(HDDからフラッシュキャッシュ)、書き込み(DBサーバからフラッシュキャッシュ)によって落とし方に違いがあるかもしれない。このあたりの挙動はmetriccurrent fc_XXXの統計を追いかけない限りわからないかもしれない。
なお、CELL_FLASH_CACHEストレージ句の設定方法は簡単である。alter table/index xxx storage (cell_flash_cache keep)すればよい。DBA_SEGMENTSのCELL_FLASH_CACHEカラムで現在の設定の状態が確認できる。
◆フラッシュキャッシュの確認方法
備忘まで、確認方法のコマンドを記載しておく。cellcliはストレージサーバ側で実行すること。
・フラッシュキャッシュに乗っている容量
cellcli -e list flashcache detail | grep effect
cellcli -e list metriccurrent fc_by_allocated, fc_by_used, fc_bykeep_used
・フラッシュキャッシュに乗っているオブジェクトの確認
SQL> select data_object_id from dba_objects where object_name='xxx'; ←テーブル名など
cellcli -e list flashcachecontent detail where objectNumber=999 detail ←999が上記SQLで返却されたdata_object_id
※objectNumberがdba_objectsのdata_object_idと紐付く
以上
◆参考文献
- 作者: Martin Bach
- 出版社/メーカー: Apress
- 発売日: 2015/08/13
- メディア: ペーパーバック
Oracle Exadata Expert's Handbook (English Edition)
- 出版社/メーカー: Addison-Wesley Professional
- 発売日: 2015/06/12
- メディア: Kindle版


