バインドミスマッチのSQLの特定方法の一考察 [オプティマイザ]
1.はじめに
以前の記事でバインドミスマッチによる性能遅延の問題について記載した。その中で、この問題を発生させないようにするためには、Java等のアプリケーションでバインド変数に適切な型を設定することが重要であることを述べた。そのためにはアプリケーションを開発する技術者にOracleのアーキテクチャを理解して設計することが求められると同時に、設計や実装段階でこの問題を検出する仕組みが必要である。
しかし、実際問題、アプリケーションの開発者はOracleのアーキテクチャに詳しい訳でもなく、試験において機能確認以上にバインド型の妥当性まで確認することはなかなか難しい。そもそも、その必要性を理解してもらうことすらままならないのが現実である。
そこで考えたのが、データベースに流れているSQLの中で、問題を発生させる可能性のあるSQLを一括して調査する方法である。これができれば、アプリケーションの開発や性能試験の中で、バインドミスマッチの問題が発生する可能性のあるSQLを(全てではないにしろ)検出し、開発者に修正を促すことができる。ここではそのようなSQLを考えてみたい。
2.バインドミスマッチのSQLの特定方法
v$sql_bind_captureには、SQL_ID毎に、バインドポジションとバインド型の情報が格納されている。バインドミスマッチが発生している場合は、同じバインドポジションに異なる複数のバインド型が割り当てられるはずである。この性質を利用して、SQL_ID、バインドポジション、データ型を重複排除し、データ型を複数持つSQL_IDを抽出する。通常はSYS等のシステム系のSQLには興味がないだろうから、v$sqlareaと外部結合してユーザ情報や実行回数、バージョンカウントもあわせて表示する。
上記のアイディアのもと、以下が実際に考えてみたSQLである。バインドミスマッチを起こしていると思われるSQLID一覧を表示するSQLである。
rem (A) sql_ids that have more than one bind types for the same column, order by executions desc
col parsing_schema_name for a20
select t1.con_id, t1.sql_id, num_position, t2.parsing_schema_name, t2.executions, t2.version_count from (
select con_id, sql_id, count(*) num_position
from (
select con_id, sql_id, position, count(*)
from (select distinct con_id, sql_id, position, datatype from v$sql_bind_capture)
group by con_id, sql_id, position having count(*) > 1
)
group by con_id, sql_id
) t1,
v$sqlarea t2
where t1.con_id=t2.con_id(+) and t1.sql_id=t2.sql_id(+) order by executions desc;
SQLだけではイメージがわかないので、実際の実行結果を見てほしい。環境はOCIのADB(ATP)で19.23である。
CON_ID SQL_ID NUM_POSITION PARSING_SCHEMA_NAME EXECUTIONS VERSION_COUNT
---------- ------------- ------------ -------------------- ---------- -------------
326 4f2g5hu1c7yu3 1 SYS 40 2
326 2szhjcqs9agym 1 SYS 29 2
326 fs7h3cb49hs7s 2 SYS 8 2
326 a8ybwb4wf635t 1 SYS 5 2
326 dqdaup2z1508s 2 SYS 5 2
326 bmrrsf60dp618 1 SYS 5 2
326 3sp9hj44p632r 5 SYS 5 2
326 ch8t72tsys7vx 1 SYS 5 2
326 fu9xz9pnu520q 1 SYS 3 2
9 rows selected.
例えば、一番上の4f2g5hu1c7yu3は、1か所のバインドポジションにおいて、バインドミスマッチが発生している。このSQLはSYSで実行されており、実行回数累計40回、バージョンカウントは2であることがわかる。1か所のバインドミスマッチであれば、子カーソルが増えてもたかが知れているし、実行回数もたいして多くないため、問題ない、ということがわかる。下から3番目の3sp9hj44p632rは、5か所のバインドポジションにおいて、バインドミスマッチが発生している。仮にこのバリエーションが増えると、最大2^5=~32個程度だろうし、問題ない。
仮に上記で問題となりそうなSQLが見つかったとき、具体的にどのようなバインドミスマッチが発生しているかが気になる。バインドポジション毎にどのような型が使われているのかを表示するSQLが以下である。
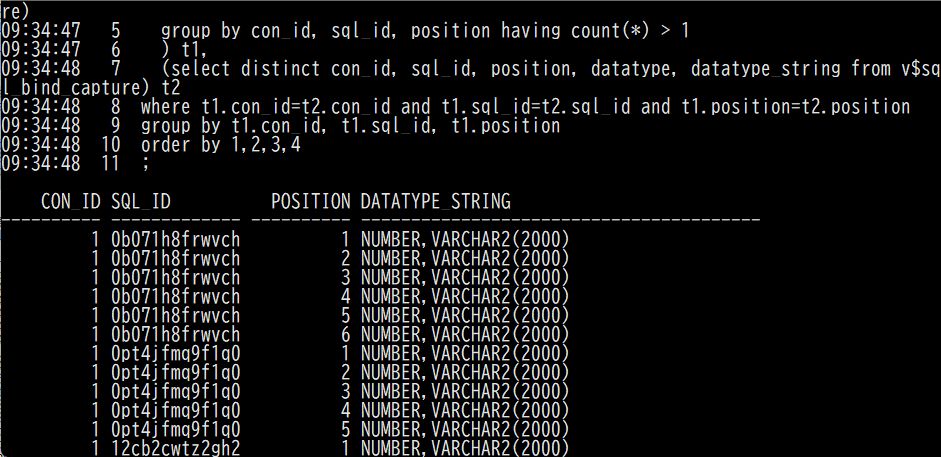
rem (B) bind type names for each sql_id and bind position col datatype_string for a40 select t1.con_id, t1.sql_id, t1.position, listagg(t2.datatype_string,',') within group (order by t2.position) datatype_string from (select con_id, sql_id, position,count(*) from (select distinct con_id, sql_id, position, datatype from v$sql_bind_capture) group by con_id, sql_id, position having count(*) > 1 ) t1, (select distinct con_id, sql_id, position, datatype, datatype_string from v$sql_bind_capture) t2 where t1.con_id=t2.con_id and t1.sql_id=t2.sql_id and t1.position=t2.position group by t1.con_id, t1.sql_id, t1.position order by 1,2,3,4 ;
こちらの実行結果は以下の通り。
CON_ID SQL_ID POSITION DATATYPE_STRING
---------- ------------- ---------- ----------------------------------------
326 2szhjcqs9agym 1 NUMBER,VARCHAR2(2000)
326 3sp9hj44p632r 1 NUMBER,VARCHAR2(2000)
326 3sp9hj44p632r 2 NUMBER,VARCHAR2(2000)
326 3sp9hj44p632r 3 NUMBER,VARCHAR2(2000)
326 3sp9hj44p632r 4 NUMBER,VARCHAR2(2000)
326 3sp9hj44p632r 5 NUMBER,VARCHAR2(2000)
326 4f2g5hu1c7yu3 1 NUMBER,VARCHAR2(2000)
326 a8ybwb4wf635t 1 NUMBER,VARCHAR2(2000)
326 bmrrsf60dp618 1 NUMBER,VARCHAR2(2000)
326 ch8t72tsys7vx 1 NUMBER,VARCHAR2(2000)
326 dqdaup2z1508s 1 NUMBER,VARCHAR2(2000)
326 dqdaup2z1508s 2 NUMBER,VARCHAR2(2000)
326 fs7h3cb49hs7s 1 NUMBER,VARCHAR2(2000)
326 fs7h3cb49hs7s 2 NUMBER,VARCHAR2(2000)
326 fu9xz9pnu520q 1 NUMBER,VARCHAR2(2000)
15 rows selected.
例えば、3sp9hj44p632rを見てみると、バインドポジションが1から5について、NUMBER型とVARCHAR2(2000)でバインドミスマッチが発生していることがわかる。他のSQLについても、この例では全てNUMBERとVARCHAR2(2000)のバインドミスマッチである。
以下の例は、BaseDBの19.20であるが、DATEとVARCHAR2(2000)でバインドミスマッチが発生している。実際のアプリケーションではTIMESTAMP型やLOB型も出てくるかもしれない。
CON_ID SQL_ID POSITION DATATYPE_STRING
---------- ------------- ---------- ----------------------------------------
...
3 531x22ur6bxc1 1 NUMBER,VARCHAR2(2000)
3 531x22ur6bxc1 2 NUMBER,VARCHAR2(2000)
3 531x22ur6bxc1 4 NUMBER,VARCHAR2(2000)
3 531x22ur6bxc1 7 DATE,VARCHAR2(2000)
3 531x22ur6bxc1 10 DATE,VARCHAR2(2000)
3 59xng0tdsqw0s 1 NUMBER,VARCHAR2(2000)
3 59xng0tdsqw0s 2 NUMBER,VARCHAR2(2000)
3 59xng0tdsqw0s 4 NUMBER,VARCHAR2(2000)
3 59xng0tdsqw0s 5 DATE,VARCHAR2(2000)
...
リスクのあるSQL_IDが特定できたら、この後の流れは通常と同じである。以下のようにv$sql_bind_captureでSQL_IDを指定してバインド型の状態を確認する。
select con_id,sql_id, child_number, position, datatype, datatype_string from v$sql_bind_capture
where sql_id='3sp9hj44p632r';
CON_ID SQL_ID CHILD_NUMBER POSITION DATATYPE DATATYPE_STRING
---------- ------------- ------------ ---------- ---------- ----------------------------------------
4 3sp9hj44p632r 3 1 2 NUMBER
4 3sp9hj44p632r 3 2 2 NUMBER
4 3sp9hj44p632r 3 3 2 NUMBER
4 3sp9hj44p632r 3 4 2 NUMBER
4 3sp9hj44p632r 3 5 2 NUMBER
4 3sp9hj44p632r 2 1 1 VARCHAR2(2000)
4 3sp9hj44p632r 2 2 1 VARCHAR2(2000)
4 3sp9hj44p632r 2 3 1 VARCHAR2(2000)
4 3sp9hj44p632r 2 4 1 VARCHAR2(2000)
4 3sp9hj44p632r 2 5 1 VARCHAR2(2000)
SQL_IDのSQLはv$sqlareaで確認できるだろう。アプリケーションのスキーマとSQLが特定できれば、開発者に修正を促すことができる。
col sql_text for a60
col parsing_schema_name for a20
select sql_id, parsing_schema_name, sql_text from v$sqlarea where sql_id='3sp9hj44p632r'
SQL_ID PARSING_SCHEMA_NAME SQL_TEXT
------------- -------------------- ------------------------------------------------------------
3sp9hj44p632r SYS select 1, max(id) from wri$_adv_objects where task_id = :1
union all select 2, max(id) from wri$_adv_recommendations w
here task_id = :1 union all select 3, max(id) from wri$_adv_
actions where task_id = :1 union all select 4, max(id) from
wri$_adv_findings where task_id = :1 union all select 5, m
ax(id) from wri$_adv_rationale where task_id = :1
3.考察
この方法で検出されたSQLについてアプリケーションの修正を促すべきSQLをどう評価したらよいだろうか。バインドミスマッチはバインドポジション数に対し2のべき乗で増加する。(A)のNUM_POSITIONが10以下であるSQLは子カーソル数は最大でもたかだか1000程度であり、Oracleのデフォルトの子カーソル数の閾値(19cで8,192)に十分収まる範囲と考えられる。(A)のNUM_POSITIONが10より大きいSQLIDについてはデータのバリエーションにより子カーソル数が1000を超えるリスクがあるため、アプリケーションを修正することが望ましいだろう。ただ実際は、業務特性として(A)のEXECUTIONSが大きくならず、並列実行されないことがわかっているのであれば、アプリケーション修正なしでも問題は顕在化しない。そう考えると、やはり一番の入り口は、バインドポジションの数である。バインドポジション数が極端に大きなSQLがないか、そこで子カーソル数が多くなっていないか、このSQLは業務的に頻繁に並列に実行される特性のものか、を確認し、全てYESならアプリケーションを修正した方が良いと私は考える。
(A)や(B)のSQLをどのタイミングで利用すべきだろうか。(A)は結合試験以降である程度実際の業務に近い状態にならないと、データバリエーションや実行回数が意味のある数字にならないだろう。それでも、リスクのあるSQLを早期に特定する目的には使える。(B)は単体試験から使えるだろう。NULL値等のバリエーションを含めた機能的な試験を行うだろうから、バインドミスマッチが発生するようなコーディングを検出できる可能性がある。
4.まとめ
本記事では、バインドミスマッチが発生しているSQLを特定する方法について述べた。この方法では、SQLの実行回数、子カーソル数とあわせて、バインドミスマッチが発生しているバインドポジション数を見て評価ができる点がポイントである。思い付きのプロトタイプレベルのSQLではあるものの、今後の開発の中で利用して改善していければと思っている。
MOSのDocID 438755.1のドキュメント[1]に、子カーソルが増加しているSQLのレポートを作成するスクリプトが公開されているので、こちらとあわせて使うとよいだろう。
参考
[1] Document 438755.1 High SQL Version Counts - Script to determine reason(s)
2024-04-01 09:41
Oracle 23c freeのオプティマイザ関連パラメータを調べる [オプティマイザ]
1.はじめに
4/5未明のOracle ACE向けアナウンスで、オラクル社のGerald Venzl氏からOracle Database 23c Freeがリリースされたとの説明があった(参考[1])。これは開発者向けの無償版で、従来Xeと呼ばれていたものに相当するそうだ。正式な23cは現在ベータテスト中である中、開発者向けを無償で先にリリースするのは、23cのDeveloper firstの姿勢の本気度を感じさせられる。RACやDataGuardのような機能は使えないが、JSON等の新機能を試したりすることができるのは開発者に取って朗報だろう。正式なサポートはないが、Oracle Forumにスレッドがあるので活用するとよいだろう(参考[2])。
23cのリリースでまず一番私が確認したかったのは、オプティマイザに影響を与えるパラメータである。デフォルト値が変更されたものや、新機能として追加されたものを把握することは、いずれ必要となる19cからの移行作業で必ず必要となるためである。本稿では、23cのオプティマイザ関連のパラメータについて、その調査方法と結果ついて共有したい。
なお、Oracle Database 23c Freeの導入方法については、すでに日本語で紹介したブログもあるので、ここで特筆する必要はないだろう。ちなみに、私はVirtual Box VMのイメージを使ったが、特段難しいことはなく利用することができた。
2.オプティマイザのパラメータ確認方法
オプティマイザに影響を与えるパラメータの確認方法はいくつかあるが、私が個人的に最も信頼しているのは10053トレースである。10053トレースの取得方法は以下の通り。今回の場合SQLはなんでも良いので、select 1 from dualとした。
-- to enable the 10053 trace alter session set events '10053 trace name context forever'; execute any SQL -- stop tracing alter session set events '10053 trace name context off';
結果は以下のようにtraceディレクトリ配下にSID_ora_PID.trcという名前で出力される。
[oracle@localhost trace]$ ls -ltr /opt/oracle/diag/rdbms/free/FREE/trace/ | tail -rw-r-----. 1 oracle oinstall 7077 Apr 5 20:23 FREE_dbrm_1924.trm -rw-r-----. 1 oracle oinstall 37378 Apr 5 20:23 FREE_dbrm_1924.trc -rw-r-----. 1 oracle oinstall 68439 Apr 5 20:23 FREE_ora_12524.trm -rw-r-----. 1 oracle oinstall 126447 Apr 5 20:23 FREE_ora_12524.trc ★ -rw-r-----. 1 oracle oinstall 1731 Apr 5 20:27 FREE_gcr2_12649.trm
トレースファイルの中を確認すると、以下のようにPARAMETERS USED BY THE OPTIMIZERというセクションがあり、そこにオプティマイザに影響を与える(隠し)初期化パラメータが出力される。PARAMETERS WITH ALTERED VALUESはデフォルト値から変更されたパラメータ、PARAMETERS WITH DEFAULT VALUESはデフォルト値から変更のないパラメータを表す。
Trace file /opt/oracle/diag/rdbms/free/FREE/trace/FREE_ora_12524.trc Oracle Database 23c Free, Release 23.0.0.0.0 - Developer-Release Version 23.2.0.0.0 ... *************************************** PARAMETERS USED BY THE OPTIMIZER ******************************** ************************************* PARAMETERS WITH ALTERED VALUES ****************************** Compilation Environment Dump _swat_ver_mv_knob = 0 Bug Fix Control Environment ************************************* PARAMETERS WITH DEFAULT VALUES ****************************** Compilation Environment Dump optimizer_mode_hinted = false optimizer_features_hinted = 0.0.0 parallel_execution_enabled = false parallel_query_forced_dop = 0 parallel_dml_forced_dop = 0 parallel_ddl_forced_degree = 0 parallel_ddl_forced_instances = 0 _query_rewrite_fudge = 90 optimizer_features_enable = 23.1.0
多くの初期化パラメータは_(アンダースコア)が接頭辞となる隠しパラメータであり、マニュアルには記載されていない。このため、以下のSQLでそれぞれのパラメータの説明を取得する(x$ksppi.ksppdescに初期化パラメータの説明がある)。簡単な説明しかないものの、概ねどのような機能を持つのかくらいのことはわかるだろう。
set markup csv on
spool /tmp/initparam19c.csv
SELECT a.ksppinm "Parameter", b.KSPPSTDF "Default Value", a.KSPPDESC "DESCRIPTION",
b.ksppstvl "Session Value",
c.ksppstvl "Instance Value",
decode(bitand(a.ksppiflg/256,1),1,'TRUE','FALSE') IS_SESSION_MODIFIABLE,
decode(bitand(a.ksppiflg/65536,3),1,'IMMEDIATE',2,'DEFERRED',3,'IMMEDIATE','FALSE') IS_SYSTEM_MODIFIABLE
FROM x$ksppi a,
x$ksppcv b,
x$ksppsv c
WHERE a.indx = b.indx
AND a.indx = c.indx
order by 1
/
3.取得結果
上記の確認方法を使って、Oracle Database 23c Freeと、Oracle 19.11.0(EE)とで比較を行った。比較結果の詳細を確認したい場合は、参考[3]を参照されたい。ここでは主な変更点について記載しておきたい。
まず全体のパラメータ数は、23cが658個に対して、19cは613個と45増えている。具体的には以下の通り、23cの新規パラメータは46個あり、19cにあって23cにないパラメータが1つ存在した。19cからの移行においては、新しいオプティマイザの機能追加が想定しない挙動(実行計画)となる可能性があるため、必要に応じて見直しする対象となるだろう(具体的には値がtrueとなっているものは、機能を無効とするためにfalseに変更するといった対処など)。
◇23cのオプティマイザ関連の新規パラメータ
| # | 23.2.0 | value | description |
| 10 | _ansi_join_mv_rewrite_enabled | true | enable/disable ansi join mv rewrite |
| 17 | _autoptn_costing | false | DBMS_AUTO_PARTITION is compiling query for cost estimates |
| 40 | _cell_index_scan_enabled | true | enable CELL processing of index FFS |
| 41 | _cell_iot_scan_enabled | true | enable CELL processing of IOT FFS |
| 44 | _cell_metadata_compression | AUTO | Cell metadata compression strategy |
| 62 | _cross_con_remove_pushed_preds | false | remove pushed predicates from query fetching across containers |
| 82 | _enable_columnar_cache | 1 | enable 12g bigfile tablespace |
| 109 | _groupby_orderby_combine | 5000 | groupby/orderby don't combine threshold |
| 123 | _inmemory_hpk4sql_flags | 0 | In-Memory HPK4SQL flags |
| 129 | _json_qryovergen_rewrite | true | enable/disable JSON query over generation function rewrite |
| 160 | _obsolete_result_cache_mode | MANUAL | USERS SHOULD NOT SET THIS! Used for old qksced parameterof result_cache_mode |
| 232 | _optimizer_exists_to_any_rewrite | true | consider exists-to-any rewrite of subqueries |
| 286 | _optimizer_nested_loop_join | on | favor/unfavor nested loop join |
| 303 | _optimizer_push_gby_into_union_all | true | consider pushing down group-by into union-all branches |
| 323 | _optimizer_subsume_vw_sq | on | consider subsumption of views or subqueries |
| 341 | _optimizer_use_stats_models | false | use optimizer statistics extrapolation models |
| 353 | _optimizer_wc_filter_pushdown | true | enable/disable with clause filter predicate pushdown |
| 387 | _px_adaptive_dist_nij_enabled | on | enable adaptive distribution methods for left non-inner joins |
| 399 | _px_extended_join_skew_handling | true | enables extended skew handling for parallel joins |
| 424 | _px_parallelize_non_native_datatype | true | enable parallelization for non-native datatypes |
| 427 | _px_partition_load_skew_handling | on | enable partition load skew handling |
| 428 | _px_partition_load_skew_threshold | 3 | partition loads bigger than threshold times average are skewed |
| 446 | _px_window_skew_handling | true | enable window function skew handling |
| 447 | _qa_lrg_type | 0 | Oracle internal parameter to specify QA lrg type |
| 491 | _rowsets_use_work_heap_buffer | true | allow/disallow use of work heap buffer for values for rowsets |
| 497 | _slave_mapping_skew_handling | true | enables skew handling for slave mapping plans |
| 516 | _sqlexec_hash_based_distagg_ser_civ_enabled | true | enable hash based distinct aggregation in serial/CIV queries |
| 518 | _sqlexec_hash_based_set_operation_enabled | true | enable/disable hash based set operation |
| 519 | _sqlexec_hash_rollup_enabled | true | enable hash rollup |
| 523 | _sqlexec_use_delayed_unpacking | true | enable/disable the usage of delayed unpacking |
| 526 | _sqlexec_window_function_settings | 63 | execution settings for window functions |
| 531 | _swat_ver_mv_knob | 0 | Knob to control MV/REWRITE behavior |
| 542 | _use_dirty_reads | 0 | enable the use of column statistics for DDP functions |
| 553 | _zonemap_refresh_within_load | true | Control the refresh of basic zonemaps during/after data load |
| 574 | escrow_dirty_cursor | 0 | whether to encrypt newly created tablespaces |
| 575 | escrow_internal_cursor | 0 | whether to encrypt newly created tablespaces |
| 578 | group_by_position_enabled | false | enable/disable group by position |
| 579 | gwr_trigger_enabled | 0 | enable/disable group by position |
| 589 | json_expression_check | off | enable/disable JSON query statement check |
| 591 | memoptimize_writes | HINT | write data to IGA without memoptimize_write hint |
| 597 | optimizer_cross_shard_resiliency | false | enables resilient execution of cross shard queries |
| 614 | optimizer_use_sql_quarantine | true | enable use of sql quarantine |
| 644 | shard_enable_raft_follower_read | true | enable read from follower replications units in a shard |
| 645 | shard_queries_restricted_by_key | false | add shard key predicates to the query |
| 656 | translate_table_name_hash | 0 | number of active transactions per rollback segment |
| 658 | valid_shard_session_key | 0 | User process dump directory |
◇23cで廃止されたオプティマイザ関連の新規パラメータ
| 19.11.0 | value | description |
| _optimizer_quarantine_sql | true | enable use of sql quarantine |
次に、同じパラメータであるが値が異なるものを調べたところ、27個あった。この27のうち、19cで私が意図的に変更したものや、バージョンや環境に依存するもの(CPU数やメモリサイズ等)を除くと、以下の4つのパラメータが残った。これらデフォルト値が変わっているものもオプティマイザの挙動に影響を与えるため、移行時は留意する必要がある。
◇19cと23cでデフォルト値が変更されたオプティマイザ系パラメータ
| # | 23.2.0 | value | description |
| 36 | _cdb_special_old_xplan | false | display old-style plan for CDB special fixed table |
| 275 | _optimizer_key_vector_payload_dim_aggs | true | enables or disables dimension payloading of aggregates in VT |
| 515 | _sqlexec_hash_based_distagg_enabled | true | enable hash based distinct aggregation for gby queries |
| 626 | parallel_execution_enabled | false | policy used to compute the degree of parallelism (MANUAL/LIMITED/AUTO/ADAPTIVE) |
4.おわりに
本稿では23cのOracle Database Freeと、19.11.0(EE)のオプティマイザ関連パラメータを、10053トレースを取得し比較した。Developer EditionとEEではそもそも異なる設定もあるだろうし、そもそも23cのEE版はベータテスト中という状況であるので、この結果を直接どうこう議論できるものではないだろう。実際の移行においては、23cが正式にリリースされた後、同様の方法でオプティマイザの挙動に影響するパラメータを洗い出す必要があるだろう。それでも、23cと19cでどの程度の変更があるのかの感覚を掴むことはできたと思う。
以上
参考
[1]:Introducing Oracle Database 23c Free - Developer Release, Oracle Database Insider, Gerald Venzl
[2]:Oracle Database Free - Developer Release, Oracle Forum
[3]:オプティマイザ関連初期化パラメータの差分確認結果(23cと19c)(OptimizerParameter23vs19.xlsx)
2023-04-09 13:04
コメント(0)
SQLプロファイルによるリテラルSQLのチューニング [オプティマイザ]
1.はじめに
SQLチューニングでアプリケーションのSQLにヒント句を追加することは、開発中のアプリケーションであればそれほど難しくない。しかし、運用中システムにおいて、アプリケーションのSQLに変更を加えることはまま難しいことがある。パッケージ等のサードパーティ製のアプリケーションだけでなく、様々なできない理由によりアプリケーションをリリースすることができず、故にデータベース層で実行計画の変更が必要となる。
Oracleにおいて、このようなときに使える一般的な機能はSPM(SQL Plan Management)であろう。SPMは特定のSQLIDに紐づく実行計画を(複数)保持し、オプティマイザはその中で許可された実行計画を選択するようにすることができる。実行計画の固定化のために利用するのが一般的だが、上記のような状況においては、ヒント句により得られた所望の実行計画を特定のSQLIDに紐づけることができる(参考[1])。SPMはEEであれば利用できる。
SQLパッチは任意のSQLにヒントを付与するOracleの機能である。dbms_sqldiag.create_sql_patchプロシージャを使い、特定のSQLIDに対し指定したヒント句を埋め込むことができる。汎用性は高いが、ヒント句の指定方法にクエリーブロックを利用する必要があり、複雑なSQLでは利用することが難しい(参考[2])。SQLパッチは特段ライセンスの縛りはない。
しかし、バインド変数を利用しない、いわゆるリテラルSQLの場合は上記いずれの方法も厳しい。もちろんcursor_sharingをFORCEにしていれば、リテラルSQLは自動的にバインド変数に変換され、その変換されたSQLIDに対してSQLパッチを作ることは可能である。しかし、商用のOracleデータベースにおいては、cursor_sharingはEXACTとするのが一般的であり、特定のSQLのチューニングのためにデータベース全体の挙動を変えるような設定変更をすることは本末転倒であろう。
先日たまたまMike Dietrich氏の講演を聞く機会があり、リテラルSQLのチューニングにSQLプロファイルが使えるという話を聞いた。SQLプロファイルは、SQLチューニングアドバイザにより推奨されたチューニング案をアクセプトすると作成され、特定のSQLの実行計画を制御することができる(SQL Tuning Packライセンスが必要)。SPMとの大きな違いはFORCE_MATCHパラメータをTRUEにすることで、リテラルSQLにたいしてヒントを入れることができることである。ここでは、実際にリテラルSQLに対してFORCE_MATCHを有効にして、SQLプロファイルでヒントを入れる検証をしてみよう。
2.検証モデル
検証環境はOracle19.11、cursor_sharingはEXACTとする。
SQL> select BANNER_LEGACY from v$version; BANNER_LEGACY _________________________________________________________________________ Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production SQL> show parameter cursor_sharing NAME TYPE VALUE -------------- ------ ----- cursor_sharing string EXACT
検証用の表としてempを100万件,dept10万件を利用する。
SQL> select count(*) from emp;
COUNT(*)
___________
1000000
SQL> select count(*) from dept;
COUNT(*)
___________
100000
以下のように2つの表を結合し、empnoで絞り込むシンプルなクエリを考える。リテラルでempnoを絞り込む条件を10件、10万件、90万の3パターンで変更すると、リテラルの違いによりSQL_IDはそれぞれ異なる(cursor_sharingがEXACTであるため)。また、統計情報からemp表の絞り込みの件数を推定できるため、それぞれの条件で実行計画が異なる。
SQL> select * from emp t1, dept t2 where t1.deptno=t2.deptno and t1.empno<10;
9 rows selected.
PLAN_TABLE_OUTPUT
____________________________________________________________________________________
SQL_ID dwfrphnyytybk, child number 0
-------------------------------------
select * from emp t1, dept t2 where t1.deptno=t2.deptno and t1.empno<10 ★
Plan hash value: 2259671826
------------------------------------------------------------------
| Id | Operation | Name | E-Rows |
------------------------------------------------------------------
| 0 | SELECT STATEMENT | | |
| 1 | NESTED LOOPS | | 9 |
| 2 | NESTED LOOPS | | 9 |
| 3 | TABLE ACCESS BY INDEX ROWID BATCHED| EMP | 9 |
|* 4 | INDEX RANGE SCAN | PK_EMP | 9 |
|* 5 | INDEX UNIQUE SCAN | PK_DEPT | 1 |
| 6 | TABLE ACCESS BY INDEX ROWID | DEPT | 1 |
------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("T1"."EMPNO"<10)
5 - access("T1"."DEPTNO"="T2"."DEPTNO")
SQL> select * from emp t1, dept t2 where t1.deptno=t2.deptno and t1.empno<100000; ★
99,999 rows selected.
PLAN_TABLE_OUTPUT
______________________________________________________________________________________________
SQL_ID 1zay58r4dxstz, child number 0
-------------------------------------
select * from emp t1, dept t2 where t1.deptno=t2.deptno and
t1.empno<100000
Plan hash value: 3839690129
-------------------------------------------------------------------------------------------
| Id | Operation | Name | E-Rows | OMem | 1Mem | Used-Mem |
-------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | | |
|* 1 | HASH JOIN | | 99999 | 9465K| 3157K| 9866K (0)|
| 2 | TABLE ACCESS FULL | DEPT | 100K| | | |
| 3 | TABLE ACCESS BY INDEX ROWID BATCHED| EMP | 99999 | | | |
|* 4 | INDEX RANGE SCAN | PK_EMP | 99999 | | | |
-------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("T1"."DEPTNO"="T2"."DEPTNO")
4 - access("T1"."EMPNO"<100000)
SQL> select * from emp t1, dept t2 where t1.deptno=t2.deptno and t1.empno<900000; ★
899,999 rows selected.
PLAN_TABLE_OUTPUT
____________________________________________________________________________________
SQL_ID 11smn0k8ffaam, child number 0
-------------------------------------
select * from emp t1, dept t2 where t1.deptno=t2.deptno and
t1.empno<900000
Plan hash value: 615168685
-----------------------------------------------------------------------
| Id | Operation | Name | E-Rows | OMem | 1Mem | Used-Mem |
-----------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | | |
|* 1 | HASH JOIN | | 892K| 9465K| 3157K| 9978K (0)|
| 2 | TABLE ACCESS FULL| DEPT | 100K| | | |
|* 3 | TABLE ACCESS FULL| EMP | 900K| | | |
-----------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("T1"."DEPTNO"="T2"."DEPTNO")
3 - filter("T1"."EMPNO"<900000)
3.SQLプロファイルによるチューニング
このような状況で、SQLを変更することなく、実行計画をチューニング(ヒント付与)してみよう。ここでは、リテラルがどのような値であったとしても、1番目のNestedLoop結合としてみたい。リテラルの値によりSQLIDが異なるため、SPMもSQLパッチも使えないので、SQLプロファイルを使う。
まず、所望の実行計画を作成するためのアウトラインを確認する。方法は以下のようにexplain plan forを使う。
SQL> explain plan for select * from emp t1, dept t2 where t1.deptno=t2.deptno and t1.empno<10
Explained.
Elapsed: 00:00:00.006
SQL> select * from table(dbms_xplan.display(null,null,'+outline'));
PLAN_TABLE_OUTPUT
____________________________________________________________________________________________________
Plan hash value: 2259671826
-------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 9 | 792 | 13 (0)| 00:00:01 |
| 1 | NESTED LOOPS | | 9 | 792 | 13 (0)| 00:00:01 |
| 2 | NESTED LOOPS | | 9 | 792 | 13 (0)| 00:00:01 |
| 3 | TABLE ACCESS BY INDEX ROWID BATCHED| EMP | 9 | 486 | 4 (0)| 00:00:01 |
|* 4 | INDEX RANGE SCAN | PK_EMP | 9 | | 3 (0)| 00:00:01 |
|* 5 | INDEX UNIQUE SCAN | PK_DEPT | 1 | | 0 (0)| 00:00:01 |
| 6 | TABLE ACCESS BY INDEX ROWID | DEPT | 1 | 34 | 1 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------------
Outline Data
-------------
/*+
BEGIN_OUTLINE_DATA
NLJ_BATCHING(@"SEL$1" "T2"@"SEL$1")
USE_NL(@"SEL$1" "T2"@"SEL$1") ★
LEADING(@"SEL$1" "T1"@"SEL$1" "T2"@"SEL$1") ★
INDEX(@"SEL$1" "T2"@"SEL$1" ("DEPT"."DEPTNO")) ★
BATCH_TABLE_ACCESS_BY_ROWID(@"SEL$1" "T1"@"SEL$1")
INDEX_RS_ASC(@"SEL$1" "T1"@"SEL$1" ("EMP"."EMPNO")) ★
OUTLINE_LEAF(@"SEL$1")
ALL_ROWS
OPT_PARAM('_optimizer_nlj_hj_adaptive_join' 'false')
OPT_PARAM('_optimizer_strans_adaptive_pruning' 'false')
OPT_PARAM('_px_adaptive_dist_method' 'off')
OPT_PARAM('_optimizer_gather_stats_on_load' 'false')
OPT_PARAM('_optimizer_use_feedback' 'false')
OPT_PARAM('optimizer_dynamic_sampling' 0)
OPT_PARAM('_optim_peek_user_binds' 'false')
DB_VERSION('19.1.0')
OPTIMIZER_FEATURES_ENABLE('19.1.0')
IGNORE_OPTIM_EMBEDDED_HINTS
END_OUTLINE_DATA
*/
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("T1"."EMPNO"<10)
5 - access("T1"."DEPTNO"="T2"."DEPTNO")
PDBのSYSで接続し、IMPORT_SQL_PROFILEプロシージャを実行する。ここで引数として、SQL文と上記アウトラインで必要と思われるヒント句(★の部分)を指定する。また、リテラルが変わってもこのヒントが有効となるよう、FORCE_MATCHをtrue(有効)とする。
DECLARE
sql_text CLOB;
BEGIN
select sql_fulltext into sql_text from v$sqlarea where sql_id='dwfrphnyytybk';
DBMS_SQLTUNE.IMPORT_SQL_PROFILE(
SQL_TEXT => sql_text, ★
PROFILE => SQLPROF_ATTR('USE_NL(@"SEL$1" "T2"@"SEL$1") LEADING(@"SEL$1" "T1"@"SEL$1" "T2"@"SEL$1") INDEX(@"SEL$1" "T2"@"SEL$1" ("DEPT"."DEPTNO")) INDEX_RS_ASC(@"SEL$1" "T1"@"SEL$1" ("EMP"."EMPNO"))'), ★
NAME => 'pf_dwfrphnyytybk',
REPLACE => true,
FORCE_MATCH => true ★
);
END;
/
SQL> select name,sql_text,status,force_matching from dba_sql_profiles;
NAME SQL_TEXT STATUS FORCE_MATCHING
___________________ __________________________________________________________________________ __________ _________________
pf_dwfrphnyytybk select * from emp t1, dept t2 where t1.deptno=t2.deptno and t1.empno<10 ENABLED YES
この状態で先に実行した3つの条件でSQLを実行してみよう。
SQL> select * from emp t1, dept t2 where t1.deptno=t2.deptno and t1.empno<10;
9 rows selected.
PLAN_TABLE_OUTPUT
____________________________________________________________________________________
SQL_ID dwfrphnyytybk, child number 0
-------------------------------------
select * from emp t1, dept t2 where t1.deptno=t2.deptno and t1.empno<10
Plan hash value: 2259671826 ★
------------------------------------------------------------------
| Id | Operation | Name | E-Rows |
------------------------------------------------------------------
| 0 | SELECT STATEMENT | | |
| 1 | NESTED LOOPS | | 9 |
| 2 | NESTED LOOPS | | 9 |
| 3 | TABLE ACCESS BY INDEX ROWID BATCHED| EMP | 9 |
|* 4 | INDEX RANGE SCAN | PK_EMP | 9 |
|* 5 | INDEX UNIQUE SCAN | PK_DEPT | 1 |
| 6 | TABLE ACCESS BY INDEX ROWID | DEPT | 1 |
------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("T1"."EMPNO"<10)
5 - access("T1"."DEPTNO"="T2"."DEPTNO")
Note
-----
- SQL profile pf_dwfrphnyytybk used for this statement ★
SQL> select * from emp t1, dept t2 where t1.deptno=t2.deptno and t1.empno<100000;
99,999 rows selected.
PLAN_TABLE_OUTPUT
____________________________________________________________________________________
SQL_ID 1zay58r4dxstz, child number 0
-------------------------------------
select * from emp t1, dept t2 where t1.deptno=t2.deptno and
t1.empno<100000
Plan hash value: 2259671826 ★
------------------------------------------------------------------
| Id | Operation | Name | E-Rows |
------------------------------------------------------------------
| 0 | SELECT STATEMENT | | |
| 1 | NESTED LOOPS | | 99999 |
| 2 | NESTED LOOPS | | 99999 |
| 3 | TABLE ACCESS BY INDEX ROWID BATCHED| EMP | 99999 |
|* 4 | INDEX RANGE SCAN | PK_EMP | 99999 |
|* 5 | INDEX UNIQUE SCAN | PK_DEPT | 1 |
| 6 | TABLE ACCESS BY INDEX ROWID | DEPT | 1 |
------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("T1"."EMPNO"<100000)
5 - access("T1"."DEPTNO"="T2"."DEPTNO")
Note
-----
- SQL profile pf_dwfrphnyytybk used for this statement ★
SQL> select * from emp t1, dept t2 where t1.deptno=t2.deptno and t1.empno<900000;
899,999 rows selected.
PLAN_TABLE_OUTPUT
____________________________________________________________________________________
SQL_ID 11smn0k8ffaam, child number 0
-------------------------------------
select * from emp t1, dept t2 where t1.deptno=t2.deptno and
t1.empno<900000
Plan hash value: 2259671826 ★
------------------------------------------------------------------
| Id | Operation | Name | E-Rows |
------------------------------------------------------------------
| 0 | SELECT STATEMENT | | |
| 1 | NESTED LOOPS | | 892K|
| 2 | NESTED LOOPS | | 900K|
| 3 | TABLE ACCESS BY INDEX ROWID BATCHED| EMP | 900K|
|* 4 | INDEX RANGE SCAN | PK_EMP | 900K|
|* 5 | INDEX UNIQUE SCAN | PK_DEPT | 1 |
| 6 | TABLE ACCESS BY INDEX ROWID | DEPT | 1 |
------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("T1"."EMPNO"<900000)
5 - access("T1"."DEPTNO"="T2"."DEPTNO")
Note
-----
- SQL profile pf_dwfrphnyytybk used for this statement ★
上記3つのケース全てNested Loop、同一PHVとなり、Noteに作成したSQLプロファイルが使われていることがわかる。
4.SQLプロファイルの削除
不要となったSQLプロファイルは以下のように削除する。
exec dbms_sqltune.drop_sql_profile('pf_dwfrphnyytybk');
SQL> exec dbms_sqltune.drop_sql_profile('pf_dwfrphnyytybk');
PL/SQL procedure successfully completed.
SQL> select name,sql_text,status,force_matching from dba_sql_profiles;
no rows selected
SQL>
5.まとめ
本稿では、リテラルSQLの実行計画をDBで変更する方法についてSQLプロファイルを使う方法について検証した。リテラルSQLについてはSPMやSQLパッチを効果的に使うことが難しいため、SQLに手が入れられないとするとこの方法がほぼ唯一の方法となる可能性がある。もちろん、リテラルのSQLであれば、オプティマイザは統計情報からかなり正確にカーディナリティの見積もりができるため、性能面ではこのようなチューニングが必要となるケースは少ないかもしれない。それでも、リテラルSQLの実行計画を固定化したい場合に、SQL Tuning Packライセンスがあれば、覚えておきたい手法である。
なお、このプロシージャはPL/SQLのマニュアル(参考[3])に記載がないので、恐らく通常の使い方としてはSQLチューニングアドバイザから内部的に使われるものなのかもしれず、利用に際してはあくまでも自己責任となるのかもしれない。
PROCEDURE IMPORT_SQL_PROFILE Argument Name Type In/Out Default? ------------------------------ ----------------------- ------ -------- SQL_TEXT CLOB IN PROFILE SQLPROF_ATTR IN NAME VARCHAR2 IN DEFAULT DESCRIPTION VARCHAR2 IN DEFAULT CATEGORY VARCHAR2 IN DEFAULT VALIDATE BOOLEAN IN DEFAULT REPLACE BOOLEAN IN DEFAULT FORCE_MATCH BOOLEAN IN DEFAULT PROCEDURE IMPORT_SQL_PROFILE Argument Name Type In/Out Default? ------------------------------ ----------------------- ------ -------- SQL_TEXT CLOB IN PROFILE_XML CLOB IN NAME VARCHAR2 IN DEFAULT DESCRIPTION VARCHAR2 IN DEFAULT CATEGORY VARCHAR2 IN DEFAULT VALIDATE BOOLEAN IN DEFAULT REPLACE BOOLEAN IN DEFAULT FORCE_MATCH BOOLEAN IN DEFAULT
◇参考
[1]Oracle Database 19cのSQL計画管理
https://www.oracle.com/technetwork/jp/database/bi-datawarehousing/twp-sql-plan-mgmt-19c-5324207-ja.pdf
[2]Adding and Disabling Hints Using SQL Patch
https://blogs.oracle.com/optimizer/post/adding-and-disabling-hints-using-sql-patch
[3]Oracle Database PL/SQL Packages and Types Reference DBMS_SQLTUNE
https://docs.oracle.com/en/database/oracle/oracle-database/19/arpls/DBMS_SQLTUNE.html#GUID-421606DC-588B-4BCD-8ED8-192F8B93C070
2023-03-11 01:37
コメント(0)
LIKEのワイルドカード検索で性能劣化 [オプティマイザ]
再びコロナの増加が気になる昨今、夏休みを頂き、しばらく更新できなかった本ブログに向き合う時間ができた。今回はOracleのコミュニティ(MOSC)で、索引を使うLIKE検索で性能劣化した事例のトラシューについて記載したい。オリジナルのスレッドはこちらを参照されたい。
今回発生したのは、SELECT文のプレディケート(WHERE句)に、ename LIKE '%ABC%' のようなあいまい検索をした場合で、ename列に張られたB-tree索引を使うときに、'%ABC%'がリテラルの場合は性能が良好なのに、これをバインド変数に置き換えると性能が悪化する、という事象である(実際の事象では、cursor_sharing=forceとして強制的にリテラルをバインド変数にしているが、本質的にはバインド変数を使う場合一般で発生する)。今回、この事象を私の手元の環境(Oracle 19.11)で再現することができたので、以下に再現手順とともに、具体的な問題と対処方法について考察したい。
まず事象を確認するため、以下のようにemp/dept表を作成し、データ(emp表に100万件、dept表に10万件)を挿入、統計を取得する。ここで、emp表のename列にidx_emp_ename索引を作成する。
以下のようにバインドピークを有効にする(デフォルトは有効)。
以下のSQLはemp表、dept表を結合し、emp表のename列をLIKEで'%ABCD%'のようにあいまい検索する。結果10件、実行時間は0.20秒である。なお、ヒントを付与しているのは、恣意的にハッシュ結合を使い、ename列にIDX_EMP_ENAME索引を使うようにしている(これがないと、この例では索引は使われず、emp表を直接フルスキャンしてしまうため)。
同じSQLをバインド変数を用いて実行する。結果は同じだが、実行時間が1.74秒と、リテラルの場合に比べ8~9倍遅い。これはなぜか、この遅い理由を以下で解析する。
はじめに思いつくのは実行計画による違いである。dbms_xplanで実行計画を取得する(ヒントにgather_plan_statisticsを付与し、実行統計も取得する)と、いずれの結果も実行計画はほぼ同じであるが、よく見るとId4がINDEX FULL SCANに対し、遅い方はINDEX RANGE SCANとなっている。いずれの索引アクセス方法にしても、あいまい検索(%が先頭)では全てのリーフブロックをスキャン(シングルブロックリード)しなければならないため、本質的なIO量は変わらないはずである。ではこの性能差はどこから来ているのだろうか。
ここで、上記結果のA-Rowsの値に注目したい。A-Rowsは実際の返却された行数を表す。INDEX FULL SCANのA-Rowsは1000K(100万件)であるのに対し、INDEX RANGE SCANのは10件である。つまり、INDEX FULL SCANはこの処理の中でLIKE '%ABCD%'で10件に絞り込みを行っているのに対し、INDEX RANGE SCANは全く絞り込みを行わず100万件を返却し、その結果、Id3のTABLE ACESS BY INDEX ROWIDでemp表にアクセスしLIKE '%ABCD%'の絞り込みを行い、10件の結果を得ていることがわかる。このことから、遅延の原因はこのId4のINDEX RANGE SCANにおいてLIKEの絞り込みができないことに起因していることがわかる。
この事象は12.2で導入された、バインド変数におけるワイルドカードで開始されるLIKE検索をチェック機能(QKSFM_ACCESS_PATH_20289688)による影響であることが判明した。
実際に、この_fix_controlを無効化して同じSQLを実行すると、あるべき性能が得られ、id4におけるINDEX RANGE SCANの中でLIKE '%ABCD%'の絞り込みが行われることがわかる。
なお、この事象はバインドピークを無効化している場合("_optim_peek_user_binds"=false)は発生しない。これは、バインドピークの機能の中で、バインド値の先頭にワイルドカードが入っているかチェックしているためと思われる。したがって、本事象は12.2以上で、バインドピークを有効化しており、LIKE検索によるあいまい検索を行い、かつ検索にB-tree索引を利用している環境で発生し得る問題と考えられる。ハッシュ結合はこの事象の発生条件に関係ない。1つの表に対する検索でも発生し得る。
考え得る対処方法は以下の通り。
運用開始しており、バインドピークを有効化しているシステムにおいては、システムレベルで(1)(2)を変更することは難しいだろう。性能問題が発生するAPに限りセッションレベルで設定するようAPを改修するか、(3)(4)のヒントを入れるのが現実的だろう。なお、(3)(4)については、SPMやSQLパッチを使えば、APに手を入れずに実行計画を変更することも可能だろう。特にSQLがパッケージから発行されている場合は有効な対処方法となり得る。
QKSFM_ACCESS_PATH_20289688が12.2で導入されてから今まで、なぜこの問題が放置されたままなのか不思議に感じる。この性能問題があったとしても、この機能を残すべき積極的な理由があったのかもしれない。もし、そうでないとすれば、バインドピークを使う場合は、_fix_controlで無効化しておく方が良いのではないか、とさえ思う。
なお、本事象をMOSCのスレッドで解析を進めている中、根本原因を指摘いただいたのはJonathan Lewis氏であった。自分だけでは、よもやオプティマイザの細かな改修の結果によりこの事象が発生しているとは思いもよらなかっただろう。Oracle CoreやCost based optimizerの著者である同氏と直接スレッドでやり取りできたことは、個人的にはこの上ない喜びであった。このようなことを可能としているOracleコミュニティ(MOSC)にも感謝したい。
Jonathan Lewis氏とのその後のやりとりで判明したことを備忘まで以下に追記しておく。v$system_fix_controlを確認すると、10.2.0.1において以下の修正が行われていることがわかる。
3628118 10.2.0.1 QKSFM_ACCESS_PATH_3628118 Do not consider LIKE with leading wildcard as index key
これは%で始まるLIKE検索の場合は、索引を使わないようにするための修正と思われる。そして、今回問題となっている20289688は、これをリテラルでなくバインド変数でも動作するようにキャッチアップしたものと思われる。あくまで想像の域を出ないが、考えられる経緯としては、バインド変数であいまい検索をした際にindex full/range scanになってしまい性能問題が出る事象があり、それについてSRが起票され、開発者がバインド変数でも同じ挙動をさせようと12.2でこの修正を入れたが、その修正の際、HINTで索引を強制的に使う場合の考慮が不足しており、今回のfilterが効かない挙動の違いが生まれてしまったのかもしれない。あくまでも推測ではあるが、なるほどありえそうなシナリオではあると感じる。
さらに、この事象に該当すると思われるバグを指摘頂いた。バグの説明文がまさに本事象と合致している。まだ修正されていないそうだ。
BUG 33500777 - FILTER FOR PREDICATE WITH LIKE AND BIND WITH LEADING WILDCARD IS NOT ALLOCATED ON INDEX SCAN AFTER FIX 20289688
あいまい検索においては一般的に索引を使わない実行計画が多く、絞り込みが効くとあらかじめわかっているケースは少ないだろう。その意味では今回のようにヒントで索引に誘導しなければならない状況自体がレアケースで、本事象に遭遇することは少ないのかもしれない。ワークアラウンドはあるので、優先度は上がらないかもしれないが、今後の修正を期待したい。
以上
1.事象
今回発生したのは、SELECT文のプレディケート(WHERE句)に、ename LIKE '%ABC%' のようなあいまい検索をした場合で、ename列に張られたB-tree索引を使うときに、'%ABC%'がリテラルの場合は性能が良好なのに、これをバインド変数に置き換えると性能が悪化する、という事象である(実際の事象では、cursor_sharing=forceとして強制的にリテラルをバインド変数にしているが、本質的にはバインド変数を使う場合一般で発生する)。今回、この事象を私の手元の環境(Oracle 19.11)で再現することができたので、以下に再現手順とともに、具体的な問題と対処方法について考察したい。
2.再現ケース
まず事象を確認するため、以下のようにemp/dept表を作成し、データ(emp表に100万件、dept表に10万件)を挿入、統計を取得する。ここで、emp表のename列にidx_emp_ename索引を作成する。
create table dept(
deptno number(7,0),
dname varchar2(14),
loc varchar2(13),
constraint pk_dept primary key (deptno)
);
create table emp(
empno number(7,0),
ename varchar2(10),
job varchar2(9),
mgr number(7,0),
hiredate date,
sal number(7,2),
comm number(7,2),
deptno number(7,0),
constraint pk_emp primary key (empno),
constraint fk_deptno foreign key (deptno) references dept (deptno)
);
create index idx1_emp on emp(deptno);
create index idx_emp_ename on emp(ename);
insert into dept select
rownum deptno,
dbms_random.string('u',14) dname,
dbms_random.string('u',13) loc
from dual connect by level <=100000;
commit;
insert into emp select
rownum,
dbms_random.string('u',10) ename,
dbms_random.string('u',9) job,
dbms_random.value(1,1000000) mgr,
sysdate - dbms_random.value(1,5000) hiredate,
dbms_random.value(3000,9999) sal,
dbms_random.value(3000,9999) comm,
dbms_random.value(1,100000) deptno
from dual connect by level <=1000000;
commit;
exec dbms_stats.gather_table_stats('SCOTT','EMP');
exec dbms_stats.gather_table_stats('SCOTT','DEPT');
以下のようにバインドピークを有効にする(デフォルトは有効)。
alter session set "_optim_peek_user_binds"=true; SQL> sho parameter _optim_peek_user_binds NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ _optim_peek_user_binds boolean TRUE
以下のSQLはemp表、dept表を結合し、emp表のename列をLIKEで'%ABCD%'のようにあいまい検索する。結果10件、実行時間は0.20秒である。なお、ヒントを付与しているのは、恣意的にハッシュ結合を使い、ename列にIDX_EMP_ENAME索引を使うようにしている(これがないと、この例では索引は使われず、emp表を直接フルスキャンしてしまうため)。
◆リテラルの場合
SQL> select /*+ leading(t2 t1) use_hash(t1) index(t1 IDX_EMP_ENAME) */ * from emp t1, dept t2 where t1.deptno=t2.deptno and t1.ename like '%ABCD%';
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO DEPTNO DNAME LOC
---------- ---------- --------- ---------- --------- ---------- ---------- ---------- ---------- -------------- -------------
582720 AHIOABCDYT YXAQBMMYZ 874855 07-DEC-10 8436.11 5663.23 39434 39434 JSQOATEEMKCWZS RFPBWFMIAUUPN
448911 CZDLGBABCD VALZNFZDN 638948 07-NOV-13 7589.9 3307.46 69381 69381 ZJEAOYUCOEDUFF UOFSOHXHTSXVH
515098 DPOABCDIAB ATXDVQJXP 260849 13-JAN-10 4036.32 6729.36 3548 3548 JOTVEVFBTESCBZ UDODRZQVVMWQT
...
10 rows selected.
Elapsed: 00:00:00.20
同じSQLをバインド変数を用いて実行する。結果は同じだが、実行時間が1.74秒と、リテラルの場合に比べ8~9倍遅い。これはなぜか、この遅い理由を以下で解析する。
◆バインド変数の場合
SQL> variable b2 varchar2(10);
SQL> begin
2 :b2:='%ABCD%';
3 end;
4 /
PL/SQL procedure successfully completed.
SQL> select /*+ leading(t2 t1) use_hash(t1) index(t1 IDX_EMP_ENAME) */ * from emp t1, dept t2 where t1.deptno=t2.deptno and t1.ename like :b2;
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO DEPTNO DNAME LOC
---------- ---------- --------- ---------- --------- ---------- ---------- ---------- ---------- -------------- -------------
582720 AHIOABCDYT YXAQBMMYZ 874855 07-DEC-10 8436.11 5663.23 39434 39434 JSQOATEEMKCWZS RFPBWFMIAUUPN
448911 CZDLGBABCD VALZNFZDN 638948 07-NOV-13 7589.9 3307.46 69381 69381 ZJEAOYUCOEDUFF UOFSOHXHTSXVH
515098 DPOABCDIAB ATXDVQJXP 260849 13-JAN-10 4036.32 6729.36 3548 3548 JOTVEVFBTESCBZ UDODRZQVVMWQT
...
10 rows selected.
Elapsed: 00:00:01.74
3.解析
はじめに思いつくのは実行計画による違いである。dbms_xplanで実行計画を取得する(ヒントにgather_plan_statisticsを付与し、実行統計も取得する)と、いずれの結果も実行計画はほぼ同じであるが、よく見るとId4がINDEX FULL SCANに対し、遅い方はINDEX RANGE SCANとなっている。いずれの索引アクセス方法にしても、あいまい検索(%が先頭)では全てのリーフブロックをスキャン(シングルブロックリード)しなければならないため、本質的なIO量は変わらないはずである。ではこの性能差はどこから来ているのだろうか。
◆リテラルの場合
SQL_ID 0qygthva6jcgv, child number 3
-------------------------------------
select /*+ leading(t2 t1) use_hash(t1) index(t1 IDX_EMP_ENAME)
gather_plan_statistics */ * from emp t1, dept t2 where
t1.deptno=t2.deptno and t1.ename like '%ABCD%'
Plan hash value: 1197820828
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows |E-Bytes|E-Temp | Cost (%CPU)| E-Time | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | | | 54605 (100)| | 10 |00:00:00.02 | 4621 | | | |
|* 1 | HASH JOIN | | 1 | 50000 | 4296K| 4496K| 54605 (1)| 00:00:03 | 10 |00:00:00.02 | 4621 | 9465K| 3157K| 9991K (0)|
| 2 | TABLE ACCESS FULL | DEPT | 1 | 100K| 3320K| | 171 (1)| 00:00:01 | 100K|00:00:00.02 | 568 | | | |
| 3 | TABLE ACCESS BY INDEX ROWID BATCHED| EMP | 1 | 50000 | 2636K| | 54060 (1)| 00:00:03 | 10 |00:00:00.01 | 4053 | | | |
|* 4 | INDEX FULL SCAN | IDX_EMP_ENAME | 1 | 50000 | | | 4053 (1)| 00:00:01 | 10 |00:00:00.19 | 4043 | | | |
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
...
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("T1"."DEPTNO"="T2"."DEPTNO")
4 - filter(("T1"."ENAME" LIKE '%ABCD%' AND "T1"."ENAME" IS NOT NULL))
◆バインド変数の場合
SQL_ID 18640n98c4ncx, child number 3
-------------------------------------
select /*+ leading(t2 t1) use_hash(t1) index(t1 IDX_EMP_ENAME)
gather_plan_statistics */ * from emp t1, dept t2 where
t1.deptno=t2.deptno and t1.ename like :b2
Plan hash value: 300188277
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows |E-Bytes|E-Temp | Cost (%CPU)| E-Time | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | | | 50757 (100)| | 10 |00:00:00.04 | 1004K| | | |
|* 1 | HASH JOIN | | 1 | 50000 | 4296K| 4496K| 50757 (1)| 00:00:02 | 10 |00:00:00.04 | 1004K| 9465K| 3157K| 9976K (0)|
| 2 | TABLE ACCESS FULL | DEPT | 1 | 100K| 3320K| | 171 (1)| 00:00:01 | 100K|00:00:00.01 | 568 | | | |
|* 3 | TABLE ACCESS BY INDEX ROWID BATCHED| EMP | 1 | 50000 | 2636K| | 50211 (1)| 00:00:02 | 10 |00:00:00.02 | 1003K| | | |
|* 4 | INDEX RANGE SCAN | IDX_EMP_ENAME | 1 | 50000 | | | 204 (0)| 00:00:01 | 1000K|00:00:00.30 | 4043 | | | |
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
...
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("T1"."DEPTNO"="T2"."DEPTNO")
3 - filter("T1"."ENAME" LIKE :B2)
4 - access("T1"."ENAME" LIKE :B2)
ここで、上記結果のA-Rowsの値に注目したい。A-Rowsは実際の返却された行数を表す。INDEX FULL SCANのA-Rowsは1000K(100万件)であるのに対し、INDEX RANGE SCANのは10件である。つまり、INDEX FULL SCANはこの処理の中でLIKE '%ABCD%'で10件に絞り込みを行っているのに対し、INDEX RANGE SCANは全く絞り込みを行わず100万件を返却し、その結果、Id3のTABLE ACESS BY INDEX ROWIDでemp表にアクセスしLIKE '%ABCD%'の絞り込みを行い、10件の結果を得ていることがわかる。このことから、遅延の原因はこのId4のINDEX RANGE SCANにおいてLIKEの絞り込みができないことに起因していることがわかる。
4.原因
この事象は12.2で導入された、バインド変数におけるワイルドカードで開始されるLIKE検索をチェック機能(QKSFM_ACCESS_PATH_20289688)による影響であることが判明した。
SQL> select * from v$system_fix_control where description like '%LIKE%'
BUGNO VALUE SQL_FEATURE DESCRIPTION OPTIMIZER_ EVENT IS_DEFAULT CON_ID
...
20289688 1 QKSFM_ACCESS_PATH_20289688 check for leading wildcard in LIKE with bind 12.2.0.1 0 1 3
実際に、この_fix_controlを無効化して同じSQLを実行すると、あるべき性能が得られ、id4におけるINDEX RANGE SCANの中でLIKE '%ABCD%'の絞り込みが行われることがわかる。
SQL> select /*+ opt_param('_fix_control' '20289688:0') leading(t2 t1) use_hash(t1) index(t1 IDX_EMP_ENAME) gather_plan_statistics */ * from emp t1, dept t2 where t1.deptno=t2.deptno and t1.ename like :b2;
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO DEPTNO DNAME LOC
---------- ---------- --------- ---------- --------- ---------- ---------- ---------- ---------- -------------- -------------
582720 AHIOABCDYT YXAQBMMYZ 874855 07-DEC-10 8436.11 5663.23 39434 39434 JSQOATEEMKCWZS RFPBWFMIAUUPN
448911 CZDLGBABCD VALZNFZDN 638948 07-NOV-13 7589.9 3307.46 69381 69381 ZJEAOYUCOEDUFF UOFSOHXHTSXVH
515098 DPOABCDIAB ATXDVQJXP 260849 13-JAN-10 4036.32 6729.36 3548 3548 JOTVEVFBTESCBZ UDODRZQVVMWQT
...
10 rows selected.
Elapsed: 00:00:00.19
SQL_ID 25wd59chvjmwd, child number 0
-------------------------------------
select /*+ opt_param('_fix_control' '20289688:0') leading(t2 t1)
use_hash(t1) index(t1 IDX_EMP_ENAME) gather_plan_statistics */ * from
emp t1, dept t2 where t1.deptno=t2.deptno and t1.ename like :b2
Plan hash value: 300188277
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows |E-Bytes|E-Temp | Cost (%CPU)| E-Time | A-Rows | A-Time | Buffers | OMem | 1Mem | Used-Mem |
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | | | 50757 (100)| | 10 |00:00:00.02 | 4621 | | | |
|* 1 | HASH JOIN | | 1 | 50000 | 4296K| 4496K| 50757 (1)| 00:00:02 | 10 |00:00:00.02 | 4621 | 9465K| 3157K| 9988K (0)|
| 2 | TABLE ACCESS FULL | DEPT | 1 | 100K| 3320K| | 171 (1)| 00:00:01 | 100K|00:00:00.01 | 568 | | | |
| 3 | TABLE ACCESS BY INDEX ROWID BATCHED| EMP | 1 | 50000 | 2636K| | 50211 (1)| 00:00:02 | 10 |00:00:00.01 | 4053 | | | |
|* 4 | INDEX RANGE SCAN | IDX_EMP_ENAME | 1 | 50000 | | | 204 (0)| 00:00:01 | 10 |00:00:00.18 | 4043 | | | |
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
...
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("T1"."DEPTNO"="T2"."DEPTNO")
4 - access("T1"."ENAME" LIKE :B2)
filter("T1"."ENAME" LIKE :B2)
なお、この事象はバインドピークを無効化している場合("_optim_peek_user_binds"=false)は発生しない。これは、バインドピークの機能の中で、バインド値の先頭にワイルドカードが入っているかチェックしているためと思われる。したがって、本事象は12.2以上で、バインドピークを有効化しており、LIKE検索によるあいまい検索を行い、かつ検索にB-tree索引を利用している環境で発生し得る問題と考えられる。ハッシュ結合はこの事象の発生条件に関係ない。1つの表に対する検索でも発生し得る。
5.対処方法
考え得る対処方法は以下の通り。
- (1)セッション(またはシステム)レベルの_fix_controlで20289688を無効化する(例: ALTER SESSION SET "_fix_control"='20289688:0';)
- (2)セッション(またはシステム)レベルでバインドピークを無効化する(ALTER SESSION SET "_optim_peek_user_binds"=false;)
- (3)対象となるSQLに_fix_controlのヒントを入れる(例:/*+ opt_param('_fix_control' '20289688:0') */ )
- (4)対象となるSQLにバインドピークのヒントを入れる(例:/*+ opt_param('_optim_peek_user_binds' 'false') */ )
運用開始しており、バインドピークを有効化しているシステムにおいては、システムレベルで(1)(2)を変更することは難しいだろう。性能問題が発生するAPに限りセッションレベルで設定するようAPを改修するか、(3)(4)のヒントを入れるのが現実的だろう。なお、(3)(4)については、SPMやSQLパッチを使えば、APに手を入れずに実行計画を変更することも可能だろう。特にSQLがパッケージから発行されている場合は有効な対処方法となり得る。
4.おわりに
QKSFM_ACCESS_PATH_20289688が12.2で導入されてから今まで、なぜこの問題が放置されたままなのか不思議に感じる。この性能問題があったとしても、この機能を残すべき積極的な理由があったのかもしれない。もし、そうでないとすれば、バインドピークを使う場合は、_fix_controlで無効化しておく方が良いのではないか、とさえ思う。
なお、本事象をMOSCのスレッドで解析を進めている中、根本原因を指摘いただいたのはJonathan Lewis氏であった。自分だけでは、よもやオプティマイザの細かな改修の結果によりこの事象が発生しているとは思いもよらなかっただろう。Oracle CoreやCost based optimizerの著者である同氏と直接スレッドでやり取りできたことは、個人的にはこの上ない喜びであった。このようなことを可能としているOracleコミュニティ(MOSC)にも感謝したい。
2022/7/21 追記
Jonathan Lewis氏とのその後のやりとりで判明したことを備忘まで以下に追記しておく。v$system_fix_controlを確認すると、10.2.0.1において以下の修正が行われていることがわかる。
3628118 10.2.0.1 QKSFM_ACCESS_PATH_3628118 Do not consider LIKE with leading wildcard as index key
これは%で始まるLIKE検索の場合は、索引を使わないようにするための修正と思われる。そして、今回問題となっている20289688は、これをリテラルでなくバインド変数でも動作するようにキャッチアップしたものと思われる。あくまで想像の域を出ないが、考えられる経緯としては、バインド変数であいまい検索をした際にindex full/range scanになってしまい性能問題が出る事象があり、それについてSRが起票され、開発者がバインド変数でも同じ挙動をさせようと12.2でこの修正を入れたが、その修正の際、HINTで索引を強制的に使う場合の考慮が不足しており、今回のfilterが効かない挙動の違いが生まれてしまったのかもしれない。あくまでも推測ではあるが、なるほどありえそうなシナリオではあると感じる。
さらに、この事象に該当すると思われるバグを指摘頂いた。バグの説明文がまさに本事象と合致している。まだ修正されていないそうだ。
BUG 33500777 - FILTER FOR PREDICATE WITH LIKE AND BIND WITH LEADING WILDCARD IS NOT ALLOCATED ON INDEX SCAN AFTER FIX 20289688
あいまい検索においては一般的に索引を使わない実行計画が多く、絞り込みが効くとあらかじめわかっているケースは少ないだろう。その意味では今回のようにヒントで索引に誘導しなければならない状況自体がレアケースで、本事象に遭遇することは少ないのかもしれない。ワークアラウンドはあるので、優先度は上がらないかもしれないが、今後の修正を期待したい。
以上
ダイレクトパスリードとNSMTIOトレース [オプティマイザ]
この記事は、JPOUG Advent Calendar 2020 22日目の記事です。
21日目はyohei.azさんの記事『Tanel Poder の Linux Process Snapper』でした。
スマートスキャンをはじめとするExadataのオフロード機能を有効に使うためには、ダイレクトパスリードの発生条件を理解することが重要である(direct path readについて思うこと参照)。DPRの発生条件についての仕様は公開されておらず、また、Oracleのバージョンによって挙動が異なる。このため、有識者のブログ等でこういう条件ではこういう動きになったという断片的な情報は存在するものの、自分の目の前の環境でどういう動きになるのかを正確に知ることは難しい。
本稿では、ダイレクトパスリードの発生条件を確認する簡単な方法として、NSMTIOトレースを紹介する。私の手元の環境(OracleVM、19.3)で実際にトレースを取得して、挙動を確認した例を示す。あくまで例であり、環境が違えば異なる結果になる可能性があることはご留意頂きたい。
ダイレクトパスリードとは、フルスキャン(以後FTSと記す)の際に選択されるブロック読み取り方法であり、マルチブロックリードのようにバッファキャッシュを経由せず直接PGAへブロックを転送するため高速に処理を行うことができる。Exadataのスマートスキャンはダイレクトパスリードのコードの内部に実装されているため、スマートスキャン(正確にはExadataの各種オフロード機能)を使うにはダイレクトパスリードが前提となる。
ダイレクトパスリードにはパラレルとシリアルがある。パラレルダイレクトパスリードとは、parallelヒント等でパラレル化したフルテーブルスキャン(以下FTSと記す)するときに発生するダイレクトパスリードである。一方、シリアルダイレクトパスリードとは、パラレル化しない場合のFTSで発生するダイレクトパスリードである。
発生条件に関しては仕様が公開されておらず正確に把握することは難しい。FTS対象のオブジェクトサイズと以下のパラメータの大小関係、およびバッファキャッシュにオブジェクトがどれほど乗っているかが関係するといわれている。
STT(Small Table Threshold)・・・バッファキャッシュサイズの約2%
MTT(Middle Table Threshold)・・・バッファキャッシュサイズの約10%(STTの5倍)
VLOT(Very Large Object Threshold)・・・バッファキャッシュサイズの約500%(STTの250倍)
オブジェクトのサイズは、オブジェクト統計のBLOCKSが使われる。これは_direct_read_decision_statistics_drivenにより制御されており、falseにするとセグメントヘッダのブロックカウントを用いるようになる。11.2.0.2~からtrueになっている(参考文献[3])。
ダイレクトパスリードは実行計画を取得してもわからないため、SQLトレースを取得しダイレクトパスリードなのかマルチブロックリードなのかを確認するのが確実である。しかし、なぜダイレクトパスリードが選択されたのかはSQLトレースだけではわからない。それを確認できるのがNSMTIOトレースである。データベースでトレース可能なコンポーネントのうち、KXDと呼ばれるExadata特有カーネルモジュールをoradebugで確認するとNSMTIOトレースを確認できる(参考文献[2])。
NSMTIOトレースの取得方法は簡単である。以下のようにセッションレベルでSQLトレースを取得するように指定すればよい(より正確な指定方法は、参考文献[1]参照)。
以下にselect * from dualでNSMTIOトレースを取得した例を示す。
上記トレースのNSMTIOで始まる★部分から、テーブルアクセス関数(qertbFetch)がNoDirectRead、つまりダイレクトパスが選択されずマルチブロックリードが選択されたであろうことがわかる。また、その選択にあたり、オブジェクトサイズが1ブロック(Obect's size: 1)であること、MTTが5660ブロックであること、STTおよびMTTとの大小関係、オブジェクト統計が有効であること等が関連していることが伺える。実際、この場合は、オブジェクトサイズがSTT(kcbstt 1132)より小さいことから、マルチブロックリードが選択される。
なお、複数のSQLを実行すると、NSMTIOトレースがどのSQLに紐づくか識別が難しいことがあるので、以下のようにSQLトレースとあわせて設定する方法もある。場合によって使い分ければよい。
・バージョン
・インスタンス(バッファキャッシュ)
・初期化パラメータ(STT)
上記から、STTは1,132ブロック、MTTはその5倍の5,660ブロック、VLOTはバッファキャッシュの500%程度、より正確にはSTT250倍の283,000ブロックあたりと推測できる。
・テスト用テーブルの作成
レコード数は作成したいテーブルサイズにあわせて適宜変更する。以下の4パターンで検証する。なお、(4)については環境の制約でdbms_statsでNUM_ROWSとBLOCKSを設定して挙動を確認した。
(1)STT < OBJECT SIZE
バッファキャッシュをクリアしてからSQLを実行すると、バッファキャッシュ(ローカルまたはキャッシュフュージョン)から読むコスト、ストレージによる削減要素(OLTP/EHCC圧縮)を確認して、その結果ダイレクトパスリードを選択しているらしいということがわかる。また、選択のロジックとしては、kcbismでSTTとの大小関係をチェックはしているが(islarge 0)、qertbFetchではMTTとVLOTとの大小関係しか見ていないようである。
一方、FTSを実行してバッファキャッシュにブロックを乗せた状態では、バッファキャッシュから読み込む挙動が確認された。
(2)STT < OBJECT SIZE < MTT
→基本的に(1)と同じ挙動が確認できた。オブジェクトサイズがSTTを超えることにより、ダイレクトパスに倒れる挙動を期待したが、本検証では明確な違いを確認できなかった。
(3)MTT < OBJECT SIZE < VLOT
★部分のkcbismでSTTとの大小関係をチェックしislarge 1となっている。挙動としては(1)と同じであった。
(4)VLOT < OBJECT SIZE
★部分のkcbivloでVLOTよりオブジェクトサイズが大きいためis_large 1となり、次のqertbFetchでダイレクトパスリードが選択されていることがわかる。Additional InfoでVLOTが283040ブロックであることがわかる。
(1)STT < OBJECT SIZE
kcbismでSTTより小さいことがチェックされ、qertbFetchでダイレクトパスリードが選択されずマルチブロックリードとなっていることがわかる。
(2)STT < OBJECT SIZE < MTT
STTよりオブジェクトが大きい場合は、qertbFetchでバッファキャッシュから読むコスト等がチェックされ、その結果、kcbdpcでDirectReadが選択されている。
バッファキャッシュにオブジェクトが乗っている状態では、kcbcmt1で何らかのバッファキャッシュ上のオブジェクトのブロック数が評価され、qertbFetchでNoDirectReadが選択されている様子がわかる。
(3)MTT < OBJECT SIZE < VLOT
MTTより大きい場合はkcbimdのチェックが追加されており、ここでMTTとの大小関係がチェックされている。kcbnbhがMTTなのだろう。ただし挙動は(2)同様である。
(4)VLOT < OBJECT SIZE
★部分のkcbivloでVLOTよりオブジェクトサイズが大きいためis_large 1となり、次のqertbFetchでダイレクトパスリードが選択されていることがわかる。VLOTの判定後のトレースの出方がシリアルの場合と同じなので、VLOTの場合はシリアルもパラレルも同じコードパスなのだろう。
_serial_direct_read(デフォルトauto)はシリアルダイレクトパスリードにおけるダイレクトパスの選択を制御することができる隠しパラメータである(セッションレベルで変更可能)。これをnever(ダイレクトパスリードを発生させない)、always(ダイレクトパスリードを発生させる)にそれぞれ指定した場合の挙動の違いをNSMTIOトレースで確認する。
(3)MTT < OBJECT SIZE < VLOT
"_serial_direct_read"=neverの場合、★部分でシリアルダイレクトパスリードが無効化され、マルチブロックリードが選択される挙動になっていることがわかる。
"_serial_direct_read"=alwaysの場合、★部分でシリアルダイレクトパスリードが有効化され、ダイレクトパスリードが選択される挙動になっていることがわかる。
今回はダイレクトパスリードの発生条件を確認するために、NSMTIOトレースの取得方法と、パラレル・シリアルダイレクトパスリードの検証結果を紹介した。
検証の結果、パラレルダイレクトパスについては、概ね常にダイレクトパスリードが発生する状態になることがわかった。バッファキャッシュに100%乗っている場合に、まれにバッファキャッシュから読み込まれる挙動も確認できた。一方、シリアルダイレクトパスについては、STT以下ではマルチブロックリード、MTT以上ではダイレクトパスリードになることがわかった。STT~VLOTまではダイレクトパスリードの場合と、マルチブロックリードの場合があることが確認された。バッファキャッシュ上の状態が関係していることは確かであるが、正確な挙動を確認までは至っていない。いずれのケースもVLOTより大きい場合はダイレクトパスリードになることが確認できた。課題は以下のqertbFetchのロジックの解明である。この中にバッファキャッシュの状態含めたコスト計算が含まれているはずで、この中のロジックをトレースすることができれば、より詳細にダイレクトパスリードの発生条件を明らかにすることができると考える。
qertbFetch:[MTT < OBJECT_SIZE < VLOT]: Checking cost to read from caches(local/remote) and checking storage reduction factors (OLTP/EHCC Comp)
備忘まで、今回検証で確認できたダイレクトパスリードとSTT、MTT、VLOTの関係とNSMTIOトレースの特徴的な出力を下図に示す。繰り返しになるが、これで正しい挙動をとらえているとは思っていない。不完全ながら公開する意図は、トレースを取ればここまではわかるということを伝えることで、アップグレード時の挙動の変化を確認したり、オブジェクトサイズの境界値を監視することで性能問題を未然に防いだり、不幸にも性能トラブルに巻き込まれた際に迅速な解析が可能となると考える。DBAの生活の質の向上の一助になれば幸いである。
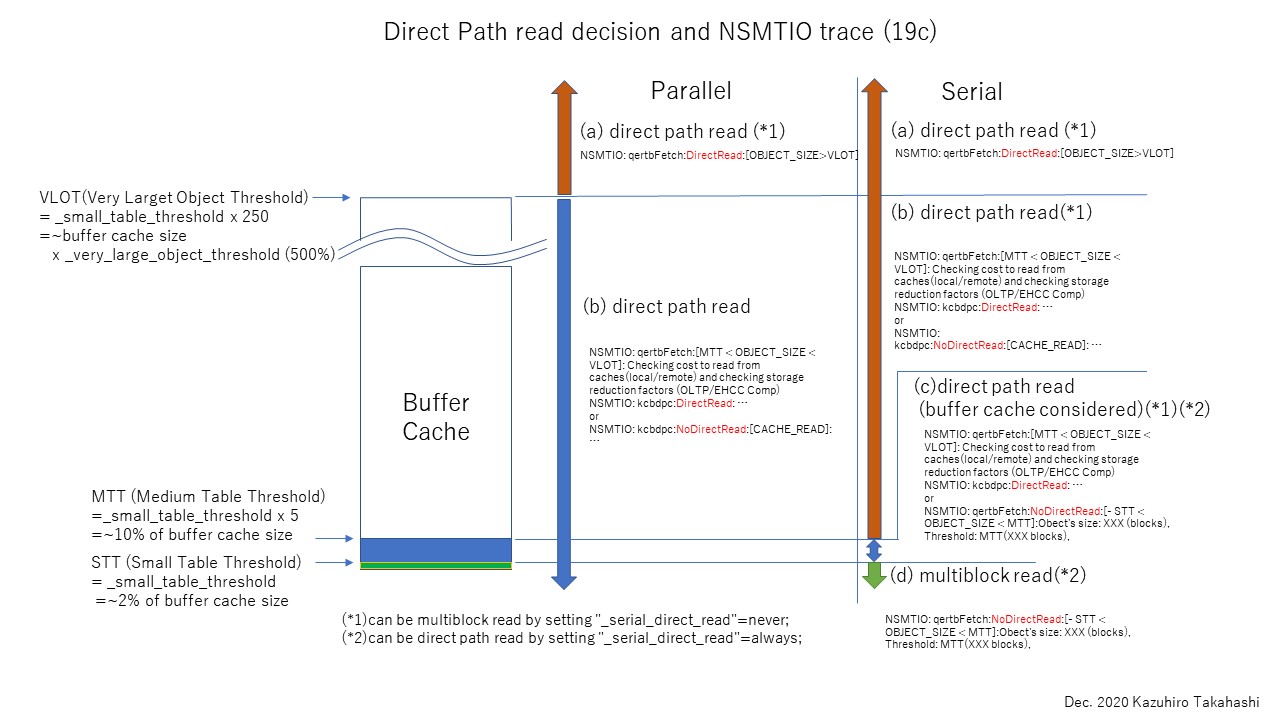
以上
[1]When bloggers get it wrong - part 2, Roger Macnicol
[2]Expert Oracle Exadata, Martin Bach他, pp.50-53
[3]Optimizer statistics-driven direct path read decision for full table scans, Tanel Poder
21日目はyohei.azさんの記事『Tanel Poder の Linux Process Snapper』でした。
1.はじめに
スマートスキャンをはじめとするExadataのオフロード機能を有効に使うためには、ダイレクトパスリードの発生条件を理解することが重要である(direct path readについて思うこと参照)。DPRの発生条件についての仕様は公開されておらず、また、Oracleのバージョンによって挙動が異なる。このため、有識者のブログ等でこういう条件ではこういう動きになったという断片的な情報は存在するものの、自分の目の前の環境でどういう動きになるのかを正確に知ることは難しい。
本稿では、ダイレクトパスリードの発生条件を確認する簡単な方法として、NSMTIOトレースを紹介する。私の手元の環境(OracleVM、19.3)で実際にトレースを取得して、挙動を確認した例を示す。あくまで例であり、環境が違えば異なる結果になる可能性があることはご留意頂きたい。
2.基本的な理解
ダイレクトパスリードとは、フルスキャン(以後FTSと記す)の際に選択されるブロック読み取り方法であり、マルチブロックリードのようにバッファキャッシュを経由せず直接PGAへブロックを転送するため高速に処理を行うことができる。Exadataのスマートスキャンはダイレクトパスリードのコードの内部に実装されているため、スマートスキャン(正確にはExadataの各種オフロード機能)を使うにはダイレクトパスリードが前提となる。
ダイレクトパスリードにはパラレルとシリアルがある。パラレルダイレクトパスリードとは、parallelヒント等でパラレル化したフルテーブルスキャン(以下FTSと記す)するときに発生するダイレクトパスリードである。一方、シリアルダイレクトパスリードとは、パラレル化しない場合のFTSで発生するダイレクトパスリードである。
発生条件に関しては仕様が公開されておらず正確に把握することは難しい。FTS対象のオブジェクトサイズと以下のパラメータの大小関係、およびバッファキャッシュにオブジェクトがどれほど乗っているかが関係するといわれている。
STT(Small Table Threshold)・・・バッファキャッシュサイズの約2%
MTT(Middle Table Threshold)・・・バッファキャッシュサイズの約10%(STTの5倍)
VLOT(Very Large Object Threshold)・・・バッファキャッシュサイズの約500%(STTの250倍)
オブジェクトのサイズは、オブジェクト統計のBLOCKSが使われる。これは_direct_read_decision_statistics_drivenにより制御されており、falseにするとセグメントヘッダのブロックカウントを用いるようになる。11.2.0.2~からtrueになっている(参考文献[3])。
3.NSMTIOトレースについて
ダイレクトパスリードは実行計画を取得してもわからないため、SQLトレースを取得しダイレクトパスリードなのかマルチブロックリードなのかを確認するのが確実である。しかし、なぜダイレクトパスリードが選択されたのかはSQLトレースだけではわからない。それを確認できるのがNSMTIOトレースである。データベースでトレース可能なコンポーネントのうち、KXDと呼ばれるExadata特有カーネルモジュールをoradebugで確認するとNSMTIOトレースを確認できる(参考文献[2])。
SQL> oradebug doc component kxd KXD Exadata specific Kernel modules (kxd) KXDAM Exadata Disk Auto Manage (kxdam) KCFIS Exadata Predicate Push (kcfis) NSMTIO Trace Non Smart I/O (nsmtio) ★ KXDBIO Exadata Block level Intelligent Operations (kxdbio) KXDRS Exadata Resilvering Layer (kxdrs) KXDOFL Exadata Offload (kxdofl) KXDMISC Exadata Misc (kxdmisc) KXDCM Exadata Metrics Fixed Table Callbacks (kxdcm) KXDBC Exadata Backup Compression for Backup Appliance (kxdbc)
NSMTIOトレースの取得方法は簡単である。以下のようにセッションレベルでSQLトレースを取得するように指定すればよい(より正確な指定方法は、参考文献[1]参照)。
alter session set events 'trace[nsmtio]'; <任意のSQL文> alter session set events 'trace[nsmtio] off';
以下にselect * from dualでNSMTIOトレースを取得した例を示す。
SQL> alter session set tracefile_identifier='nsmtio'; Session altered. SQL> select value from v$diag_info where name like 'Default%'; VALUE -------------------------------------------------------------------------------- /u01/app/oracle/diag/rdbms/orclcdb/orclcdb/trace/orclcdb_ora_17198_nsmtio.trc SQL> alter session set events 'trace[nsmtio]'; Session altered. SQL> select * from dual; D - X SQL> alter session set events 'trace[nsmtio] off'; Session altered. SQL> !cat /u01/app/oracle/diag/rdbms/orclcdb/orclcdb/trace/orclcdb_ora_17198_nsmtio.trc NSMTIO: kcbism: islarge 0 next 0 nblks 1 type 2, bpid 3, kcbisdbfc 0 kcbnhl 1024 kcbstt 1132 keep_nb 0 kcbnbh 56608 kcbnwp 1 ★NSMTIO: qertbFetch:NoDirectRead:[- STT < OBJECT_SIZE < MTT]:Obect's size: 1 (blocks), Threshold: MTT(5660 blocks), _object_statistics: enabled, Sage: enabled, Direct Read for serial qry: enabled(:::::::auto DR::), Ascending SCN table scan: FALSE flashback_table_scan: FALSE, Row Versions Query: FALSE SqlId: a5ks9fhw2v9s1, plan_hash_value: 272002086, Object#: 143, Parition#: 0 DW_scan: disabled NSMTIO: fple: FALSE, sage: TRUE, isTableSpaceOnSage: 0, invalid table sapce number: FALSE, prmsdec: TRUE, is kernel txn table space encrypted: -1,is enc_ktid encrypted: -1, is sage enabled based on data -layer checks: -1, isQesSageEnabled: FALSE
上記トレースのNSMTIOで始まる★部分から、テーブルアクセス関数(qertbFetch)がNoDirectRead、つまりダイレクトパスが選択されずマルチブロックリードが選択されたであろうことがわかる。また、その選択にあたり、オブジェクトサイズが1ブロック(Obect's size: 1)であること、MTTが5660ブロックであること、STTおよびMTTとの大小関係、オブジェクト統計が有効であること等が関連していることが伺える。実際、この場合は、オブジェクトサイズがSTT(kcbstt 1132)より小さいことから、マルチブロックリードが選択される。
なお、複数のSQLを実行すると、NSMTIOトレースがどのSQLに紐づくか識別が難しいことがあるので、以下のようにSQLトレースとあわせて設定する方法もある。場合によって使い分ければよい。
alter session set events 'trace[nsmtio]:sql_trace level 8'; <任意のSQL文> alter session set events 'trace[nsmtio]:sql_trace off';
4.検証
4-1.検証環境と検証内容
・バージョン
SQL> select BANNER_FULL from v$version; BANNER_FULL -------------------------------------------------------------------------------- Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Version 19.3.0.0.0
・インスタンス(バッファキャッシュ)
SQL> select * from v$sgainfo NAME BYTES RES CON_ID -------------------------------- ---------- --- ---------- Fixed SGA Size 9140336 No 0 Redo Buffers 3440640 No 0 Buffer Cache Size 524288000 Yes 0★ In-Memory Area Size 0 No 0 Shared Pool Size 297795584 Yes 0 Large Pool Size 4194304 Yes 0 Java Pool Size 0 Yes 0 Streams Pool Size 0 Yes 0 Shared IO Pool Size 37748736 Yes 0 Data Transfer Cache Size 0 Yes 0 Granule Size 4194304 No 0 Maximum SGA Size 838858864 No 0 Startup overhead in Shared Pool 198150216 No 0 Free SGA Memory Available 0 0
・初期化パラメータ(STT)
SQL> SELECT a.ksppinm "Parameter", b.KSPPSTDF "Default Value", 2 b.ksppstvl "Session Value", 3 c.ksppstvl "Instance Value" 4 FROM x$ksppi a, 5 x$ksppcv b, 6 x$ksppsv c 7 WHERE a.indx = b.indx 8 AND a.indx = c.indx 9 AND a.ksppinm in ('_small_table_threshold', '_very_large_object_threshold') 10 / Parameter Default Value Session Value Instance Value ----------------------------------- --------------- --------------- --------------- _small_table_threshold TRUE 1132 1132 _very_large_object_threshold TRUE 500 500
上記から、STTは1,132ブロック、MTTはその5倍の5,660ブロック、VLOTはバッファキャッシュの500%程度、より正確にはSTT250倍の283,000ブロックあたりと推測できる。
・テスト用テーブルの作成
drop table scott.t1 cascade constraints; create table scott.t1 (id, val, padding1 , padding2 , padding3 , padding4 , padding5 ) as select rownum id, trunc(100 * dbms_random.normal) val, rpad('x',100) padding1, rpad('x',100) padding2, rpad('x',100) padding3, rpad('x',100) padding4, rpad('x',100) padding5 from dual connect by level <= 10000; exec dbms_stats.gather_table_stats('SCOTT','T1'); col segment_name for a20 select segment_name, bytes/1024/1024 mb from user_segments where segment_name='T1'; select num_rows, blocks from dba_tables where owner='SCOTT' and table_name='T1';
4-2.検証項目
レコード数は作成したいテーブルサイズにあわせて適宜変更する。以下の4パターンで検証する。なお、(4)については環境の制約でdbms_statsでNUM_ROWSとBLOCKSを設定して挙動を確認した。
NUM_ROWS BLOCKS
---------- ----------
(1) 10000 791 ・・・STT < OBJECT SIZE
(2) 20000 1573 ・・・STT < OBJECT SIZE < MTT
(3) 80000 6260 ・・・MTT < OBJECT SIZE < VLOT
(4) 1000000 300000 ・・・VLOT < OBJECT SIZE *
*)
BEGIN
DBMS_STATS.SET_TABLE_STATS(
ownname => 'SCOTT'
, tabname => 'T1'
, numrows => 1000000
, numblks => 300000 );
END;
/
5.検証結果
5-1.パラレルダイレクトパスリード
(1)STT < OBJECT SIZE
バッファキャッシュをクリアしてからSQLを実行すると、バッファキャッシュ(ローカルまたはキャッシュフュージョン)から読むコスト、ストレージによる削減要素(OLTP/EHCC圧縮)を確認して、その結果ダイレクトパスリードを選択しているらしいということがわかる。また、選択のロジックとしては、kcbismでSTTとの大小関係をチェックはしているが(islarge 0)、qertbFetchではMTTとVLOTとの大小関係しか見ていないようである。
NSMTIO: kcbism: islarge 0 next 0 nblks 791 type 3, bpid 65535, kcbisdbfc 0 kcbnhl 1024 kcbstt 1132 keep_nb 0 kcbnbh 56608 kcbnwp 1 NSMTIO: NSMTIO:kkfdtsc:DirectRead: NSMTIO: kcbzib: Cache Scan triggered for tsn = 5, rdba=0x030105ba, fn = 12, kobjd = 81289, block cnt = 0, nonconUE pre-warm = FALSE, prefetch = FALSE NSMTIO: kcbism: islarge 0 next 0 nblks 769 type 2, bpid 65535, kcbisdbfc 0 kcbnhl 1024 kcbstt 1132 keep_nb 0 kcb8 kcbnwp 1 NSMTIO: kxfrCancelDR: objn:0x13d89 flg:0x4201 size:769 table:small cache:56608 affpct:80 NSMTIO: kcbivlo: nblks 791 vlot 500 pnb 56608 kcbisdbfc 0 is_large 0 NSMTIO: qertbFetch:[MTT < OBJECT_SIZE < VLOT]: Checking cost to read from caches(local/remote) and checking storage reduction factors (OLTP/EHCC Comp)★ NSMTIO: kcbdpc:DirectRead: tsn: 5, objd: 81289, objn: 81289★
一方、FTSを実行してバッファキャッシュにブロックを乗せた状態では、バッファキャッシュから読み込む挙動が確認された。
NSMTIO: kcbdpc:NoDirectRead:[CACHE_READ]: tsn: 5, objd: 81292, objn: 81292
(2)STT < OBJECT SIZE < MTT
→基本的に(1)と同じ挙動が確認できた。オブジェクトサイズがSTTを超えることにより、ダイレクトパスに倒れる挙動を期待したが、本検証では明確な違いを確認できなかった。
(3)MTT < OBJECT SIZE < VLOT
★部分のkcbismでSTTとの大小関係をチェックしislarge 1となっている。挙動としては(1)と同じであった。
NSMTIO: kcbism: islarge 0 next 0 nblks 12 type 3, bpid 65535, kcbisdbfc 0 kcbnhl 1024 kcbstt 1132 keep_nb 0 kcbn kcbnwp 1 NSMTIO: kcbism: islarge 1 next 0 nblks 6260 type 3, bpid 65535, kcbisdbfc 0 kcbnhl 1024 kcbstt 1132 keep_nb 0 kc08 kcbnwp 1★ NSMTIO: NSMTIO:kkfdtsc:DirectRead: NSMTIO: kcbzib: Cache Scan triggered for tsn = 5, rdba=0x0302aeba, fn = 12, kobjd = 81291, block cnt = 0, nonconUE pre-warm = FALSE, prefetch = FALSE NSMTIO: kcbism: islarge 1 next 0 nblks 6154 type 2, bpid 65535, kcbisdbfc 0 kcbnhl 1024 kcbstt 1132 keep_nb 0 kc08 kcbnwp 1 NSMTIO: kxfrCancelDR: objn:0x13d8b flg:0x4601 size:6154 table:large cache:56608 affpct:80 NSMTIO: kcbivlo: nblks 6260 vlot 500 pnb 56608 kcbisdbfc 0 is_large 0 NSMTIO: qertbFetch:[MTT < OBJECT_SIZE < VLOT]: Checking cost to read from caches(local/remote) and checking storage reduction factors (OLTP/EHCC Comp) NSMTIO: kcbdpc:DirectRead: tsn: 5, objd: 81291, objn: 81291
(4)VLOT < OBJECT SIZE
★部分のkcbivloでVLOTよりオブジェクトサイズが大きいためis_large 1となり、次のqertbFetchでダイレクトパスリードが選択されていることがわかる。Additional InfoでVLOTが283040ブロックであることがわかる。
NSMTIO: kcbism: islarge 1 next 0 nblks 300000 type 3, bpid 65535, kcbisdbfc 0 kcbnhl 1024 kcbstt 1132 keep_nb 0 kcbnbh 56608 kcbnwp 1 NSMTIO: NSMTIO:kkfdtsc:DirectRead: Additional Information: Cache_Attribute_Set:No, SCN_Ascending_Scan: No, Event_10354_Set: No, SqlID: dg16qmpsbha21, Id: 0 NSMTIO: kcbism: islarge 1 next 0 nblks 6154 type 2, bpid 65535, kcbisdbfc 0 kcbnhl 1024 kcbstt 1132 keep_nb 0 kcbnbh 56608 kcbnwp 1 NSMTIO: kxfrCancelDR: objn:0x13dc5 flg:0x4601 size:6154 table:large cache:56608 affpct:80 #insts:1 clu-cached:no arch:-1 direct-read:yes SmartIO:yes affinitized:no dw_scan:no very_large_thr:500 NSMTIO: kcbivlo: nblks 300000 vlot 500 pnb 56608 kcbisdbfc 0 is_large 1★ NSMTIO: qertbFetch:DirectRead:[OBJECT_SIZE>VLOT]★ NSMTIO: Additional Info: VLOT=283040★
5-2.シリアルダイレクトパスリード
(1)STT < OBJECT SIZE
kcbismでSTTより小さいことがチェックされ、qertbFetchでダイレクトパスリードが選択されずマルチブロックリードとなっていることがわかる。
NSMTIO: kcbism: islarge 0 next 0 nblks 791 type 3, bpid 65535, kcbisdbfc 0 kcbnhl 1024 kcbstt 1161 keep_nb 0 kcb2 kcbnwp 1 NSMTIO: kcbism: islarge 0 next 0 nblks 791 type 2, bpid 3, kcbisdbfc 0 kcbnhl 1024 kcbstt 1161 keep_nb 0 kcbnbh bnwp 1 NSMTIO: qertbFetch:NoDirectRead:[- STT < OBJECT_SIZE < MTT]:Obect's size: 791 (blocks), Threshold: MTT(5807 blocks),★
(2)STT < OBJECT SIZE < MTT
STTよりオブジェクトが大きい場合は、qertbFetchでバッファキャッシュから読むコスト等がチェックされ、その結果、kcbdpcでDirectReadが選択されている。
NSMTIO: kcbism: islarge 1 next 0 nblks 1573 type 3, bpid 65535, kcbisdbfc 0 kcbnhl 1024 kcbstt 1161 keep_nb 0 kcbnbh 58072 kcbnwp 1 NSMTIO: kcbism: islarge 1 next 0 nblks 1573 type 2, bpid 3, kcbisdbfc 0 kcbnhl 1024 kcbstt 1161 keep_nb 0 kcbnbh 58072 kcbnwp 1 NSMTIO: kcbimd: nblks 1573 kcbstt 1161 kcbnbh 5807 kcbisdbfc 3 is_medium 0 NSMTIO: kcbcmt1: scann age_diff adjts last_ts nbuf nblk has_val kcbisdbfc 0 15374 0 58072 1573 0 0 NSMTIO: kcbivlo: nblks 1573 vlot 500 pnb 58072 kcbisdbfc 0 is_large 0 NSMTIO: qertbFetch:[MTT < OBJECT_SIZE < VLOT]: Checking cost to read from caches(local/remote) and checking storage reduction factors (OLTP/EHCC Comp)★ NSMTIO: kcbdpc:DirectRead: tsn: 5, objd: 81221, objn: 81221★
バッファキャッシュにオブジェクトが乗っている状態では、kcbcmt1で何らかのバッファキャッシュ上のオブジェクトのブロック数が評価され、qertbFetchでNoDirectReadが選択されている様子がわかる。
NSMTIO: kcbism: islarge 1 next 0 nblks 1572 type 3, bpid 65535, kcbisdbfc 0 kcbnhl 1024 kcbstt 1161 keep_nb 0 kcbnbh 58072 kcbnwp 1 NSMTIO: kcbism: islarge 1 next 0 nblks 1572 type 2, bpid 3, kcbisdbfc 0 kcbnhl 1024 kcbstt 1161 keep_nb 0 kcbnbh 58072 kcbnwp 1 NSMTIO: kcbimd: nblks 1572 kcbstt 1161 kcbnbh 5807 kcbisdbfc 3 is_medium 0 NSMTIO: kcbcmt1: hit age_diff adjts last_ts nbuf nblk has_val kcbisdbfc cache_it 1538 43216 41678 58072 1572 1 0 1★ NSMTIO: qertbFetch:NoDirectRead:[- STT < OBJECT_SIZE < MTT]:Obect's size: 1572 (blocks), Threshold: MTT(5807 blocks),★
(3)MTT < OBJECT SIZE < VLOT
MTTより大きい場合はkcbimdのチェックが追加されており、ここでMTTとの大小関係がチェックされている。kcbnbhがMTTなのだろう。ただし挙動は(2)同様である。
NSMTIO: kcbism: islarge 1 next 0 nblks 6260 type 3, bpid 65535, kcbisdbfc 0 kcbnhl 1024 kcbstt 1161 keep_nb 0 kcbnbh 58072 kcbnwp 1 NSMTIO: kcbism: islarge 1 next 0 nblks 6260 type 2, bpid 3, kcbisdbfc 0 kcbnhl 1024 kcbstt 1161 keep_nb 0 kcbnbh 58072 kcbnwp 1 NSMTIO: kcbimd: nblks 6260 kcbstt 1161 kcbnbh 5807 kcbisdbfc 3 is_medium 0★ NSMTIO: kcbivlo: nblks 6260 vlot 500 pnb 58072 kcbisdbfc 0 is_large 0 NSMTIO: qertbFetch:[MTT < OBJECT_SIZE < VLOT]: Checking cost to read from caches(local/remote) and checking storage reduction factors (OLTP/EHCC Comp) NSMTIO: kcbdpc:DirectRead: tsn: 5, objd: 81239, objn: 81239 kcbdpc: kx 8 kc 8 lhs 4 rhs NSMTIO: Additional Info: VLOT=290360
(4)VLOT < OBJECT SIZE
★部分のkcbivloでVLOTよりオブジェクトサイズが大きいためis_large 1となり、次のqertbFetchでダイレクトパスリードが選択されていることがわかる。VLOTの判定後のトレースの出方がシリアルの場合と同じなので、VLOTの場合はシリアルもパラレルも同じコードパスなのだろう。
NSMTIO: kcbism: islarge 1 next 0 nblks 300000 type 3, bpid 65535, kcbisdbfc 0 kcbnhl 1024 kcbstt 1132 keep_nb 0 kcbnbh 56608 kcbnwp 1 NSMTIO: kcbism: islarge 1 next 0 nblks 300000 type 2, bpid 3, kcbisdbfc 0 kcbnhl 1024 kcbstt 1132 keep_nb 0 kcbnbh 56608 kcbnwp 1 NSMTIO: kcbimd: nblks 300000 kcbstt 1132 kcbnbh 5660 kcbisdbfc 3 is_medium 0 NSMTIO: kcbivlo: nblks 300000 vlot 500 pnb 56608 kcbisdbfc 0 is_large 1★ NSMTIO: qertbFetch:DirectRead:[OBJECT_SIZE>VLOT]★ NSMTIO: Additional Info: VLOT=283040
5-3.隠しパラメータによる制御の影響
_serial_direct_read(デフォルトauto)はシリアルダイレクトパスリードにおけるダイレクトパスの選択を制御することができる隠しパラメータである(セッションレベルで変更可能)。これをnever(ダイレクトパスリードを発生させない)、always(ダイレクトパスリードを発生させる)にそれぞれ指定した場合の挙動の違いをNSMTIOトレースで確認する。
(3)MTT < OBJECT SIZE < VLOT
"_serial_direct_read"=neverの場合、★部分でシリアルダイレクトパスリードが無効化され、マルチブロックリードが選択される挙動になっていることがわかる。
NSMTIO: kcbism: islarge 1 next 0 nblks 6260 type 3, bpid 65535, kcbisdbfc 0 kcbnhl 1024 kcbstt 1132 keep_nb 0 kcbnbh 56608 kcbnwp 1 NSMTIO: kcbism: islarge 1 next 0 nblks 6260 type 2, bpid 3, kcbisdbfc 0 kcbnhl 1024 kcbstt 1132 keep_nb 0 kcbnbh 56608 kcbnwp 1 NSMTIO: kcbimd: nblks 6260 kcbstt 1132 kcbnbh 5660 kcbisdbfc 3 is_medium 0 NSMTIO: qertbFetch:NoDirectRead:[_SERIAL_DIRECT_READ Disabled]:★ NSMTIO: Additional Info: VLOT=283040
"_serial_direct_read"=alwaysの場合、★部分でシリアルダイレクトパスリードが有効化され、ダイレクトパスリードが選択される挙動になっていることがわかる。
NSMTIO: kcbism: islarge 1 next 0 nblks 6260 type 3, bpid 65535, kcbisdbfc 0 kcbnhl 1024 kcbstt 1132 keep_nb 0 kcbnbh 56608 kcbnwp 1 NSMTIO: kcbism: islarge 1 next 0 nblks 6260 type 2, bpid 3, kcbisdbfc 0 kcbnhl 1024 kcbstt 1132 keep_nb 0 kcbnbh 56608 kcbnwp 1 NSMTIO: kcbimd: nblks 6260 kcbstt 1132 kcbnbh 5660 kcbisdbfc 3 is_medium 0 NSMTIO: qertbFetch:DirectRead:[_SERIAL_DIRECT_READ Always]: Additional Info: Object# = 81277, Object_Size = 6260 blocks★ NSMTIO: fple: FALSE, sage: TRUE, isTableSpaceOnSage: 0, invalid table sapce number: FALSE, prmsdec: TRUE, is kernel txn table space encrypted: -1,is enc_ktid encrypted: -1, is sage enabled based on data -layer checks: -1, isQesSageEnabled: FALSE
6.まとめ
今回はダイレクトパスリードの発生条件を確認するために、NSMTIOトレースの取得方法と、パラレル・シリアルダイレクトパスリードの検証結果を紹介した。
検証の結果、パラレルダイレクトパスについては、概ね常にダイレクトパスリードが発生する状態になることがわかった。バッファキャッシュに100%乗っている場合に、まれにバッファキャッシュから読み込まれる挙動も確認できた。一方、シリアルダイレクトパスについては、STT以下ではマルチブロックリード、MTT以上ではダイレクトパスリードになることがわかった。STT~VLOTまではダイレクトパスリードの場合と、マルチブロックリードの場合があることが確認された。バッファキャッシュ上の状態が関係していることは確かであるが、正確な挙動を確認までは至っていない。いずれのケースもVLOTより大きい場合はダイレクトパスリードになることが確認できた。課題は以下のqertbFetchのロジックの解明である。この中にバッファキャッシュの状態含めたコスト計算が含まれているはずで、この中のロジックをトレースすることができれば、より詳細にダイレクトパスリードの発生条件を明らかにすることができると考える。
qertbFetch:[MTT < OBJECT_SIZE < VLOT]: Checking cost to read from caches(local/remote) and checking storage reduction factors (OLTP/EHCC Comp)
備忘まで、今回検証で確認できたダイレクトパスリードとSTT、MTT、VLOTの関係とNSMTIOトレースの特徴的な出力を下図に示す。繰り返しになるが、これで正しい挙動をとらえているとは思っていない。不完全ながら公開する意図は、トレースを取ればここまではわかるということを伝えることで、アップグレード時の挙動の変化を確認したり、オブジェクトサイズの境界値を監視することで性能問題を未然に防いだり、不幸にも性能トラブルに巻き込まれた際に迅速な解析が可能となると考える。DBAの生活の質の向上の一助になれば幸いである。
以上
◆参考文献:
[1]When bloggers get it wrong - part 2, Roger Macnicol
[2]Expert Oracle Exadata, Martin Bach他, pp.50-53
[3]Optimizer statistics-driven direct path read decision for full table scans, Tanel Poder
2020-12-22 00:00
バインドミスマッチの罪 [オプティマイザ]
最近の現場でcursor: mutex X待機によるSQL遅延の問題に遭遇した。cursor: mutex XはSQLのハードパース時に排他ロックを獲得する際に待ちが発生したことを示す。通常、同じSQLは1度ハードパースされれば2回目からはそれが再利用されるため、ハードパースが多発することはない。しかし、今回のケースでは、バインドミスマッチにより、同じSQLでもカーソルの共有がされず、大量のハードパースが発生していることがわかった。今回はこのバインドミスマッチが如何に罪深いのかについて考えてみたい。
なお、先に結論を書いておくと、今回の教訓としては、JavaでOracleを使う場合は以下2点に注意、ということである。
・DATE型カラムに対してTIMESTAMP型でなくDATE型でバインドすること
・NULL値の場合にカラムの型でバインドすること(setNullにjava.sql.Types.NULLを渡してはいけない)
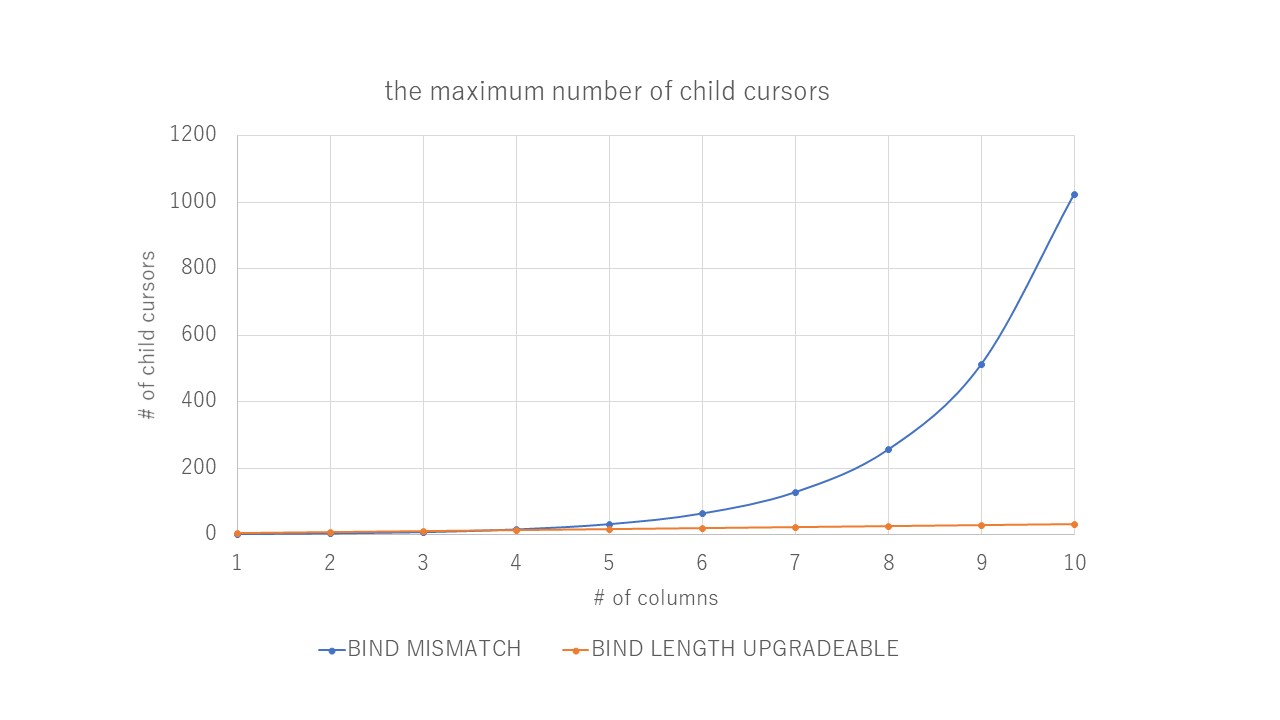
そして、それを怠った場合の代償として、バインドミスマッチが発生するカラム数に応じて、2のべき乗で子カーソルが爆発的に増加する事象が発生する。
◇バインドミスマッチによる子カーソル増加の問題
バインドミスマッチとは、バインド変数を利用しているSQL、DMLにおいて、バインド変数の型の不一致で共有プール上のカーソルが共有されない事象を指す。例えば、あるテーブルにDATE型カラムがあり、これを更新するUPDATE文があったとしよう。バインド変数を使っていれば、UPDATE文にどのような値が入ってもSQLIDは同じであり、カーソルは共有されることを期待する。しかし、ここで、DATE型に対し、DATE型でバインドするのと、TIMESTAMP型でバインドするのでは、SQLIDは同じでもOracle内部では異なるカーソル(厳密には1つの親カーソルに対し、2つの子カーソル)として管理される。これがバインドミスマッチである。
実際にバインドミスマッチの発生している状況を見てみよう。EMP表にはc3,c4のDATE型カラムがある。update文でc3,c4それぞれにDATE型とTIMESTAMP型の2つのパターンでバインドし、4通りの組み合わせで実行する。結果、このSQLの子カーソル数(VERSION_COUNT)が4になる。つまり、バインド変数を使い同じSQLを実行しているにも関わらず、カーソルが共有されず、それぞれハードパースされているのだ。本来バインドミスマッチが発生しなければ、VERSION_COUNTは1になるはずである。なお、手元の環境はOracle19.3である。
子カーソルが4個になることくらいは大した問題でないと思うかもしれない。しかし、これが様々なカラムで発生すると、1カラムで2通りの組み合わせ(=カーソル数)、2カラムでは2^2=4通り、3カラムでは2^3=8通り、、、と2のべき乗で増加するため、親カーソルの下に子カーソルが爆発的に大量にできてしまう。
では、子カーソルが増えることによる問題は何か。SQL実行の度にハードパースやカーソルの検索にCPUを消費する、ライブラリキャッシュを消費するといった問題は言うまでもない。しかし最も大きな問題は、ハードパース多発によってSQLの同時実行性が下がり、SQLの性能が著しく劣化(ハング)することだろう。カーソルが共有されている状況では、トランザクションはカーソルを共有ロック(cursor: mutex S)するので、競合は発生しない。しかし、ハードパースはカーソルを排他ロック(cursor: mutex X)する。このためハードパースが多発すると、SQLの実行がシリアライズされてしまう。したがって、SQLの同時実行性を保つためには、ハードパースを減らさなければならず、そのためにはカーソルが共有されるようにしなければならない。
子カーソルが共有されない理由は多数あるが、v$sql_shared_cursorを確認すればその理由を確認することができる。下記はバインドミスマッチの例であるが、子カーソルのbind_mismatch列がYになっていることがわかる。
またreason列に、明確にBind mismatchと記載されている。
さらに、v$sql_bind_captureでバインドミスマッチがどのバインド変数で発生しているかが確認できる。この場合はポジション3と4でDATEとTIMESTAMPのミスマッチが発生していることが確認できる。
なお、バインドミスマッチ以外にも子カーソルが共有されない理由は多数ある。詳細は(Troubleshooting: High Version Count Issues(Doc ID 296377.1))が参考になるだろう。
◇バインドミスマッチとの闘い その1~NUMBER型カラムにVARCHAR2型バインドの例
私がこの問題に初めて遭遇したのは、2016年頃であろうか、特定の時間帯に発生するcursor: mutex Xとcursor: mutex Sの待機によるSQL遅延、CPU高騰の事象を追いかけていた時である。テーブルは50カラム程度のNUMBER型であり、それに対するDML文で多数のバインドミスマッチが発生し、子カーソルが増加(数百を超えるオーダー)していたのである。原因はJavaのAP(正確にはMyBatis経由のJDBC)が、NULL値をVARCHAR2でバインドしていたためであった。OracleのJDBCドライバはNULLの場合に型を明示的に設定しないとデフォルトVARCHAR2型でバインドする。このため、値が入っているとき(NUMBER型でバインド)とNULL値のとき(VARCHAR2でバインド)でバインドミスマッチが発生したのである。論理的には子カーソル数は、50カラムで2^50、すなわち(2^10)^5=~(10^3)^5=10^15=1000兆にもなる。
この問題を回避するためには、MyBATISのSQLを記載するxmlファイルに、JDBC型の情報を明示的に付加する必要がある。MyBatisのドキュメントの下記の部分に記載があるように、NULLが入る可能性のあるカラムに対しては、jdbcTypeを設定すればよい。
---
Mapper XML Files
... But there are a lot of other features of parameter maps.
First, like other parts of MyBatis, parameters can specify a more specific data type.
#{property,javaType=int,jdbcType=NUMERIC}
Like the rest of MyBatis, the javaType can almost always be determined from the parameter object, unless that object is a HashMap. Then the javaType should be specified to ensure the correct TypeHandler is used.
NOTE The JDBC Type is required by JDBC for all nullable columns, if null is passed as a value. You can investigate this yourself by reading the JavaDocs for the PreparedStatement.setNull() method.
...
Despite all of these powerful options, most of the time you'll simply specify the property name, and MyBatis will figure out the rest. At most, you'll specify the jdbcType for nullable columns.
#{firstName}
#{middleInitial,jdbcType=VARCHAR}
#{lastName}
---
MyBatisのJDBCの使い方の実装を確認した訳ではないのであくまで想像であるが、MyBatisは型指定されていないバインド変数にnullが来た場合は、setNullを以下のようにjava.sql.Types.NULLで渡しているのではないか。この場合、OracleのJDBCドライバはVARCHAR2(32)型としてバインドしてしまう(※)ため、NULLとそうでない場合のバインドミスマッチが発生する。
if (i==null) ps.setNull(col_pos,java.sql.Types.NULL); else ps.setInt(col_pos, i);
※Troubleshooting cursor: mutex X Due to High Version Count on the Insert Statements with Binds using JDBC (Doc ID 1469726.1)
一方、MyBatisのjdbcTypeに型を明示的に指定すると、setNullの型を以下のように明示的に指定することができ、OracleへNUMBER型としてバインドすることができるのではないか。これなら、バインドミスマッチは発生しない。
if (i==null) ps.setNull(col_pos,java.sql.Types.INTEGER); else ps.setInt(col_pos i);
上記はNUMBER型カラムでバインドミスマッチが発生した例であるが、同じことはDATE型カラムでもNULLの入る型なら発生するはずである。唯一、VARCHAR2カラムだけは(JDBCのnullのデフォルトがVARCHAR2のため)この問題が顕在化することはない。
◇バインドミスマッチとの闘い その2~DATE型カラムにTIMESTAMP型バインドの例
今回私が遭遇した事例は、50カラム程度のDATE型があるテーブルに対するDMLであった。これもNULLの場合はDATE型、そうでない場合はTIMESTAMP型でバインドしていることが原因でバインドミスマッチが発生していた。javaのソース(JDBC)を確認すると、DATE型カラムに対して、NULLの場合はDATE型、そうでない場合はTimestamp型でバインドするコードになっていた。以下は状況を再現したサンプルAPである。java.sql.Timestamp型のvがnullなら、setNullでDATE型でバインド、そうでない場合はsetTImestampでTIMESTAMP型でバインドしている。
if (Objects.isNull(v)) ps.setNull(col_pos,java.sql.Types.DATE); else ps.setTimestamp(col_pos, v);
このようなコーディングがされている理由は後述するとして、本来どのようにDATE型をバインドすべきだろうか。javaのコーディングについては素人ではあるが、JDBC developer's guideを読む限りは、vをoracle.sql.DATE型として、以下のようなコーディングをすればよい。手元の環境で確認した限り、きちんとDATE型バインドされるようになった。
if (Objects.isNull(v)) ps.setNull(col_pos,java.sql.Types.DATE); else ((OraclePreparedStatement)ps).setOracleObject(col_pos, v);
※参考:11.4.6 The setObject and setOracleObject Methods
しかし、個人的にはこのコーディングはOracleに寄りすぎている感も否めない。vをjava.sql.Date型とし、以下のように記述する方がJDBC的には自然かもしれない。これでも、DATE型バインドされる。
if (Objects.isNull(v)) ps.setNull(col_pos,java.sql.Types.DATE); else ps.setDate(col_pos, v);
setDateは時分秒を設定できないものと思っていたが、12.1.0.1からJDBCドライバの仕様が変わっており、java.sql.Dateに設定された時分秒も、setDateできちんとDATE型に変換されるようになっているそうである(Doc ID 1944845.1)。なお、11.2.0.4より前では、時分秒は"00:00:00"となるのが仕様である。
◇JDBCのDATE型のバインドの歴史
今回、上記その2の事例でOracleのDATE型に対するJDBCのバインドについて調べる中で、その経緯を根深さに驚かされた。
おそらくこのAPはTIMESTAMP型がないOracle8の頃に作られたのであろう。OracleのDATE型は時分秒を持つが、JavaのDate型は日付のみしか持たない。このため、DATE型に対してjavaのTimestamp型でバインドするのは一般的なコーディングであったのだろう。このときは、以下のようにDATE型とTimestamp型はJDBCで透過的にマッピングされていた。このため、上記のようなコーディングでも、DATE型バインドに統一され、バインドミスマッチは発生しない。
Oracle:DATE <- -> java:Timestamp
しかし9iR2でOracleにTimestamp型が導入される。このときOracleは以下のようにJDBCのマッピングを変更してしまった。これは(Oracleも認めているが)明らかな誤りである。例えば時分秒を持つDATE型カラムをSELECTすると、時分秒を持たないjavaのDate型に変換されてしまうため、時分秒が欠落してしまう。この結果、多くのJDBCを使うAPにおいて非互換の問題を発生させることとなった。
Oracle:DATE <- -> java:Date ★
Oracle:TIMESTAMP <- -> java:Timestamp
このため、Oracleは従来のマッピングをさせるV8CompatibleというフラグをJDBCドライバに導入した。これを以下のようにtrueに設定すると、JDBCはOracle8iのときと同様にDATE型とTimestamp型を透過的に変換するようになる。おそらく9iに更改した経験のあるシステムでは、WebLogic等のAPサーバにこの設定を入れて非互換を回避したに違いない。
java -Doracle.jdbc.V8Compatible="true" MyApp
Oracle:DATE <- -> java:Timestamp ★V8Compatible
Oracle:TIMESTAMP -> java:Timestamp
Oracleがこの問題を本格的に対処したのは11.1である。mapDateToTimestamp(デフォルト値がtrue)が導入され、以下のようにOracleのDATE型はjavaのTimestampにデフォルトでマッピングされるようになった。このとき、Oracleはこの問題は解決されたこと、そしてOracle8iのサポートが終了したことを理由に、V8Compatibleの使用は強く非推奨とし、サポートを止めたのである。そして、19cとなった今現在も、このマッピングは基本的に変わっていない。
Oracle:DATE <- java:Date
Oracle:DATE -> java:Timestamp ★mapDateToTimestamp
Oracle:TIMESTAMP <- -> java:Timestamp
OracleがV8Compatibleを実際に機能から外したのは恐らく11.2である。その根拠は、以下のMOSのドキュメントに11.2ドライバでV8Compatibleが機能しないことが示されている。
JDBC 11g: Timestamp から Date へのマッピング (Doc ID 1933596.1)
また、間接的ではあるが、JDBC developer's guideを時系列で比較すると、11.2でDATE型に対するJDBCの型マッピングがoracle.sql.DATE一択に変更されていることから、ここで大きなコードに修正が入った可能性を示唆している。
Valid SQL-JDBC Datatype Mappings
SQL datatypes: DATE Can be materialized as these Java types:
◆9.2.0
oracle.sql.DATE
java.sql.Date
java.sql.Time
java.sql.Timestamp
◆10.1~11.1
oracle.sql.DATE
java.sql.Date
java.sql.Time
java.sql.Timestamp
java.lang.String
◆11.2~19
oracle.sql.DATE
上記が正しい場合、V8Compatibleに依存していたAPは、11.2を境にJavaのTimestamp型がDATE型でなくTIMESTAMP型にマッピングされるよう挙動が変わる。これが、冒頭のバインドミスマッチが発生するようになった原因であると考えられる。
◇DATE型にTIMESTAMP型バインドしたときの影響
この問題がバインドミスマッチ以外にどのような影響を及ぼす可能性があるのか。1つが上記DocID 1933596.1で示された結果不正となる事例である。例えば、DATE型カラムHIREDATEを持つ空のEMP表があり、以下のようにHIREDATEに同じ値をバインドしINSERTとSELECTを実行するとする。期待する結果はINSERTされたレコードが1件、SELECTで件数として返却されることである。
INSERT INTO EMP (... HIREDATE) VALUES (... ?);
SELECT COUNT(*) WHERE HIREDATE = ?
ここで、HIREDATEをsetTimestampでバインドすると、INSERTではOracleはTIMESTAMP型を暗黙的型変換しDATE型に変換する。このとき、小数点以下の秒は削除してカラムに格納される。次にSELECTのWHERE句を同様にsetTimestampでバインドする。このとき、OracleはDATE型とTIMESTAMP型は直接比較できないため、HIREDATEカラムをTIMESTAMP型に暗黙的型変換をする。ここでバインド変数側に秒以下の値が入っていると、WHERE句の条件が真にならず、件数が0件で返ってくるということが起こる。この問題は、V8Compatibleが有効に機能していれば、setTimestampはDATE型としてバインドされるため発生しない。
もう一つ考えられるのは、TIMESTAMP型への暗黙的型変換によりDATE型の索引が使われなくなるDocID 1557194.1の問題である。WHERE句のバインドにおいて、DATE型カラムの条件をTIMESTAMP型でバインドすると、DATE型カラムの方にTO_TIMESTAMPによる変換が発生し、このDATE型カラムに張られた索引が使われない、という事象である。上記の例ではHIREDATEのINDEX RANGE SCANを期待したところ、実行計画のpredicate部にTO_TIMESTAMP(HIREDATE)が出てしまい、EMPのフルスキャンになってしまう、ということが想定される。
Poor Performance With Query Called From JDBC Using Bind Variables Compared To A DATE Column (Doc ID 1557194.1)
なお、この問題はTIMESTAMP型とDATE型を直接比較できるように12.2で修正され、11gにもパッチが提供されているようである。これもV8Compatibleが有効に機能していれば発生しない問題である。
◇BIND_LENGTH_UPGRADEABLEによる子カーソル増加の問題
先にも述べた通り子カーソルが共有されない原因はバインドミスマッチだけではない。しかし、バインドミスマッチが如何に罪深いか、BIND_LENGTH_UPGRADEABLEと比較してみよう。
VARCHAR2をバインドするとき、バインド変数のバッファ長に応じて以下の4つのパターンでバインドする。例えば、(1)の文字列長でバインドした後、それより大きい(2)のパターンでバインドすると、カーソルは共有されずハードパースが走り、新たな子カーソルが作成される。これがBIND_LENGTH_UPGRADEABLEである。
(a)0~32バイト →VARCHAR2(32)でバインド
(b)33~128バイト →VARCHAR2(128)でバインド
(c)129~2000バイト →VARCHAR2(2000)でバインド
(d)2001~4000バイト →VARCHAR2(4000)でバインド
実際に2つのVARCHAR2カラムc1,c2をバインドするDMLを4回実行する例を見てみよう。JDBCで2つのVARCHAR2(40)型カラム(c1,c2)を持つEMP表のレコードを以下の条件で更新する。手元の環境では19.3、DBのNLS_CHARACTERSETがAL32UTF8のためか、Javaで8バイトまでがVARCHAR2(32)でバインドされる。
(1)c1="123", c2="123"
(2)c1="123456789", c2="123"
(3)c1="123", c2="123456789"
(4)c1="123456789", c2="123456789"
(5)c1="123456789012345678901234567890123", c2="123456789"
(6)c1="123456789", c2="123456789012345678901234567890123"
(7)c1="123456789012345678901234567890123", c2="123456789012345678901234567890123"
実行した結果、v$sql_bind_captureは以下の通り、子カーソルが5個確認できる。
上記の結果から、以下のような動きになっていたと考えられる。
(1)でハードパース★。c1はVARCHAR2(32), c2はVARCHAR2(32)でバインドされる
(2)はハードパース★。c1はVARCHAR2(128), c2はVARCHAR2(32)でバインドされる。
(3)はハードパース★。c1はVARCHAR2(128), c2はVARCHAR2(128)でバインドされる。
(4)は(3)のカーソルが共有されソフトパース
(5)はハードパース★。c1はVARCHAR2(2000), c2はVARCHAR2(128)でバインドされる。
(6)はハードパース★。c1はVARCHAR2(2000), c2はVARCHAR2(2000)でバインドされる。
(7)は(6)のカーソルが共有されソフトパース
1つのVARCHAR2カラムに対して、最大4つのバリエーションの子カーソルが発生する可能性があると考えると、4^カラム数だけの子カーソルが発生し、バインドミスマッチより組み合わせが増えるのではないかと考えてしまうかもしれない。しかし上記の動きから考えると、実際はアップグレードされたバッファサイズは大きくなる1方向であり、一度大きい型でバインドされればそれ以下の型でバインドされることはない。これは3x3の格子を左下から右上まで移動するのに経由した座標の数に等しいと考えると、3x2+1=7となる。したがって、一般的にはカラム数Nに対し、BIND_LENGTH_UPGRADEABLEにより発生する最大の子カーソル数はたかだか3N+1となる。カラム数の増加に対し、バインドミスマッチが如何に問題を引き起こしやすいか理解できるだろう。
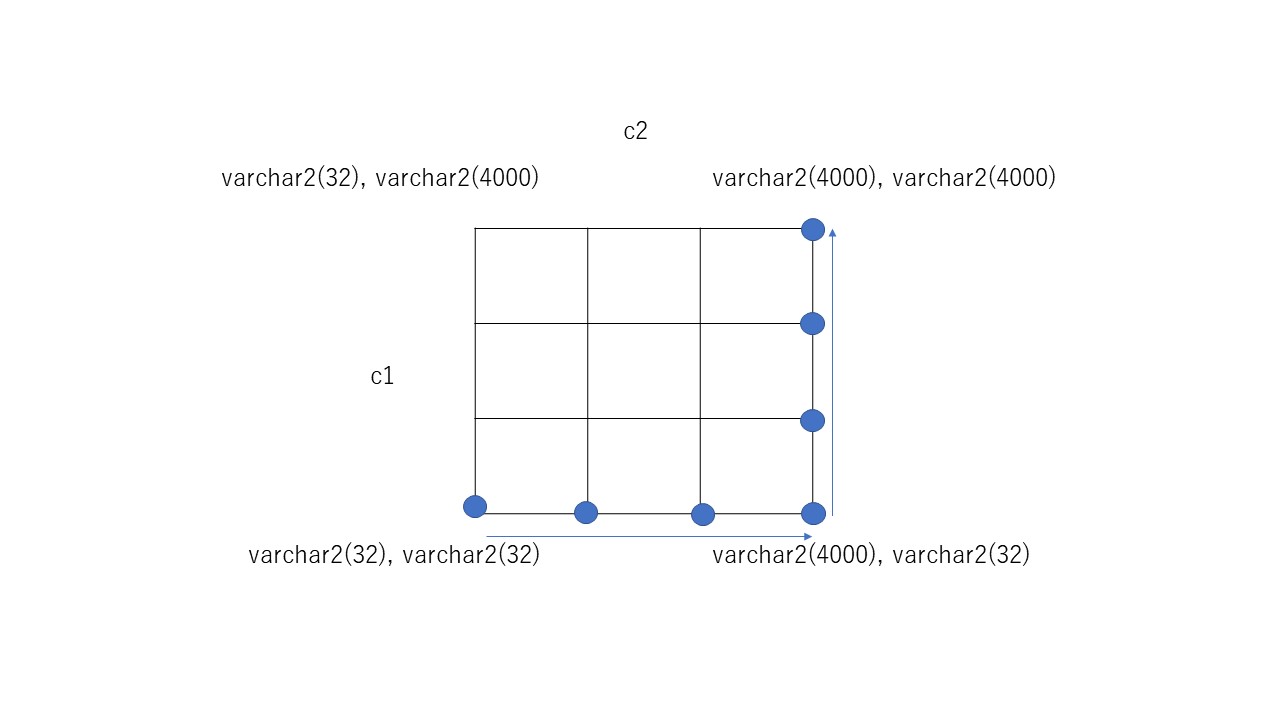
また、BIND_LENGTH_UPGRADEABLEにより子カーソルが作られた場合、v$sql.IS_SHAREABLEが最新のものだけがYとなる。古い子カーソルは共有されることがないようすべてNとなり、優先的なパージ対象となることも特筆すべき点だろう。
◇バインドミスマッチの罪
以上のことから、バインドミスマッチの罪深さをまとめると、以下の通りである。
・カラム数Nに対し2^Nのオーダーで爆発的に子カーソルが増える
・ハードパースが多発し、大量の子カーソルの排他制御のため同時実行性が低下する
・すべての子カーソルでIS_SHAREABLEがYのためパージされにくい
・共有プールを無駄に使用する
・ハードパースや子カーソルの検索でCPUを消費する
・データバリエーション、多重度の組み合わせで遅延が顕在化するため、試験での検出や問題の再現が困難
・AP修正は概して広範囲にわたり、実質的に修正が困難
したがって、この問題を防ぐには適切なコーディン規約を作ることは言うまでもないが、それにも増して重要なのは、Oracleを使うJava技術者にこの事実を広く知っていただきたいということである。
そして冒頭で述べたように、どのようなフレームワークを用いるにしてもJavaでOracleを使う場合は、以下のことに注意することを心からお勧めする。
・DATE型カラムに対して(TIMESTAMP型でなく)DATE型でバインドすること
・NULL値の場合にカラムの型でバインドすること(setNullにjava.sql.Types.NULLを渡してはいけない)
以上
2020/5/25追記
今回、JDBCとiBatis・myBatisのJavaのフレームワーク経由でOracleに接続する場合のバインドミスマッチについて述べたが、アーキテクチャ上、他のJavaのフレームワークでも同様の事象は発生し得ると考えられる点、注意が必要だろう。
例えばnodes.jsのOracleのドライバは、DMLではDATE型やTIMESTAMP型をTIMESTAMP WITH LOCAL TIME ZONEとしてバインドする。小規模なプログラムでは問題ないだろうが、大規模な開発では意識しておく必要があるだろう。
参考:Working with Dates Using the Oracle Node.js Driver
逆にPro*CではDMLは一般的にVARCHARでバインドし、SQL側でTO_DATEするのが一般的であるため、この問題が発生するケースは稀と思われる。
参考:Pro*C/C++ Programmer's Guide 19c
以上
なお、先に結論を書いておくと、今回の教訓としては、JavaでOracleを使う場合は以下2点に注意、ということである。
・DATE型カラムに対してTIMESTAMP型でなくDATE型でバインドすること
・NULL値の場合にカラムの型でバインドすること(setNullにjava.sql.Types.NULLを渡してはいけない)
そして、それを怠った場合の代償として、バインドミスマッチが発生するカラム数に応じて、2のべき乗で子カーソルが爆発的に増加する事象が発生する。
◇バインドミスマッチによる子カーソル増加の問題
バインドミスマッチとは、バインド変数を利用しているSQL、DMLにおいて、バインド変数の型の不一致で共有プール上のカーソルが共有されない事象を指す。例えば、あるテーブルにDATE型カラムがあり、これを更新するUPDATE文があったとしよう。バインド変数を使っていれば、UPDATE文にどのような値が入ってもSQLIDは同じであり、カーソルは共有されることを期待する。しかし、ここで、DATE型に対し、DATE型でバインドするのと、TIMESTAMP型でバインドするのでは、SQLIDは同じでもOracle内部では異なるカーソル(厳密には1つの親カーソルに対し、2つの子カーソル)として管理される。これがバインドミスマッチである。
実際にバインドミスマッチの発生している状況を見てみよう。EMP表にはc3,c4のDATE型カラムがある。update文でc3,c4それぞれにDATE型とTIMESTAMP型の2つのパターンでバインドし、4通りの組み合わせで実行する。結果、このSQLの子カーソル数(VERSION_COUNT)が4になる。つまり、バインド変数を使い同じSQLを実行しているにも関わらず、カーソルが共有されず、それぞれハードパースされているのだ。本来バインドミスマッチが発生しなければ、VERSION_COUNTは1になるはずである。なお、手元の環境はOracle19.3である。
SQL> desc scott.emp Name Null? Type ----------------------------------------- -------- ---------------------------- C1 NOT NULL NUMBER C2 VARCHAR2(40) C3 VARCHAR2(40) C4 DATE C5 DATE SQL> select sql_id, version_count, last_load_time, sql_text from v$sqlarea where sql_id='0hrt1s7pkz2qf'; SQL_ID VERSION_COUNT LAST_LOAD_TIME SQL_TEXT ------------- ------------- -------------------- ---------------------------------------- 0hrt1s7pkz2qf 4 20200426 00:40:35 UPDATE /* BINDTEST */ emp SET c2 = :1 , c3 = :2 , c4=:3 , c5=:4 WHERE c1 = :5 SQL> select sql_id, child_number, last_load_time, is_shareable, sql_text from v$sql where sql_id='0hrt1s7pkz2qf'; SQL_ID CHILD_NUMBER LAST_LOAD_TIME I SQL_TEXT ------------- ------------ -------------------- - ---------------------------------------- 0hrt1s7pkz2qf 0 2020-04-26/00:40:35 Y UPDATE /* BINDTEST */ emp SET c2 = :1 , c3 = :2 , c4=:3 , c5=:4 WHERE c1 = :5 0hrt1s7pkz2qf 1 2020-04-26/00:40:35 Y UPDATE /* BINDTEST */ emp SET c2 = :1 , c3 = :2 , c4=:3 , c5=:4 WHERE c1 = :5 0hrt1s7pkz2qf 2 2020-04-26/00:40:35 Y UPDATE /* BINDTEST */ emp SET c2 = :1 , c3 = :2 , c4=:3 , c5=:4 WHERE c1 = :5 0hrt1s7pkz2qf 3 2020-04-26/00:40:35 Y UPDATE /* BINDTEST */ emp SET c2 = :1 , c3 = :2 , c4=:3 , c5=:4 WHERE c1 = :5
子カーソルが4個になることくらいは大した問題でないと思うかもしれない。しかし、これが様々なカラムで発生すると、1カラムで2通りの組み合わせ(=カーソル数)、2カラムでは2^2=4通り、3カラムでは2^3=8通り、、、と2のべき乗で増加するため、親カーソルの下に子カーソルが爆発的に大量にできてしまう。
では、子カーソルが増えることによる問題は何か。SQL実行の度にハードパースやカーソルの検索にCPUを消費する、ライブラリキャッシュを消費するといった問題は言うまでもない。しかし最も大きな問題は、ハードパース多発によってSQLの同時実行性が下がり、SQLの性能が著しく劣化(ハング)することだろう。カーソルが共有されている状況では、トランザクションはカーソルを共有ロック(cursor: mutex S)するので、競合は発生しない。しかし、ハードパースはカーソルを排他ロック(cursor: mutex X)する。このためハードパースが多発すると、SQLの実行がシリアライズされてしまう。したがって、SQLの同時実行性を保つためには、ハードパースを減らさなければならず、そのためにはカーソルが共有されるようにしなければならない。
子カーソルが共有されない理由は多数あるが、v$sql_shared_cursorを確認すればその理由を確認することができる。下記はバインドミスマッチの例であるが、子カーソルのbind_mismatch列がYになっていることがわかる。
SQL> select sql_id,child_number,bind_mismatch,reason from v$sql_shared_cursor where sql_id='0hrt1s7pkz2qf'; SQL_ID CHILD_NUMBER B REASON ------------- ------------ - -------------------------------------------------------------------------------- 0hrt1s7pkz2qf 0 N <ChildNode><ChildNumber>0</ChildNumber><ID>39</ID><reason>Bind mismatch(8)</reas 0hrt1s7pkz2qf 1 Y <ChildNode><ChildNumber>1</ChildNumber><ID>39</ID><reason>Bind mismatch(8)</reas 0hrt1s7pkz2qf 2 Y <ChildNode><ChildNumber>2</ChildNumber><ID>39</ID><reason>Bind mismatch(8)</reas 0hrt1s7pkz2qf 3 Y <ChildNode><ChildNumber>3</ChildNumber><ID>39</ID><reason>Bind mismatch(8)</reas
またreason列に、明確にBind mismatchと記載されている。
<ChildNode> <ChildNumber>3</ChildNumber> <ID>39</ID> <reason>Bind mismatch(8)</reason>★ <size>4x8</size> <bind_position>0000000200000000 </bind_position> <original_oacflg>0000000300000000 </original_oacflg> <original_oacdty>000000b400000000 </original_oacdty> <new_oacdty>0000000c00000000 </new_oacdty> </ChildNode>
さらに、v$sql_bind_captureでバインドミスマッチがどのバインド変数で発生しているかが確認できる。この場合はポジション3と4でDATEとTIMESTAMPのミスマッチが発生していることが確認できる。
SQL> select sql_id,child_number,position,datatype_string,precision,scale from v$sql_bind_capture where sql_id='0hrt1s7pkz2qf' order by 2,3; SQL_ID CHILD_NUMBER POSITION DATATYPE_STRING PRECISION SCALE ------------- ------------ ---------- -------------------- ---------- ---------- 0hrt1s7pkz2qf 0 1 VARCHAR2(128) 0hrt1s7pkz2qf 0 2 VARCHAR2(2000) 0hrt1s7pkz2qf 0 3 DATE 0hrt1s7pkz2qf 0 4 DATE 0hrt1s7pkz2qf 0 5 NUMBER 0hrt1s7pkz2qf 1 1 VARCHAR2(128) 0hrt1s7pkz2qf 1 2 VARCHAR2(2000) 0hrt1s7pkz2qf 1 3 TIMESTAMP 9 0hrt1s7pkz2qf 1 4 DATE 0hrt1s7pkz2qf 1 5 NUMBER 0hrt1s7pkz2qf 2 1 VARCHAR2(128) 0hrt1s7pkz2qf 2 2 VARCHAR2(2000) 0hrt1s7pkz2qf 2 3 DATE 0hrt1s7pkz2qf 2 4 TIMESTAMP 9 0hrt1s7pkz2qf 2 5 NUMBER 0hrt1s7pkz2qf 3 1 VARCHAR2(128) 0hrt1s7pkz2qf 3 2 VARCHAR2(2000) 0hrt1s7pkz2qf 3 3 TIMESTAMP 9 0hrt1s7pkz2qf 3 4 TIMESTAMP 9 0hrt1s7pkz2qf 3 5 NUMBER
なお、バインドミスマッチ以外にも子カーソルが共有されない理由は多数ある。詳細は(Troubleshooting: High Version Count Issues(Doc ID 296377.1))が参考になるだろう。
◇バインドミスマッチとの闘い その1~NUMBER型カラムにVARCHAR2型バインドの例
私がこの問題に初めて遭遇したのは、2016年頃であろうか、特定の時間帯に発生するcursor: mutex Xとcursor: mutex Sの待機によるSQL遅延、CPU高騰の事象を追いかけていた時である。テーブルは50カラム程度のNUMBER型であり、それに対するDML文で多数のバインドミスマッチが発生し、子カーソルが増加(数百を超えるオーダー)していたのである。原因はJavaのAP(正確にはMyBatis経由のJDBC)が、NULL値をVARCHAR2でバインドしていたためであった。OracleのJDBCドライバはNULLの場合に型を明示的に設定しないとデフォルトVARCHAR2型でバインドする。このため、値が入っているとき(NUMBER型でバインド)とNULL値のとき(VARCHAR2でバインド)でバインドミスマッチが発生したのである。論理的には子カーソル数は、50カラムで2^50、すなわち(2^10)^5=~(10^3)^5=10^15=1000兆にもなる。
この問題を回避するためには、MyBATISのSQLを記載するxmlファイルに、JDBC型の情報を明示的に付加する必要がある。MyBatisのドキュメントの下記の部分に記載があるように、NULLが入る可能性のあるカラムに対しては、jdbcTypeを設定すればよい。
---
Mapper XML Files
... But there are a lot of other features of parameter maps.
First, like other parts of MyBatis, parameters can specify a more specific data type.
#{property,javaType=int,jdbcType=NUMERIC}
Like the rest of MyBatis, the javaType can almost always be determined from the parameter object, unless that object is a HashMap. Then the javaType should be specified to ensure the correct TypeHandler is used.
NOTE The JDBC Type is required by JDBC for all nullable columns, if null is passed as a value. You can investigate this yourself by reading the JavaDocs for the PreparedStatement.setNull() method.
...
Despite all of these powerful options, most of the time you'll simply specify the property name, and MyBatis will figure out the rest. At most, you'll specify the jdbcType for nullable columns.
#{firstName}
#{middleInitial,jdbcType=VARCHAR}
#{lastName}
---
MyBatisのJDBCの使い方の実装を確認した訳ではないのであくまで想像であるが、MyBatisは型指定されていないバインド変数にnullが来た場合は、setNullを以下のようにjava.sql.Types.NULLで渡しているのではないか。この場合、OracleのJDBCドライバはVARCHAR2(32)型としてバインドしてしまう(※)ため、NULLとそうでない場合のバインドミスマッチが発生する。
if (i==null) ps.setNull(col_pos,java.sql.Types.NULL); else ps.setInt(col_pos, i);
※Troubleshooting cursor: mutex X Due to High Version Count on the Insert Statements with Binds using JDBC (Doc ID 1469726.1)
一方、MyBatisのjdbcTypeに型を明示的に指定すると、setNullの型を以下のように明示的に指定することができ、OracleへNUMBER型としてバインドすることができるのではないか。これなら、バインドミスマッチは発生しない。
if (i==null) ps.setNull(col_pos,java.sql.Types.INTEGER); else ps.setInt(col_pos i);
上記はNUMBER型カラムでバインドミスマッチが発生した例であるが、同じことはDATE型カラムでもNULLの入る型なら発生するはずである。唯一、VARCHAR2カラムだけは(JDBCのnullのデフォルトがVARCHAR2のため)この問題が顕在化することはない。
◇バインドミスマッチとの闘い その2~DATE型カラムにTIMESTAMP型バインドの例
今回私が遭遇した事例は、50カラム程度のDATE型があるテーブルに対するDMLであった。これもNULLの場合はDATE型、そうでない場合はTIMESTAMP型でバインドしていることが原因でバインドミスマッチが発生していた。javaのソース(JDBC)を確認すると、DATE型カラムに対して、NULLの場合はDATE型、そうでない場合はTimestamp型でバインドするコードになっていた。以下は状況を再現したサンプルAPである。java.sql.Timestamp型のvがnullなら、setNullでDATE型でバインド、そうでない場合はsetTImestampでTIMESTAMP型でバインドしている。
if (Objects.isNull(v)) ps.setNull(col_pos,java.sql.Types.DATE); else ps.setTimestamp(col_pos, v);
このようなコーディングがされている理由は後述するとして、本来どのようにDATE型をバインドすべきだろうか。javaのコーディングについては素人ではあるが、JDBC developer's guideを読む限りは、vをoracle.sql.DATE型として、以下のようなコーディングをすればよい。手元の環境で確認した限り、きちんとDATE型バインドされるようになった。
if (Objects.isNull(v)) ps.setNull(col_pos,java.sql.Types.DATE); else ((OraclePreparedStatement)ps).setOracleObject(col_pos, v);
※参考:11.4.6 The setObject and setOracleObject Methods
しかし、個人的にはこのコーディングはOracleに寄りすぎている感も否めない。vをjava.sql.Date型とし、以下のように記述する方がJDBC的には自然かもしれない。これでも、DATE型バインドされる。
if (Objects.isNull(v)) ps.setNull(col_pos,java.sql.Types.DATE); else ps.setDate(col_pos, v);
setDateは時分秒を設定できないものと思っていたが、12.1.0.1からJDBCドライバの仕様が変わっており、java.sql.Dateに設定された時分秒も、setDateできちんとDATE型に変換されるようになっているそうである(Doc ID 1944845.1)。なお、11.2.0.4より前では、時分秒は"00:00:00"となるのが仕様である。
◇JDBCのDATE型のバインドの歴史
今回、上記その2の事例でOracleのDATE型に対するJDBCのバインドについて調べる中で、その経緯を根深さに驚かされた。
おそらくこのAPはTIMESTAMP型がないOracle8の頃に作られたのであろう。OracleのDATE型は時分秒を持つが、JavaのDate型は日付のみしか持たない。このため、DATE型に対してjavaのTimestamp型でバインドするのは一般的なコーディングであったのだろう。このときは、以下のようにDATE型とTimestamp型はJDBCで透過的にマッピングされていた。このため、上記のようなコーディングでも、DATE型バインドに統一され、バインドミスマッチは発生しない。
Oracle:DATE <- -> java:Timestamp
しかし9iR2でOracleにTimestamp型が導入される。このときOracleは以下のようにJDBCのマッピングを変更してしまった。これは(Oracleも認めているが)明らかな誤りである。例えば時分秒を持つDATE型カラムをSELECTすると、時分秒を持たないjavaのDate型に変換されてしまうため、時分秒が欠落してしまう。この結果、多くのJDBCを使うAPにおいて非互換の問題を発生させることとなった。
Oracle:DATE <- -> java:Date ★
Oracle:TIMESTAMP <- -> java:Timestamp
このため、Oracleは従来のマッピングをさせるV8CompatibleというフラグをJDBCドライバに導入した。これを以下のようにtrueに設定すると、JDBCはOracle8iのときと同様にDATE型とTimestamp型を透過的に変換するようになる。おそらく9iに更改した経験のあるシステムでは、WebLogic等のAPサーバにこの設定を入れて非互換を回避したに違いない。
java -Doracle.jdbc.V8Compatible="true" MyApp
Oracle:DATE <- -> java:Timestamp ★V8Compatible
Oracle:TIMESTAMP -> java:Timestamp
Oracleがこの問題を本格的に対処したのは11.1である。mapDateToTimestamp(デフォルト値がtrue)が導入され、以下のようにOracleのDATE型はjavaのTimestampにデフォルトでマッピングされるようになった。このとき、Oracleはこの問題は解決されたこと、そしてOracle8iのサポートが終了したことを理由に、V8Compatibleの使用は強く非推奨とし、サポートを止めたのである。そして、19cとなった今現在も、このマッピングは基本的に変わっていない。
Oracle:DATE <- java:Date
Oracle:DATE -> java:Timestamp ★mapDateToTimestamp
Oracle:TIMESTAMP <- -> java:Timestamp
OracleがV8Compatibleを実際に機能から外したのは恐らく11.2である。その根拠は、以下のMOSのドキュメントに11.2ドライバでV8Compatibleが機能しないことが示されている。
JDBC 11g: Timestamp から Date へのマッピング (Doc ID 1933596.1)
また、間接的ではあるが、JDBC developer's guideを時系列で比較すると、11.2でDATE型に対するJDBCの型マッピングがoracle.sql.DATE一択に変更されていることから、ここで大きなコードに修正が入った可能性を示唆している。
Valid SQL-JDBC Datatype Mappings
SQL datatypes: DATE Can be materialized as these Java types:
◆9.2.0
oracle.sql.DATE
java.sql.Date
java.sql.Time
java.sql.Timestamp
◆10.1~11.1
oracle.sql.DATE
java.sql.Date
java.sql.Time
java.sql.Timestamp
java.lang.String
◆11.2~19
oracle.sql.DATE
上記が正しい場合、V8Compatibleに依存していたAPは、11.2を境にJavaのTimestamp型がDATE型でなくTIMESTAMP型にマッピングされるよう挙動が変わる。これが、冒頭のバインドミスマッチが発生するようになった原因であると考えられる。
◇DATE型にTIMESTAMP型バインドしたときの影響
この問題がバインドミスマッチ以外にどのような影響を及ぼす可能性があるのか。1つが上記DocID 1933596.1で示された結果不正となる事例である。例えば、DATE型カラムHIREDATEを持つ空のEMP表があり、以下のようにHIREDATEに同じ値をバインドしINSERTとSELECTを実行するとする。期待する結果はINSERTされたレコードが1件、SELECTで件数として返却されることである。
INSERT INTO EMP (... HIREDATE) VALUES (... ?);
SELECT COUNT(*) WHERE HIREDATE = ?
ここで、HIREDATEをsetTimestampでバインドすると、INSERTではOracleはTIMESTAMP型を暗黙的型変換しDATE型に変換する。このとき、小数点以下の秒は削除してカラムに格納される。次にSELECTのWHERE句を同様にsetTimestampでバインドする。このとき、OracleはDATE型とTIMESTAMP型は直接比較できないため、HIREDATEカラムをTIMESTAMP型に暗黙的型変換をする。ここでバインド変数側に秒以下の値が入っていると、WHERE句の条件が真にならず、件数が0件で返ってくるということが起こる。この問題は、V8Compatibleが有効に機能していれば、setTimestampはDATE型としてバインドされるため発生しない。
もう一つ考えられるのは、TIMESTAMP型への暗黙的型変換によりDATE型の索引が使われなくなるDocID 1557194.1の問題である。WHERE句のバインドにおいて、DATE型カラムの条件をTIMESTAMP型でバインドすると、DATE型カラムの方にTO_TIMESTAMPによる変換が発生し、このDATE型カラムに張られた索引が使われない、という事象である。上記の例ではHIREDATEのINDEX RANGE SCANを期待したところ、実行計画のpredicate部にTO_TIMESTAMP(HIREDATE)が出てしまい、EMPのフルスキャンになってしまう、ということが想定される。
Poor Performance With Query Called From JDBC Using Bind Variables Compared To A DATE Column (Doc ID 1557194.1)
なお、この問題はTIMESTAMP型とDATE型を直接比較できるように12.2で修正され、11gにもパッチが提供されているようである。これもV8Compatibleが有効に機能していれば発生しない問題である。
◇BIND_LENGTH_UPGRADEABLEによる子カーソル増加の問題
先にも述べた通り子カーソルが共有されない原因はバインドミスマッチだけではない。しかし、バインドミスマッチが如何に罪深いか、BIND_LENGTH_UPGRADEABLEと比較してみよう。
VARCHAR2をバインドするとき、バインド変数のバッファ長に応じて以下の4つのパターンでバインドする。例えば、(1)の文字列長でバインドした後、それより大きい(2)のパターンでバインドすると、カーソルは共有されずハードパースが走り、新たな子カーソルが作成される。これがBIND_LENGTH_UPGRADEABLEである。
(a)0~32バイト →VARCHAR2(32)でバインド
(b)33~128バイト →VARCHAR2(128)でバインド
(c)129~2000バイト →VARCHAR2(2000)でバインド
(d)2001~4000バイト →VARCHAR2(4000)でバインド
実際に2つのVARCHAR2カラムc1,c2をバインドするDMLを4回実行する例を見てみよう。JDBCで2つのVARCHAR2(40)型カラム(c1,c2)を持つEMP表のレコードを以下の条件で更新する。手元の環境では19.3、DBのNLS_CHARACTERSETがAL32UTF8のためか、Javaで8バイトまでがVARCHAR2(32)でバインドされる。
(1)c1="123", c2="123"
(2)c1="123456789", c2="123"
(3)c1="123", c2="123456789"
(4)c1="123456789", c2="123456789"
(5)c1="123456789012345678901234567890123", c2="123456789"
(6)c1="123456789", c2="123456789012345678901234567890123"
(7)c1="123456789012345678901234567890123", c2="123456789012345678901234567890123"
実行した結果、v$sql_bind_captureは以下の通り、子カーソルが5個確認できる。
SQL> select sql_id,child_number,position,datatype_string,precision,scale from v$sql_bind_capture where sql_id='0hrt1s7pkz2qf' order by 2,3; SQL_ID CHILD_NUMBER POSITION DATATYPE_STRING PRECISION SCALE ------------- ------------ ---------- -------------------- ---------- ---------- 0hrt1s7pkz2qf 0 1 VARCHAR2(32) 0hrt1s7pkz2qf 0 2 VARCHAR2(32) 0hrt1s7pkz2qf 0 3 DATE 0hrt1s7pkz2qf 0 4 DATE 0hrt1s7pkz2qf 0 5 NUMBER 0hrt1s7pkz2qf 1 1 VARCHAR2(128) 0hrt1s7pkz2qf 1 2 VARCHAR2(32) 0hrt1s7pkz2qf 1 3 DATE 0hrt1s7pkz2qf 1 4 DATE 0hrt1s7pkz2qf 1 5 NUMBER 0hrt1s7pkz2qf 2 1 VARCHAR2(128) 0hrt1s7pkz2qf 2 2 VARCHAR2(128) 0hrt1s7pkz2qf 2 3 DATE 0hrt1s7pkz2qf 2 4 DATE 0hrt1s7pkz2qf 2 5 NUMBER 0hrt1s7pkz2qf 3 1 VARCHAR2(2000) 0hrt1s7pkz2qf 3 2 VARCHAR2(128) 0hrt1s7pkz2qf 3 3 DATE 0hrt1s7pkz2qf 3 4 DATE 0hrt1s7pkz2qf 3 5 NUMBER 0hrt1s7pkz2qf 4 1 VARCHAR2(2000) 0hrt1s7pkz2qf 4 2 VARCHAR2(2000) 0hrt1s7pkz2qf 4 3 DATE 0hrt1s7pkz2qf 4 4 DATE 0hrt1s7pkz2qf 4 5 NUMBER
上記の結果から、以下のような動きになっていたと考えられる。
(1)でハードパース★。c1はVARCHAR2(32), c2はVARCHAR2(32)でバインドされる
(2)はハードパース★。c1はVARCHAR2(128), c2はVARCHAR2(32)でバインドされる。
(3)はハードパース★。c1はVARCHAR2(128), c2はVARCHAR2(128)でバインドされる。
(4)は(3)のカーソルが共有されソフトパース
(5)はハードパース★。c1はVARCHAR2(2000), c2はVARCHAR2(128)でバインドされる。
(6)はハードパース★。c1はVARCHAR2(2000), c2はVARCHAR2(2000)でバインドされる。
(7)は(6)のカーソルが共有されソフトパース
1つのVARCHAR2カラムに対して、最大4つのバリエーションの子カーソルが発生する可能性があると考えると、4^カラム数だけの子カーソルが発生し、バインドミスマッチより組み合わせが増えるのではないかと考えてしまうかもしれない。しかし上記の動きから考えると、実際はアップグレードされたバッファサイズは大きくなる1方向であり、一度大きい型でバインドされればそれ以下の型でバインドされることはない。これは3x3の格子を左下から右上まで移動するのに経由した座標の数に等しいと考えると、3x2+1=7となる。したがって、一般的にはカラム数Nに対し、BIND_LENGTH_UPGRADEABLEにより発生する最大の子カーソル数はたかだか3N+1となる。カラム数の増加に対し、バインドミスマッチが如何に問題を引き起こしやすいか理解できるだろう。
また、BIND_LENGTH_UPGRADEABLEにより子カーソルが作られた場合、v$sql.IS_SHAREABLEが最新のものだけがYとなる。古い子カーソルは共有されることがないようすべてNとなり、優先的なパージ対象となることも特筆すべき点だろう。
SQL> select sql_id, child_number, last_load_time, is_shareable, sql_text from v$sql where sql_id='0hrt1s7pkz2qf' SQL_ID CHILD_NUMBER LAST_LOAD_TIME I SQL_TEXT ------------- ------------ -------------------- - ---------------------------------------- 0hrt1s7pkz2qf 0 2020-04-25/22:06:49 N UPDATE /* BINDTEST */ emp SET c2 = :1 , c3 = :2 , c4=:3 , c5=:4 WHERE c1 = :5 0hrt1s7pkz2qf 1 2020-04-25/22:06:49 N UPDATE /* BINDTEST */ emp SET c2 = :1 , c3 = :2 , c4=:3 , c5=:4 WHERE c1 = :5 0hrt1s7pkz2qf 2 2020-04-25/22:06:49 N UPDATE /* BINDTEST */ emp SET c2 = :1 , c3 = :2 , c4=:3 , c5=:4 WHERE c1 = :5 0hrt1s7pkz2qf 3 2020-04-25/22:06:49 N UPDATE /* BINDTEST */ emp SET c2 = :1 , c3 = :2 , c4=:3 , c5=:4 WHERE c1 = :5 0hrt1s7pkz2qf 4 2020-04-25/22:06:49 Y UPDATE /* BINDTEST */ emp SET c2 = :1 , c3 = :2 , c4=:3 , c5=:4 WHERE c1 = :5
◇バインドミスマッチの罪
以上のことから、バインドミスマッチの罪深さをまとめると、以下の通りである。
・カラム数Nに対し2^Nのオーダーで爆発的に子カーソルが増える
・ハードパースが多発し、大量の子カーソルの排他制御のため同時実行性が低下する
・すべての子カーソルでIS_SHAREABLEがYのためパージされにくい
・共有プールを無駄に使用する
・ハードパースや子カーソルの検索でCPUを消費する
・データバリエーション、多重度の組み合わせで遅延が顕在化するため、試験での検出や問題の再現が困難
・AP修正は概して広範囲にわたり、実質的に修正が困難
したがって、この問題を防ぐには適切なコーディン規約を作ることは言うまでもないが、それにも増して重要なのは、Oracleを使うJava技術者にこの事実を広く知っていただきたいということである。
そして冒頭で述べたように、どのようなフレームワークを用いるにしてもJavaでOracleを使う場合は、以下のことに注意することを心からお勧めする。
・DATE型カラムに対して(TIMESTAMP型でなく)DATE型でバインドすること
・NULL値の場合にカラムの型でバインドすること(setNullにjava.sql.Types.NULLを渡してはいけない)
以上
2020/5/25追記
今回、JDBCとiBatis・myBatisのJavaのフレームワーク経由でOracleに接続する場合のバインドミスマッチについて述べたが、アーキテクチャ上、他のJavaのフレームワークでも同様の事象は発生し得ると考えられる点、注意が必要だろう。
例えばnodes.jsのOracleのドライバは、DMLではDATE型やTIMESTAMP型をTIMESTAMP WITH LOCAL TIME ZONEとしてバインドする。小規模なプログラムでは問題ないだろうが、大規模な開発では意識しておく必要があるだろう。
参考:Working with Dates Using the Oracle Node.js Driver
逆にPro*CではDMLは一般的にVARCHARでバインドし、SQL側でTO_DATEするのが一般的であるため、この問題が発生するケースは稀と思われる。
参考:Pro*C/C++ Programmer's Guide 19c
以上
2020-04-27 04:31
SQLチューニングについて思うこと [オプティマイザ]
OracleのDBAとして永遠の課題と思っていることの一つにSQLの性能をどう担保していくべきか、という話があると思っている。今回は日ごろ感じている出口のないこの問題と、最近手にしたSQLチューニングの本でとても良い本があったので、紹介しておきたい。
1.はじめに
運用中のシステムでSQLの遅延が発生した際、実行計画の変化が原因のケースがある。多くは統計情報が最新化され、ハードパースが走った際にオプティマイザが実行計画を変更してしまう、というケースである。オプティマイザが良かれと思って実行計画を変更する訳であるが、不幸にも極端に性能が悪くなることが多々発生する。大規模システムにおいて、性能が極端に悪化するリスクは避けなければならない。このようなことから、多くの場合、以下の方法を複合的に採用することにより安定的な性能(すなわち変動しない実行計画)を(完全ではないにしろ)実現している。
(1)SQLにヒントを埋め込み、実行計画を固定化する
(2)統計情報の変動を抑えるために、統計をロックする
(3)SPM等の実行計画を管理する手法を使う
2.ヒントについて
説明するまでもないが、ヒントはSQL文の中に実行計画を指定するためのコメントを入れることにより、オプティマイザが設計者の意図したとおりの実行計画を選択し易いようにする構文である。多くの場合、駆動表や結合順、結合方法、使用する索引、パラレル度、などを指定するために利用される。これにより、統計情報がどのような状態にかかわらず、意図した実行計画に固定することが可能となる。
一見、これにより問題は解決するようであるが、この手法を積極的に採用するには以下の点で議論がある
・SQLにヒントを入れ、維持し続けるためのコスト(DBA体制の維持費)の問題
・SQLに非機能のロジックが埋め込まれることによるAP保守性低下の懸念(アップグレード時にヒント見直しなど)
・統計情報が適切に取得されていれば、オプティマイザはヒントなしでも良い実行計画が選択できる、という考え方の排除(Oracleの製品開発投資に対し高いライセンスを払っている訳で、それを活用していないのではないか)
従って、ヒントを入れるにしても実際はすべてのSQLにヒントを入れるのではなく、重要なSQLや運用中遅延が発生したSQLに限りいれているというところが多いのが実情だろう。
3.統計情報のロックについて
一方、統計をロックにより実行計画を安定化させる手法は、ヒントより間接的に実行計画を安定化させる方法である。これもシステムによってさまざまな方法があるが、概ね以下の3通りの手法があるだろう。
・ある時点の統計でロックする(特にテンポラリのテーブルなどゆらぎの大きいものなど)
・適当な値を設定(dbms_stats.set_table_stats等)しロックする
・NULL統計(デフォルト統計)としロックする
統計ロックは、ある時点の統計で統計情報をロックし、自動統計取得対象外とする手法である。これにより、統計情報がかわらないので、当然、オプティマイザの挙動は安定する。また、統計情報の取得にかかわるシステムの負荷を少なくできることは利点である。しかし、少し考えるといろいろな懸念があることがわかる。どの時点の統計でロックすべきか(本番環境の統計を正とすべきか、性能試験で実績の積んだテストデータの統計にするのか)。統計のリリース方法はどうするのか。カラム追加時の統計はどうするのか。日付や数値等のカラム統計は、ロックしてしまうと最大・最小値などのヒストグラムが実情に合わなくなるが、はたして問題ないのか、など懸念は尽きない。
適当な値を設定する方法は、NUM_ROWSやAVG_ROW_LENGTH,BLOKCS等をdbms_statsで設定する方法である。これは比較的容易に統計を設定することができ、かつ、DDLと一緒にリリースできるため、管理の容易である。しかし、どこまで設定するべきか、という議論となると、答えは難しい。結局、オプティマイザがどこまで設定すれば良いという答えは出ないため、管理の容易性を優先し、表の主要な統計のみを設定するにとどめるしかない。しかも、この手法はそもそもOracle非推奨である(dbms_statsパッケージの説明に記載されている)。
NULL統計は統計がNULL(欠落)しているときのデフォルトの挙動をあえて利用する手法である。実は統計NULLの場合は、テーブルのセグメントサイズ(HWM下ブロックサイズ)をベースに1行100バイトと仮定してNUM_ROWSを推定する。セレクティビティも同様に等価は0.01(索引アクセスなら0.004)、等価以外は0.05(索引アクセスなら0.009)等、決めうちの値をもとに推定するので、それなりの精度でオプティマイザは動いてくれる。しかし、セグメントサイズは動的に変更されるので、その意味でNULL統計ロックは統計をロックできていない。したがって、ハードパースのタイミングや再起動のタイミングで実行計画が変更してしまうことは十分起こりうる手法である。また、今は12cのマニュアルからNULL統計の記載がなくなった。内部的な挙動は今も同じらしいが、NULL統計の挙動についてサポートに問い合わせてもまともな回答が返ってこないことから、基本的に使わない方が良いだろう。
4.SPMについて
SPM(SQL Plan Management)とはSQLの実行計画を管理するための機能で、Oracle11gより提供されている(それまではプラン・スタビリティという機能があった)。SPMでは、SQLの実行計画を事前に保存(SQL計画ベースライン)しておき、SQLの実行計画が変動しないようにすることができる。
SPMの実態は内部的にはヒントの集合であり、それがSQL(正確にはSQL_ID)毎にOracle内部(SYSAUX)に格納されているに過ぎない。オプティマイザはハードパースの際に、このベースラインの実行計画とハッシュ値で比較し、一致していなければ格納されたヒントで再度ハードバースし、ベースラインの実行計画で実行する。このため、SPMではハードパースが2回実行されることとなる。
APに手の入れられない状況、例えばシステムの運用開始の直前や、パッケージ製品の内部SQLのチューニングであれば、SPMを用いて局所的な対処を行えることが有用であろう。逆に、システムの全業務SQLに対してSQL計画ベースラインで管理しようとすると、ヒントの代わりにこのベースラインを維持管理していく必要があるだろう。
5.結局どうしたらよいのか
Oracleのセミナ等では結局ケースバイケースです、といった結論で終わることが多い。しかし、安定した性能、ひいてはDBAの生活の質の向上を考えるなら、おのずと答えが見えてくる。SQL性能にまつわる多くの問題は実行計画の変動であることを考えれば、その変動する要因を極力取り除くことが有効であると考える。それは以下①~⑥の流れで発生することから、それぞれに対してブロックするような対策を考えてゆけばよい。
①データの変動→許容する
②自動統計→許容する
③統計情報が変更される
→上で述べた統計ロックの手法を採用し変更されないようにする
※特に一時テーブルや超大規模なテーブル等
④ライブラリキャッシュからエージアウト
→バインド変数を使うことを徹底する(コーディング規約等)
→共有プールに十分なメモリを確保する(shared_pool_size)
→カーソルをPIN(dbms_shared_pool.keep)しage outを防ぐ
⑤ハードパースが走る
→ヒントを使い、実行計画を明示的に指定する
→dynamic samplingは無効化し、サンプル統計取得による実行計画の変動を抑える
→12c新機能である適応問い合わせ最適化は停止(OPTIMIZER_ADAPTIVE_REPORTING_ONLY=TRUE)し、実行計画が変更されないようにする
→ハードパースが走っても実行計画が変動しないようSPMを採用する
⑥実行計画が変わる
6.最後はやはりヒント
しかし、上記のように対策したとしても、最後のチューニングはやはりヒントであろう。ヒントはSQLに埋めるため、局所的な対処が可能(他への影響をほとんど考慮する必要ない)ことから、唯一無二のチューニング方法となることが多い。また、ヒントには実行計画をかなり細かく記載することができるため、非常に強力である。しかし、それを正確に理解し、SQLに入れられるレベルにはかなり個人差があることを理解しておかなければならない。現場でいろいろなヒントを見るが、意図が不明なもの、中には間違ったものまであったりする(恐らくわかってはいるものの、そのためにAPを修正する訳にもいかず、ずっと残ってしまっている状態なのだろう)。
私の経験上、多くのSQLのチューニングで使用するのは、実行順を指定するORDERED,LEADING、結合方法を指定するUSE_NL, USE_HASH、索引を指定するINDEX、フルスキャンを指定するFULLくらいである。ヒントの使い方自体はそれ程難しいことはない。その一番難しいところは、あるべき実行計画をイメージする部分である。業務(APの開発者)であれば、直感的にどのテーブルから、どのような順番でアクセスすべきかイメージできるだろう。しかし、SQLと実行計画だけ渡されてチューニングするとなると、遅い原因はわかっても、あるべき結合順をイメージするのは難しいため、結局思考錯誤で対応することが多かった。
そんな中で出会ったのが、Kevin Meade氏のOracle SQL Performance Tuning and Optimization: Its all about the Cardinalitiesである。カーディナリティからSQLの結合順を導くFRP法(Filtered Rows Percentage Method)について記している。これは、クエリの実行計画の中で、常に処理する行数をできる限り少なく制御する、つまり、別の言葉でいうと、クエリの実行段階のできるだけ早い段階で、より多くの行を取り除く、という方法である。
基本的に、表の結合順をFilterによる絞り込み率が大きい順に並ぶように実行計画をチューニングするという考え方である。例えば3つの表があれば、結合順は6通りあるが、各表の絞り込み率が大きい(より絞り込みができる)表を駆動表に、その後は絞り込みができる順に表を結合していく。もちろん、実際は結合可能な表の順番に制約があるのでその制約を加味した上での話である。
この本の5章にヒントについての記載があるが、この思想が興味深い。そもそもヒントはチューニングの手段として考えるべきではなく、他の方法がどうしても有効でない場合に使うべきである、というのだ。つまり、ヒントは実行計画を強制するものではなく、オプティマイザが最適な実行計画を導き出すために何が問題で何を変更する必要があるのかを解析するためのツールとして認識すべきである、という見方である。また、SQLチューニングの3つの要素~カーディナリティ、駆動表と結合順、結合方法~を制御するため、ヒントの中で最も重要なもの3つは以下であると述べている。
・CARDINALITY / OPT_ESTIMEATE
・OREDERD / LEADING
・NO_INDEX
なお、本書の一章は無償で公開されている。ここに著者の提唱するFRPの具体的なやり方が記載されているので、一読の価値はあるだろう。また、本書の中で利用されているスクリプトもここからダウンロードできる。SQLチューニングの際に取得すべき情報は、チューニングを依頼する際にこれだけはそろえてほしい情報が記載されている。現場ではあいまいな情報だけで無茶な依頼が来ることもあるので、こういった基本事項を明文化しておくことは大切なことだと感じる。
http://www.orafaq.com/forum/m/624976
Oracle SQL Performance Tuning and Optimization v26 chapter 1.pdf
→本書の1章 駆動表と結合順 が読めます
scripts.rar
→本書の中で利用されているスクリプト一式
Information needed in Tuning a SQL Query.docx
→SQLチューニングの際に取得すべき情報
以上
◆参考

1.はじめに
運用中のシステムでSQLの遅延が発生した際、実行計画の変化が原因のケースがある。多くは統計情報が最新化され、ハードパースが走った際にオプティマイザが実行計画を変更してしまう、というケースである。オプティマイザが良かれと思って実行計画を変更する訳であるが、不幸にも極端に性能が悪くなることが多々発生する。大規模システムにおいて、性能が極端に悪化するリスクは避けなければならない。このようなことから、多くの場合、以下の方法を複合的に採用することにより安定的な性能(すなわち変動しない実行計画)を(完全ではないにしろ)実現している。
(1)SQLにヒントを埋め込み、実行計画を固定化する
(2)統計情報の変動を抑えるために、統計をロックする
(3)SPM等の実行計画を管理する手法を使う
2.ヒントについて
説明するまでもないが、ヒントはSQL文の中に実行計画を指定するためのコメントを入れることにより、オプティマイザが設計者の意図したとおりの実行計画を選択し易いようにする構文である。多くの場合、駆動表や結合順、結合方法、使用する索引、パラレル度、などを指定するために利用される。これにより、統計情報がどのような状態にかかわらず、意図した実行計画に固定することが可能となる。
一見、これにより問題は解決するようであるが、この手法を積極的に採用するには以下の点で議論がある
・SQLにヒントを入れ、維持し続けるためのコスト(DBA体制の維持費)の問題
・SQLに非機能のロジックが埋め込まれることによるAP保守性低下の懸念(アップグレード時にヒント見直しなど)
・統計情報が適切に取得されていれば、オプティマイザはヒントなしでも良い実行計画が選択できる、という考え方の排除(Oracleの製品開発投資に対し高いライセンスを払っている訳で、それを活用していないのではないか)
従って、ヒントを入れるにしても実際はすべてのSQLにヒントを入れるのではなく、重要なSQLや運用中遅延が発生したSQLに限りいれているというところが多いのが実情だろう。
3.統計情報のロックについて
一方、統計をロックにより実行計画を安定化させる手法は、ヒントより間接的に実行計画を安定化させる方法である。これもシステムによってさまざまな方法があるが、概ね以下の3通りの手法があるだろう。
・ある時点の統計でロックする(特にテンポラリのテーブルなどゆらぎの大きいものなど)
・適当な値を設定(dbms_stats.set_table_stats等)しロックする
・NULL統計(デフォルト統計)としロックする
統計ロックは、ある時点の統計で統計情報をロックし、自動統計取得対象外とする手法である。これにより、統計情報がかわらないので、当然、オプティマイザの挙動は安定する。また、統計情報の取得にかかわるシステムの負荷を少なくできることは利点である。しかし、少し考えるといろいろな懸念があることがわかる。どの時点の統計でロックすべきか(本番環境の統計を正とすべきか、性能試験で実績の積んだテストデータの統計にするのか)。統計のリリース方法はどうするのか。カラム追加時の統計はどうするのか。日付や数値等のカラム統計は、ロックしてしまうと最大・最小値などのヒストグラムが実情に合わなくなるが、はたして問題ないのか、など懸念は尽きない。
適当な値を設定する方法は、NUM_ROWSやAVG_ROW_LENGTH,BLOKCS等をdbms_statsで設定する方法である。これは比較的容易に統計を設定することができ、かつ、DDLと一緒にリリースできるため、管理の容易である。しかし、どこまで設定するべきか、という議論となると、答えは難しい。結局、オプティマイザがどこまで設定すれば良いという答えは出ないため、管理の容易性を優先し、表の主要な統計のみを設定するにとどめるしかない。しかも、この手法はそもそもOracle非推奨である(dbms_statsパッケージの説明に記載されている)。
NULL統計は統計がNULL(欠落)しているときのデフォルトの挙動をあえて利用する手法である。実は統計NULLの場合は、テーブルのセグメントサイズ(HWM下ブロックサイズ)をベースに1行100バイトと仮定してNUM_ROWSを推定する。セレクティビティも同様に等価は0.01(索引アクセスなら0.004)、等価以外は0.05(索引アクセスなら0.009)等、決めうちの値をもとに推定するので、それなりの精度でオプティマイザは動いてくれる。しかし、セグメントサイズは動的に変更されるので、その意味でNULL統計ロックは統計をロックできていない。したがって、ハードパースのタイミングや再起動のタイミングで実行計画が変更してしまうことは十分起こりうる手法である。また、今は12cのマニュアルからNULL統計の記載がなくなった。内部的な挙動は今も同じらしいが、NULL統計の挙動についてサポートに問い合わせてもまともな回答が返ってこないことから、基本的に使わない方が良いだろう。
4.SPMについて
SPM(SQL Plan Management)とはSQLの実行計画を管理するための機能で、Oracle11gより提供されている(それまではプラン・スタビリティという機能があった)。SPMでは、SQLの実行計画を事前に保存(SQL計画ベースライン)しておき、SQLの実行計画が変動しないようにすることができる。
SPMの実態は内部的にはヒントの集合であり、それがSQL(正確にはSQL_ID)毎にOracle内部(SYSAUX)に格納されているに過ぎない。オプティマイザはハードパースの際に、このベースラインの実行計画とハッシュ値で比較し、一致していなければ格納されたヒントで再度ハードバースし、ベースラインの実行計画で実行する。このため、SPMではハードパースが2回実行されることとなる。
APに手の入れられない状況、例えばシステムの運用開始の直前や、パッケージ製品の内部SQLのチューニングであれば、SPMを用いて局所的な対処を行えることが有用であろう。逆に、システムの全業務SQLに対してSQL計画ベースラインで管理しようとすると、ヒントの代わりにこのベースラインを維持管理していく必要があるだろう。
5.結局どうしたらよいのか
Oracleのセミナ等では結局ケースバイケースです、といった結論で終わることが多い。しかし、安定した性能、ひいてはDBAの生活の質の向上を考えるなら、おのずと答えが見えてくる。SQL性能にまつわる多くの問題は実行計画の変動であることを考えれば、その変動する要因を極力取り除くことが有効であると考える。それは以下①~⑥の流れで発生することから、それぞれに対してブロックするような対策を考えてゆけばよい。
①データの変動→許容する
②自動統計→許容する
③統計情報が変更される
→上で述べた統計ロックの手法を採用し変更されないようにする
※特に一時テーブルや超大規模なテーブル等
④ライブラリキャッシュからエージアウト
→バインド変数を使うことを徹底する(コーディング規約等)
→共有プールに十分なメモリを確保する(shared_pool_size)
→カーソルをPIN(dbms_shared_pool.keep)しage outを防ぐ
⑤ハードパースが走る
→ヒントを使い、実行計画を明示的に指定する
→dynamic samplingは無効化し、サンプル統計取得による実行計画の変動を抑える
→12c新機能である適応問い合わせ最適化は停止(OPTIMIZER_ADAPTIVE_REPORTING_ONLY=TRUE)し、実行計画が変更されないようにする
→ハードパースが走っても実行計画が変動しないようSPMを採用する
⑥実行計画が変わる
6.最後はやはりヒント
しかし、上記のように対策したとしても、最後のチューニングはやはりヒントであろう。ヒントはSQLに埋めるため、局所的な対処が可能(他への影響をほとんど考慮する必要ない)ことから、唯一無二のチューニング方法となることが多い。また、ヒントには実行計画をかなり細かく記載することができるため、非常に強力である。しかし、それを正確に理解し、SQLに入れられるレベルにはかなり個人差があることを理解しておかなければならない。現場でいろいろなヒントを見るが、意図が不明なもの、中には間違ったものまであったりする(恐らくわかってはいるものの、そのためにAPを修正する訳にもいかず、ずっと残ってしまっている状態なのだろう)。
私の経験上、多くのSQLのチューニングで使用するのは、実行順を指定するORDERED,LEADING、結合方法を指定するUSE_NL, USE_HASH、索引を指定するINDEX、フルスキャンを指定するFULLくらいである。ヒントの使い方自体はそれ程難しいことはない。その一番難しいところは、あるべき実行計画をイメージする部分である。業務(APの開発者)であれば、直感的にどのテーブルから、どのような順番でアクセスすべきかイメージできるだろう。しかし、SQLと実行計画だけ渡されてチューニングするとなると、遅い原因はわかっても、あるべき結合順をイメージするのは難しいため、結局思考錯誤で対応することが多かった。
そんな中で出会ったのが、Kevin Meade氏のOracle SQL Performance Tuning and Optimization: Its all about the Cardinalitiesである。カーディナリティからSQLの結合順を導くFRP法(Filtered Rows Percentage Method)について記している。これは、クエリの実行計画の中で、常に処理する行数をできる限り少なく制御する、つまり、別の言葉でいうと、クエリの実行段階のできるだけ早い段階で、より多くの行を取り除く、という方法である。
基本的に、表の結合順をFilterによる絞り込み率が大きい順に並ぶように実行計画をチューニングするという考え方である。例えば3つの表があれば、結合順は6通りあるが、各表の絞り込み率が大きい(より絞り込みができる)表を駆動表に、その後は絞り込みができる順に表を結合していく。もちろん、実際は結合可能な表の順番に制約があるのでその制約を加味した上での話である。
この本の5章にヒントについての記載があるが、この思想が興味深い。そもそもヒントはチューニングの手段として考えるべきではなく、他の方法がどうしても有効でない場合に使うべきである、というのだ。つまり、ヒントは実行計画を強制するものではなく、オプティマイザが最適な実行計画を導き出すために何が問題で何を変更する必要があるのかを解析するためのツールとして認識すべきである、という見方である。また、SQLチューニングの3つの要素~カーディナリティ、駆動表と結合順、結合方法~を制御するため、ヒントの中で最も重要なもの3つは以下であると述べている。
・CARDINALITY / OPT_ESTIMEATE
・OREDERD / LEADING
・NO_INDEX
なお、本書の一章は無償で公開されている。ここに著者の提唱するFRPの具体的なやり方が記載されているので、一読の価値はあるだろう。また、本書の中で利用されているスクリプトもここからダウンロードできる。SQLチューニングの際に取得すべき情報は、チューニングを依頼する際にこれだけはそろえてほしい情報が記載されている。現場ではあいまいな情報だけで無茶な依頼が来ることもあるので、こういった基本事項を明文化しておくことは大切なことだと感じる。
http://www.orafaq.com/forum/m/624976
Oracle SQL Performance Tuning and Optimization v26 chapter 1.pdf
→本書の1章 駆動表と結合順 が読めます
scripts.rar
→本書の中で利用されているスクリプト一式
Information needed in Tuning a SQL Query.docx
→SQLチューニングの際に取得すべき情報
以上
◆参考
Oracle SQL Performance Tuning and Optimization: It's All About the Cardinalities
- 作者: Kevin Meade
- 出版社/メーカー: Createspace Independent Pub
- 発売日: 2014/09/16
- メディア: ペーパーバック
direct path readを強制するHINTについて [オプティマイザ]
最近特に寒い。相変わらずExadataの性能遅延と戦っている。
以前direct path readについて記事を書いたが、その続きを記載する。
現実逃避がてら、Oracle Communityでダイレクトパスリードを指定するHINTの導入をアイディアとして投稿してみた。
hint to enforce FULL SCAN with direct path read
https://community.oracle.com/ideas/23746
---
Parallel hint can be used for enforcing direct path read, but there's no hint for serial direct path read.
Serial direct path read is hard to control; it depends on several factors such as;
- FULL SCAN
- segment size and buffer cache size
- the num of blocks cached on buffer cache
Besides, the above logic is not written in manual and different from version to version.
So I would like to propose adding a hint like "FULL_DIRECT_PATH( emp )" to enforce FULL SCAN with direct path read.
This could be not only used to enforce optimizer serial direct path read but also ensuring smart scan on Exadata.
----
Oracle ACEの方からは早速このアイディアに対して_serial_direct_readパラメータがあるのにHINTいるの?というツッコミを貰った。確かに以下のようにセッションレベルで変更できる。
alter session set "_serial_direct_read"=always;
ただ、もしHINTがあったとすれば、以下のようなメリットがあるのでは?とコメントした。
・セッションレベルでなくSQLレベルで制御できること
・複数の表を結合する場合、特定の表だけを指定することができる
・きちんとマニュアルに記載される(隠しパラメータはMOSだけ)
なお、1点目に関してはopt_param('_serial_direct_read','always') が使えれば解決する。しかし、私の手元の環境(12.2)ではなぜかうまく動いてくれなかった。指定の仕方が良くないのかもしれないが原因不明のままである。
このアイディアに対しては、今のところこのOracle ACEの方からのみの投票。仕組みがよくわかってないのだが、投票は+10ポイント、否決票は-10ポイントという形で投票していくようである。トップアイディア見ると6,000ポイント以上集まっているが、これがたまっていくと、将来もしかすると機能拡張されたりするのか?と思うと少しモチベーションがあがる。
といっても、今20ポイントなので、見込み薄ではあるが。
以上
以前direct path readについて記事を書いたが、その続きを記載する。
現実逃避がてら、Oracle Communityでダイレクトパスリードを指定するHINTの導入をアイディアとして投稿してみた。
hint to enforce FULL SCAN with direct path read
https://community.oracle.com/ideas/23746
---
Parallel hint can be used for enforcing direct path read, but there's no hint for serial direct path read.
Serial direct path read is hard to control; it depends on several factors such as;
- FULL SCAN
- segment size and buffer cache size
- the num of blocks cached on buffer cache
Besides, the above logic is not written in manual and different from version to version.
So I would like to propose adding a hint like "FULL_DIRECT_PATH( emp )" to enforce FULL SCAN with direct path read.
This could be not only used to enforce optimizer serial direct path read but also ensuring smart scan on Exadata.
----
Oracle ACEの方からは早速このアイディアに対して_serial_direct_readパラメータがあるのにHINTいるの?というツッコミを貰った。確かに以下のようにセッションレベルで変更できる。
alter session set "_serial_direct_read"=always;
ただ、もしHINTがあったとすれば、以下のようなメリットがあるのでは?とコメントした。
・セッションレベルでなくSQLレベルで制御できること
・複数の表を結合する場合、特定の表だけを指定することができる
・きちんとマニュアルに記載される(隠しパラメータはMOSだけ)
なお、1点目に関してはopt_param('_serial_direct_read','always') が使えれば解決する。しかし、私の手元の環境(12.2)ではなぜかうまく動いてくれなかった。指定の仕方が良くないのかもしれないが原因不明のままである。
このアイディアに対しては、今のところこのOracle ACEの方からのみの投票。仕組みがよくわかってないのだが、投票は+10ポイント、否決票は-10ポイントという形で投票していくようである。トップアイディア見ると6,000ポイント以上集まっているが、これがたまっていくと、将来もしかすると機能拡張されたりするのか?と思うと少しモチベーションがあがる。
といっても、今20ポイントなので、見込み薄ではあるが。
以上
今さらsort_area_sizeについて考えさせられる [オプティマイザ]
先日12.2でソートの実行計画がおかしいという話を聞いて調べてみたときのこと。前のシステム(11.1)ではメモリソートをする実行計画だったのに、12.2ではなぜかソート列に張られている主キーの索引をフルスキャンしテーブルアクセスする実行計画になっていた。SQLはこんなイメージ。
select * from emp where hiredate=to_date('20181001','YYYYMMDD') order by empno;
※主キーemp_pkはempnoに張られている状況
前者の実行計画は表のマルチブロックリード(hiredateで絞り込み)+結果セットのメモリソートなので高速、後者は索引のマルチブロックリード(全件)+表シングルブロックリード(hiredateで絞込み)ということで、後者の方がかなり遅かった。
/*+ FULL(emp) */ ヒント句をつければ確かに速くなったのだが、問題はなぜ12.2のオプティマイザは後者の実行計画を選択したか、という点であった。なお、前提としては、表の統計はなし(NULL統計でロック)、テーブルに格納するデータは同じ(レコード数も同じ)である。
そこで10053トレースを取得してみて調べてみた。10053トレースはオプティマイザのコスト計算のトレースであり、複数ある実行計画のコストをどう計算し、最終的な実行計画を導いたかがわかる。ここから、12.2のオプティマイザはソートのコストを極めて高く見積もっていることがわかった。それは、メモリソートに収まるサイズが1MBとなっており、ソートスピルのためにtemp表領域にI/Oが発生するコストとなっていたからだった。なお、11.1ではpga_aggregate_target(PAT)を使わず、sort_area_sizeを明示的により大きく(32MB)設定していたため、メモリソートに収まるため、コストが低く見積もられていた。
PATはセッション毎の最大ソート領域は自動チューニングのため、個別セッションのソート領域を通常意識する必要はないと思っていた。実際、セッション毎の最大ソートサイズは_smm_max_sizeで決定し、これはお概ねPATのサイズに比例して大きくなる。しかし、オプティマイザのソートコスト計算での前提となるメモリサイズはセッション毎の最小ソートサイズ(_smm_min_size)であり、どうやらこの最大値は1MBであるらしい。つまり、どれだけPATを大きくしても、オプティマイザのコスト計算上はsort_area_size=1MB相当となってしまう。最大ソートサイズまでPGAは利用できるのに、コスト計算上はこれが考慮されず、必然的にソートコストが高めに計算される、という訳だ。
結局、_smm_min_sizeを前システムのsort_area_sizeの値に設定し、オプティマイザのコスト計算を従来と同様にする対処をすることとした。いまどき新規で作る際PATを使わない、という選択はあまりしないと思うが、もしupgradeなどでPATを使い始める際には、実行計画を安定させる上でこの点の考慮が有用かもしれない。
なお、このソート周りのオプティマイザのコスト計算を理解する上で非常に有用だったのが、Jonathan Lewis氏のCost-Based Oracle Fundamentalsである。これ以上、オラクルのコストについて熱く(厚く)書かれた書籍を私は知らない。残念ながら12cの話は含まれていないが、それでもなお、基本的な考え方は変わっておらず、オプティマイザに関しては私のバイブル的な本である。
")
select * from emp where hiredate=to_date('20181001','YYYYMMDD') order by empno;
※主キーemp_pkはempnoに張られている状況
前者の実行計画は表のマルチブロックリード(hiredateで絞り込み)+結果セットのメモリソートなので高速、後者は索引のマルチブロックリード(全件)+表シングルブロックリード(hiredateで絞込み)ということで、後者の方がかなり遅かった。
/*+ FULL(emp) */ ヒント句をつければ確かに速くなったのだが、問題はなぜ12.2のオプティマイザは後者の実行計画を選択したか、という点であった。なお、前提としては、表の統計はなし(NULL統計でロック)、テーブルに格納するデータは同じ(レコード数も同じ)である。
そこで10053トレースを取得してみて調べてみた。10053トレースはオプティマイザのコスト計算のトレースであり、複数ある実行計画のコストをどう計算し、最終的な実行計画を導いたかがわかる。ここから、12.2のオプティマイザはソートのコストを極めて高く見積もっていることがわかった。それは、メモリソートに収まるサイズが1MBとなっており、ソートスピルのためにtemp表領域にI/Oが発生するコストとなっていたからだった。なお、11.1ではpga_aggregate_target(PAT)を使わず、sort_area_sizeを明示的により大きく(32MB)設定していたため、メモリソートに収まるため、コストが低く見積もられていた。
PATはセッション毎の最大ソート領域は自動チューニングのため、個別セッションのソート領域を通常意識する必要はないと思っていた。実際、セッション毎の最大ソートサイズは_smm_max_sizeで決定し、これはお概ねPATのサイズに比例して大きくなる。しかし、オプティマイザのソートコスト計算での前提となるメモリサイズはセッション毎の最小ソートサイズ(_smm_min_size)であり、どうやらこの最大値は1MBであるらしい。つまり、どれだけPATを大きくしても、オプティマイザのコスト計算上はsort_area_size=1MB相当となってしまう。最大ソートサイズまでPGAは利用できるのに、コスト計算上はこれが考慮されず、必然的にソートコストが高めに計算される、という訳だ。
結局、_smm_min_sizeを前システムのsort_area_sizeの値に設定し、オプティマイザのコスト計算を従来と同様にする対処をすることとした。いまどき新規で作る際PATを使わない、という選択はあまりしないと思うが、もしupgradeなどでPATを使い始める際には、実行計画を安定させる上でこの点の考慮が有用かもしれない。
なお、このソート周りのオプティマイザのコスト計算を理解する上で非常に有用だったのが、Jonathan Lewis氏のCost-Based Oracle Fundamentalsである。これ以上、オラクルのコストについて熱く(厚く)書かれた書籍を私は知らない。残念ながら12cの話は含まれていないが、それでもなお、基本的な考え方は変わっておらず、オプティマイザに関しては私のバイブル的な本である。
Cost-Based Oracle Fundamentals (Expert's Voice in Oracle)
- 作者: Jonathan Lewis
- 出版社/メーカー: Apress
- 発売日: 2007/03/15
- メディア: ペーパーバック
direct path readについて思うこと [オプティマイザ]
Exadataを使い始めたのは2014年、X4-2からだ。当初はOracleに毛が生えたもの程度にしか思っていなかった。しかし、使い込んでいくうちに、DB層の下のストレージサーバ層に独自の機能が作りこまれていることがだんだんわかってきた。これを知ったのはExpert Oracle Exadata[1]という一冊の本に出会ってからである。
この本は英語でかなり厚く、お値段もそれなりにするので敷居が高いが、Exadataの内部動作をここまで紐解いてわかりやすく説明している点は他に類を見ない。もっと早くこの本に出会っていれば、よりExadataを有効活用し、トラブル対応も違った形でできたのではという忸怩たる思いがある。
さて、この本を読み進める中でわかったのは、Exadataを使う(使いこなす)上での一つのポイントが、direct path readである、ということである。ご存知の通りdirect path readとはバッファキャッシュをバイパスしてストレージ上のブロックをサーバプロセスのPGAに読み込むことで、フルスキャンなどのマルチブロックを高速に実現する方法である。もともとパラレルクエリのメカニズムであったが、11gからシリアルクエリでもdirect path readが使えるようになった。
なぜdirect path readがExadataにおいて重要なのか?スマートスキャンなど、ストレージからDBサーバのブロック転送量を減らす仕組み(具体的にはpredicate filteringやcolumn projection、storage indexなどを指す)が有効になるのは、すべてdirect path readであることが前提となる。Exadataのスマートスキャンが有効となるのは、以下の3つの条件がすべて揃わなければならない。
1.セグメントのフルスキャンであること
2.direct path readであること
3.オブジェクトはExadataに格納されていること
上記のうち、1は実行計画を確認すれば簡単にわかるだろう。3も環境により自明であることが多い。しかし、2については一番わかりにくい。なぜなら、direct path readの発動条件が公開されておらず、また、Oracleのバージョンによってロジックが異なるためである。少なくとも、条件としては、バッファキャッシュのサイズとオブジェクトのサイズ、バッファキャッシュに乗っているオブジェクトのブロック数が関係しているといわれる。
例えば、私の利用している環境(Exadata X7-2/Oracle12.2.0.1)では、セグメントサイズがバッファキャッシュの約2%を超えるとdirect path readが発生し始めることを確認している。このため、Oracle社の技術資料の中にはスマートスキャンを使うためにはパラレルヒントを入れることを促す資料があるほどである。嘘ではないが若干荒っぽいチューニング手法であると個人的には思う。
direct path readが発生していることは実行計画からは判別ができない。このため、一般的にはSQLトレース(10046トレース)を確認することが確実だろう。あるいは、セッション統計(v$sesstat, v$mystat)の統計の変化を確認することも有効だろう。いずれにしても本番環境で確認するのはいささかハードルが高い。
direct path readのデメリットといえば、バッファキャッシュに乗らないため、毎回ストレージに負荷がかかる点である。特にアクセス頻度が高いSQLではストレージサーバ側の負荷に注意が必要だろう。
例えば、ある表に対するHASH結合をプロセス多重で実行するようなケースを考えてみよう。HASH結合ではフルスキャンが走るため、上記条件を満たせばdirect path readとなり、Exadataではスマートスキャンによるストレージサーバへのオフロード機能の恩恵を受けられる。しかし、これを多重で実行すると、バッファキャッシュに乗らないため、ストレージサーバへ負荷が集中することとなる。このような場合は、あえてdirect path readを実行されないような考慮が必要かもしれない(具体的にはセッションレベルで_serinal_direct_readをNEVERにするなど)。
また、経年でセグメントサイズが増加するようなテーブルでは、DBサーバ再起動後からdirect path readに切り替わってしまうということが起きうる。これは、バッファキャッシュ上にセグメントブロックがある程度乗っているうちは、direct path readは発生しないという特性による。運用中にセグメントが閾値(具体的には_small_table_thresholdのブロック数から導出される閾値)を超え、インスタンス再起動によりバッファキャッシュがクリアされると途端にdirect path readになってしまい、ストレージサーバの負荷が高くなるという事象が起こりうる。性能が向上すればよいが、ストレージサーバの負荷によっては性能劣化を引き起こす可能性があるため、このような特性は理解しておく必要がある。
参考文献:[1]Expert Oracle Exadata

この本は英語でかなり厚く、お値段もそれなりにするので敷居が高いが、Exadataの内部動作をここまで紐解いてわかりやすく説明している点は他に類を見ない。もっと早くこの本に出会っていれば、よりExadataを有効活用し、トラブル対応も違った形でできたのではという忸怩たる思いがある。
さて、この本を読み進める中でわかったのは、Exadataを使う(使いこなす)上での一つのポイントが、direct path readである、ということである。ご存知の通りdirect path readとはバッファキャッシュをバイパスしてストレージ上のブロックをサーバプロセスのPGAに読み込むことで、フルスキャンなどのマルチブロックを高速に実現する方法である。もともとパラレルクエリのメカニズムであったが、11gからシリアルクエリでもdirect path readが使えるようになった。
なぜdirect path readがExadataにおいて重要なのか?スマートスキャンなど、ストレージからDBサーバのブロック転送量を減らす仕組み(具体的にはpredicate filteringやcolumn projection、storage indexなどを指す)が有効になるのは、すべてdirect path readであることが前提となる。Exadataのスマートスキャンが有効となるのは、以下の3つの条件がすべて揃わなければならない。
1.セグメントのフルスキャンであること
2.direct path readであること
3.オブジェクトはExadataに格納されていること
上記のうち、1は実行計画を確認すれば簡単にわかるだろう。3も環境により自明であることが多い。しかし、2については一番わかりにくい。なぜなら、direct path readの発動条件が公開されておらず、また、Oracleのバージョンによってロジックが異なるためである。少なくとも、条件としては、バッファキャッシュのサイズとオブジェクトのサイズ、バッファキャッシュに乗っているオブジェクトのブロック数が関係しているといわれる。
例えば、私の利用している環境(Exadata X7-2/Oracle12.2.0.1)では、セグメントサイズがバッファキャッシュの約2%を超えるとdirect path readが発生し始めることを確認している。このため、Oracle社の技術資料の中にはスマートスキャンを使うためにはパラレルヒントを入れることを促す資料があるほどである。嘘ではないが若干荒っぽいチューニング手法であると個人的には思う。
direct path readが発生していることは実行計画からは判別ができない。このため、一般的にはSQLトレース(10046トレース)を確認することが確実だろう。あるいは、セッション統計(v$sesstat, v$mystat)の統計の変化を確認することも有効だろう。いずれにしても本番環境で確認するのはいささかハードルが高い。
direct path readのデメリットといえば、バッファキャッシュに乗らないため、毎回ストレージに負荷がかかる点である。特にアクセス頻度が高いSQLではストレージサーバ側の負荷に注意が必要だろう。
例えば、ある表に対するHASH結合をプロセス多重で実行するようなケースを考えてみよう。HASH結合ではフルスキャンが走るため、上記条件を満たせばdirect path readとなり、Exadataではスマートスキャンによるストレージサーバへのオフロード機能の恩恵を受けられる。しかし、これを多重で実行すると、バッファキャッシュに乗らないため、ストレージサーバへ負荷が集中することとなる。このような場合は、あえてdirect path readを実行されないような考慮が必要かもしれない(具体的にはセッションレベルで_serinal_direct_readをNEVERにするなど)。
また、経年でセグメントサイズが増加するようなテーブルでは、DBサーバ再起動後からdirect path readに切り替わってしまうということが起きうる。これは、バッファキャッシュ上にセグメントブロックがある程度乗っているうちは、direct path readは発生しないという特性による。運用中にセグメントが閾値(具体的には_small_table_thresholdのブロック数から導出される閾値)を超え、インスタンス再起動によりバッファキャッシュがクリアされると途端にdirect path readになってしまい、ストレージサーバの負荷が高くなるという事象が起こりうる。性能が向上すればよいが、ストレージサーバの負荷によっては性能劣化を引き起こす可能性があるため、このような特性は理解しておく必要がある。
参考文献:[1]Expert Oracle Exadata
- 作者: Martin Bach
- 出版社/メーカー: Apress
- 発売日: 2015/08/28
- メディア: ペーパーバック


