DBのCPUサイジングについての一考察 [アーキテクチャ]
はじめに
DBサーバにどの程度のCPUが必要かを見積りしなければならない状況はよくある。
基盤更改の場合は、現行のシステムがあり、そのHWスペックもリソース状況もわかっているので、CPUの性能比から概ね精度の高い見積もりが可能である。しかし、全く新規業務の場合は、机上でどの程度のCPUが必要かを導くことは難しい。しかも、業務仕様や処理方式が決まっていない状況ではなおさらである。このような場合、想定する処理方式に対する性能の基礎数値が重要となる。
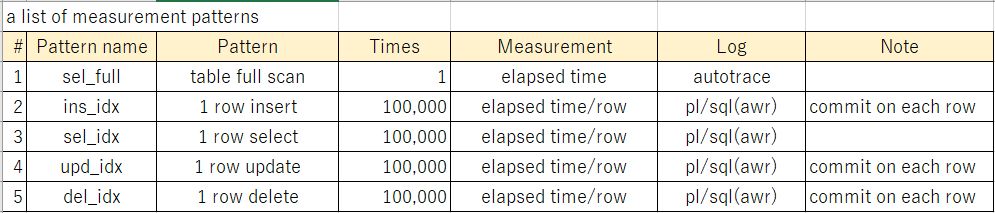
本稿では、DBの基礎的な処理(INSERT, SELECT, UPDATE, DELETE)の基礎数値を取得する簡単なモデルと処理(PL/SQL)を、OCIの環境で実測し、その結果を考察してみたい。なお、性能の結果は環境によって変わるので、あくまで参考程度と考えてほしい。
1.性能モデル
性能モデルとして、3つの表、b10tbl, b50tbl, b100tblを考える。
idカラムをnumber型の主キーとし、1からの連番を振る。dtカラムはdate型で、更新日時を入れる。col1~colnはvarchar2(10)のカラムで、b10tblは1個、b50tblは5個、b100tblは10個とし、ランダムな文字列を10バイト挿入する。初期データ件数は100万件とする。
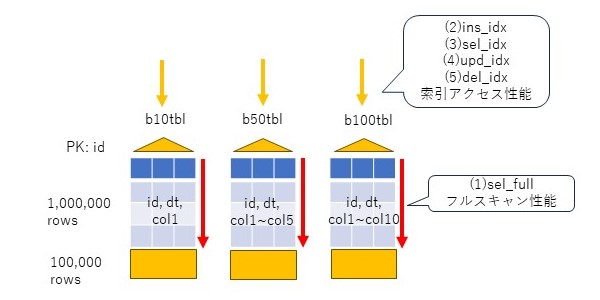
この表に対して、以下のパタンで基礎性能値を確認する。1番目はselectのフルスキャン、2~5番目は索引アクセスのパタン(insert、select、update、delete)である。索引アクセスは10万回行う。
2.表(データ)の準備
表を作成するDDLは以下の通り。
drop table b10tbl cascade constraints; create table b10tbl( id number(7), dt date, col1 varchar2(10), constraint pk_b10tbl primary key (id) ); drop table b50tbl cascade constraints; create table b50tbl( id number(7), dt date, col1 varchar2(10), col2 varchar2(10), col3 varchar2(10), col4 varchar2(10), col5 varchar2(10), constraint pk_b50tbl primary key (id) ); drop table b100tbl cascade constraints; create table b100tbl( id number(7), dt date, col1 varchar2(10), col2 varchar2(10), col3 varchar2(10), col4 varchar2(10), col5 varchar2(10), col6 varchar2(10), col7 varchar2(10), col8 varchar2(10), col9 varchar2(10), col10 varchar2(10), constraint pk_b100tbl primary key (id) );
初期データを挿入する。
insert into b10tbl select
rownum id,
sysdate dt,
dbms_random.string('x',10) col1
from dual connect by level <=1000000;
commit;
insert into b50tbl select
rownum id,
sysdate dt,
dbms_random.string('x',10) col1,
dbms_random.string('x',10) col2,
dbms_random.string('x',10) col3,
dbms_random.string('x',10) col4,
dbms_random.string('x',10) col5
from dual connect by level <=1000000;
commit;
insert into b100tbl select
rownum id,
sysdate dt,
dbms_random.string('x',10) col1,
dbms_random.string('x',10) col2,
dbms_random.string('x',10) col3,
dbms_random.string('x',10) col4,
dbms_random.string('x',10) col5,
dbms_random.string('x',10) col6,
dbms_random.string('x',10) col7,
dbms_random.string('x',10) col8,
dbms_random.string('x',10) col9,
dbms_random.string('x',10) col10
from dual connect by level <=1000000;
commit;
統計情報を取得する。
exec dbms_stats.gather_table_stats('scott','b10tbl');
exec dbms_stats.gather_table_stats('scott','b50tbl');
exec dbms_stats.gather_table_stats('scott','b100tbl');
作成した表のサイズを確認する。
col segment_name for a20 select segment_name, sum(bytes)/1024/1024 mb from user_segments where segment_name like '%B%TBL' group by segment_name order by 1;
3.測定
フルスキャン性能については、シンプルにautotraceの処理時間を想定する。select *としたのは、フルスキャンに主キーの索引が使われないにするためである。以下はb10tblの例である。
set timi on set autotrace traceonly select * from b10tbl; set autotrace off
INSERT性能は、PL/SQLで100万件の状態から10万件を追加する。この際、dtには更新日時、colxにはdbms_randomでランダムな文字列を生成して設定する。以下の例はb10tblなので、col1カラムだけであるが、b50tblでは5カラム、b100tblでは10カラム分、ランダムな文字列を生成し設定する。また、コミットは1件毎に実施する。
declare
i number;
begin
for i in 1000001..1100000 loop
insert into b10tbl values(i,sysdate,dbms_random.string('x',10));
commit;
end loop;
end;
/
SELECT性能は、同様にPL/SQLで、INSERTで積まれた10万件に対して、主キー一本引きのSQLを発行する。以下の例はb10tblなので、col1カラムだけであるが、b50tblでは5カラム、b100tblでは10カラム分、カラムを取得する。
declare i number; l_col1 varchar2(10); begin for i in 1000001..1100000 loop select col1 into l_col1 from b10tbl where id=i; end loop; end; /
SELECT性能は、同様にPL/SQLで、INSERTで積まれた10万件に対して、主キー一本引きでUPDATEを発行する。この際、dtには更新日時、colxにはdbms_randomでランダムな文字列を生成して設定する。以下の例はb10tblなので、col1カラムだけであるが、b50tblでは5カラム、b100tblでは10カラム分、ランダムな文字列を生成し設定する。コミットは1件毎に実施する。
declare
i number;
begin
for i in 1..100000 loop
update b10tbl set dt=sysdate,col1=dbms_random.string('u',10) where id=1000000+i;
commit;
end loop;
end;
/
DELETE性能は、同様にPL/SQLで、INSERTで積まれた10万件に対して、主キー一本引きのDELETEを発行する。コミットは1件毎に実施する。
declare i number; begin for i in 1000001..1100000 loop delete from b10tbl where id=i; commit; end loop; end; /
4.測定環境
上記のモデルを実際にOCIのBaseDBを利用して測定する。環境は以下の通り。
Shape: VM.Standard.E4.Flex CPU core count: 2 Oracle Database software edition: Enterprise Edition High Performance Storage management software: Oracle Grid Infrastructure Available data storage: 256 GB Recovery area storage: 256 GB Total storage size: 712 GB Theoretical max IOPS: 19.2K DB system version: 19.20.0.0.0
メモリの状態は以下の通り。SGAは14.5GB、そのうちバッファキャッシュは12GBである。
Memory Statistics
~~~~~~~~~~~~~~~~~ Begin End
------------ ------------
Host Mem (MB): 31,893.9 31,893.9
SGA use (MB): 14,848.0 14,848.0
PGA use (MB): 1,084.4 1,106.1
% Host Mem used for SGA+PGA: 49.95 50.02
Database Resource Limits
~~~~~~~~~~~~~~~~~~~~~~~~ Begin End
---------------- ----------------
CPUs: 4 4
SGA Target: 15,569,256,448 15,569,256,448
PGA Target: 3,892,314,112 3,892,314,112
Memory Target: 0 0
Cache Sizes Begin End
~~~~~~~~~~~ ---------- ----------
Buffer Cache: 12,352M 12,352M Std Block Size: 8K
Shared Pool Size: 1,405M 1,404M Log Buffer: 154,872K
In-Memory Area: 0M 0M
上記の方法でデータを作成したところ、以下のサイズ(表と索引)となった。合計でたかだか338MBなので、全てバッファキャッシュに十分収まる。
SEGMENT_NAME MB -------------------- ---------- B100TBL 157 B10TBL 36 B50TBL 94 PK_B100TBL 17 PK_B10TBL 17 PK_B50TBL 17
5.測定結果
下表に測定結果を示す。rowsは処理件数、elapsed(ms)は処理の経過時間を示す。1番目のsel_fullはautotraceの経過時間、その他2~5番目はSQLレポート上の経過時間を示す。ms/rowは、1件あたりの処理時間を示す。例えばsel_fullであれば100万件の処理時間を100万で割った数値、sel_idxであれば、10万件の処理時間を10万で割った数値を示す。tpsは1をms/rowで割った値で、単位時間(1秒)あたりの処理件数を示す。

なお、参考[1]に、測定結果とあわせて、AWRレポート、SQLレポートをまとめたexcelシートを載せているので、詳細に興味があればそちらを確認頂きたい。
6.考察
フルスキャンはカラム長が長くなるほどに処理時間が延びる。カラム長が長いと参照ブロック数が増えることになるので、当然だろう。表と索引はバッファキャッシュに乗っているため、処理時間にIOは含まれていない数字と理解する必要がある。
SELECTはカラム数が増えるとじわりと処理時間が伸びていることがわかる。SQLレポートのGetsを見る限り、SELECTは4ブロック/件の論理ブロック読み込みをしていた。索引に3ブロック(BLEVEL=2)、表に1ブロックの読み込みをしていると推測される。通常の索引はBLEVEL=3位になっていることが多いので、少し軽めな索引アクセスと理解する必要がある。
INSERTとUPDATEはほぼおなじ程度の処理単価となっている。カラム増加に対する処理時間の傾向もほぼ同じである。SQLレポートのGetsを見る限り、INSERTは5ブロック/件、UPDATEは6ブロック/件の論理ブロック読み込みをしていた。このうち4ブロックは更新ブロックの特定に使われているはずなので、残りが純粋な更新に必要なUNDO関連のブロック数と思われる。カラム増加による処理時間の伸びが顕著なのは、dbms_randomの呼び出し回数の影響が大きいかもしれない。純粋なDMLの処理時間を確認する意味では、関数を含めない方が良かったかもしれない。
DELETEはカラム数の増加の影響はかなり限定的に見える。SQLレポートのGetsを見る限り、8ブロック/件の論理ブロック読み込みをしていた。これも4ブロックは更新ブロックの特定に使われているはずで、残りがDELETEに必要なUNDO関連のブロックなのだろう。更新よりブロック数が多いのは、索引の更新に伴うものかもしれない(削除に伴い、索引のB*Treeおよびリーフブロックの更新が必要)。
単位時間あたりのトランザクション数(tps)については、総じてSQLの性能は、DMLより一桁は速い。INSERTやUPDATEで、b10tblで18倍、b100tblで40倍もの差がある。DELETEは比較的軽いが、それでも10倍程度の差がある。
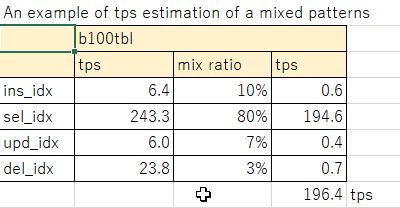
実際のシステムにおいては、一定の比率で参照、更新トランザクションが発生するので、上記を基礎数値として1コアあたりにさばけるトランザクション数が導き出せる。例えば、b100tblのモデルでselectが80%、insertが10%、updateが7%、deleteが3%の比率とすると、196tps/コアとなる。このような考え方で、必要な単位時間あたりのトランザクションに応じて、コア数を見積もることができる。実際に使うコアのスペックが異なる場合は、ここからspec int等のベンチマーク結果から、コア性能を考慮した見積もりを作れば良いだろう。
7.まとめ
DBサーバのCPUの見積もりについて、モデル(データ、処理モデル)から、OCIで実測した結果をもとに基礎数値を求めて、コア数を見積もる考え方について述べた。また、測定結果について、SQL、DMLの性能の傾向、カラム数(平均行長)に対する性能の傾向について考察した。
性能測定結果は環境によって変わるので、あくまで参考程度にしかならないとしても、実際の業務処理ロジックに近いモデルを作ることで、見積もりの精度を上げることができるだろう。
ありがたいことに、OCIのようなパブリッククラウドが使えるようになり、実機による測定ができる環境を実に簡単に準備できるようになった。いくばくかの利用料は発生するかもしれないが、コア数を比較的精度高く見積もることは、Oracleライセンス費の適正化につながるので、サイジング用にOCI使ったとしても十分にその価値はあるのではないかと感じる。
◆参考
[1]測定結果詳細:20240211_性能テスト結果_v2.xlsx
2024-02-11 14:03


