SQL*Loaderの性能見積もりの考え方 [アーキテクチャ]
はじめに
データ移行等でcsvをSQL*LoaderでOracleにロードする際、どの程度の性能を期待できるのかを見積もる必要がある。特定の表についてであれば、実機の基礎性能をベースに件数で比例させれば簡単に見積もりができる。しかし、実際は様々な表があり、それぞれに対して測定する訳にもいかない。ここでは、簡単なテストケースでLoaderの基礎性能を測定し、平均行長と行数からロード性能を見積もる方法について考察してみたい。
1.性能モデル
やりたいことは、特定の環境において、入力となるcsvの平均行長と行数から、SQL*Loaderの性能を見積もりすることである。
方法として考えたのは、平均行長の異なる3つの表、b10tbl, b50tbl, b100tblについて、一定の件数(10,000,000件)のロード性能を基礎数値として取得し、それをもとに性能を見積もる方法である。
モデルとした表は、idカラムをnumber型の主キーとし、1からの連番を振る。dtカラムはdate型で、更新日時を入れる。col1~colnはvarchar2(10)のカラムで、b10tblは1個、b50tblは5個、b100tblは10個とし、ランダムな文字列を10バイト挿入する。
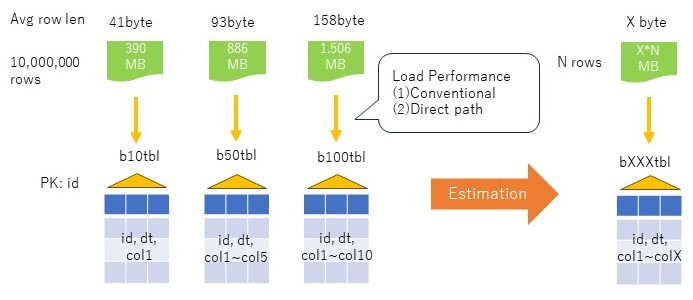
Loaderの測定パタンとしては、一般的なにコンベンショナルとダイレクトパスロードを考える。前提として、データは主キー順に並んでいることは保証されず、主キーは作成しつつ挿入することとする。NOLOGGINGも使わない。表のPCTFREEはデフォルト10%、記憶域(初期エクステントサイズ)もデフォルト(64KB)とする。
2.表(データ)の準備
表を作成する。
drop table b10tbl cascade constraints; create table b10tbl( id number(9), dt date, col1 varchar2(10), constraint pk_b10tbl primary key (id) ); drop table b50tbl cascade constraints; create table b50tbl( id number(9), dt date, col1 varchar2(10), col2 varchar2(10), col3 varchar2(10), col4 varchar2(10), col5 varchar2(10), constraint pk_b50tbl primary key (id) ); drop table b100tbl cascade constraints; create table b100tbl( id number(9), dt date, col1 varchar2(10), col2 varchar2(10), col3 varchar2(10), col4 varchar2(10), col5 varchar2(10), col6 varchar2(10), col7 varchar2(10), col8 varchar2(10), col9 varchar2(10), col10 varchar2(10), constraint pk_b100tbl primary key (id) );
SQL*Loader用のcsvを生成するための初期データを挿入する。
begin
for i in 1..10 loop
insert into b10tbl select
1000000*(i-1)+rownum id,
sysdate dt,
dbms_random.string('x',10) col1
from dual connect by level <=1000000;
commit;
end loop;
end;
/
begin
for i in 1..10 loop
insert into b50tbl select
1000000*(i-1)+rownum id,
sysdate dt,
dbms_random.string('x',10) col1,
dbms_random.string('x',10) col2,
dbms_random.string('x',10) col3,
dbms_random.string('x',10) col4,
dbms_random.string('x',10) col5
from dual connect by level <=1000000;
commit;
end loop;
end;
/
begin
for i in 1..10 loop
insert into b100tbl select
1000000*(i-1)+rownum id,
sysdate dt,
dbms_random.string('x',10) col1,
dbms_random.string('x',10) col2,
dbms_random.string('x',10) col3,
dbms_random.string('x',10) col4,
dbms_random.string('x',10) col5,
dbms_random.string('x',10) col6,
dbms_random.string('x',10) col7,
dbms_random.string('x',10) col8,
dbms_random.string('x',10) col9,
dbms_random.string('x',10) col10
from dual connect by level <=1000000;
commit;
end loop;
end;
/
統計情報を取得しておく(_optimizer_gather_stats_on_loadがデフォルト(TRUE)のため、空だと自動で取得されてしまうかもしれないため)。
exec dbms_stats.gather_table_stats('scott','b10tbl');
exec dbms_stats.gather_table_stats('scott','b50tbl');
exec dbms_stats.gather_table_stats('scott','b100tbl');
この時点でセグメントサイズを確認しておく。
col segment_name for a20 select segment_name, sum(bytes)/1024/1024 mb from user_segments where segment_name like '%B%TBL' group by segment_name order by 1; SEGMENT_NAME MB -------------------- ---------- B100TBL 1415 B10TBL 327 B50TBL 804 PK_B100TBL 160 PK_B10TBL 164 PK_B50TBL 163 6 rows selected.
ここから、csvファイルを出力するためのSQLファイルを作成する。ここで主キーでのソートはしない。csvの出力先を/u01とする(OCIのBaseDBは/u01のファイルシステムに196Gが割り当てられている。/homeは1GBもないので、大きなファイルを置いてはいけない)。
vi b10tbl.sql spool /u01/app/oracle/dump/scott/b10tbl.csv select * from b10tbl; spool off vi b50tbl.sql spool /u01/app/oracle/dump/scott/b50tbl.csv select * from b50tbl; spool off vi b100tbl.sql spool /u01/app/oracle/dump/scott/b100tbl.csv select * from b100tbl; spool off
上記sqlファイルをsqlplusから実行して、csvファイルを作成する。
sqlplus scott/xxx@oradb alter session set nls_date_format='YYYYMMDD HH24:MI:SS'; set feedback off heading off termout off set markup csv on delimiter '|' @b10tbl.sql @b50tbl.sql @b100tbl.sql set markup csv off
csvのサイズは以下の通り、最大のB100TBLで1.47GBであった。
[oracle@oradbvm1 ~]$ cd /u01/app/oracle/dump/scott/ [oracle@oradbvm1 scott]$ ll *.csv -rw-r--r-- 1 oracle oinstall 1578888897 Feb 18 16:19 b100tbl.csv -rw-r--r-- 1 oracle oinstall 408888897 Feb 18 16:17 b10tbl.csv -rw-r--r-- 1 oracle oinstall 928888897 Feb 18 16:18 b50tbl.csv [oracle@oradbvm1 scott]$
3.SQL*Loaderの準備
SQL*Loaderの制御ファイルを用意する。トランケートモードとして、表にデータが入っていれば切り捨てられる。
vi b10tbl.ctl load data characterset UTF8 infile '/u01/app/oracle/dump/scott/b10tbl.csv' badfile 'b10tbl.bad' discardfile 'b10tbl.dsc' truncate into table b10tbl fields terminated by '|' optionally enclosed by '"' trailing nullcols ( id integer external, dt date 'YYYYMMDD HH24:MI:SS', col1 char(10) ) vi b50tbl.ctl load data characterset UTF8 infile '/u01/app/oracle/dump/scott/b50tbl.csv' badfile 'b50tbl.bad' discardfile 'b50tbl.dsc' truncate into table b50tbl fields terminated by '|' optionally enclosed by '"' trailing nullcols ( id integer external, dt date 'YYYYMMDD HH24:MI:SS', col1 char(10), col2 char(10), col3 char(10), col4 char(10), col5 char(10) ) vi b100tbl.ctl load data characterset UTF8 infile '/u01/app/oracle/dump/scott/b100tbl.csv' badfile 'b100tbl.bad' discardfile 'b100tbl.dsc' truncate into table b100tbl fields terminated by '|' optionally enclosed by '"' trailing nullcols ( id integer external, dt date 'YYYYMMDD HH24:MI:SS', col1 char(10), col2 char(10), col3 char(10), col4 char(10), col5 char(10), col6 char(10), col7 char(10), col8 char(10), col9 char(10), col10 char(10) )
4.性能測定
上記のモデルを実際にOCIのBaseDBを利用して測定した。環境はこちらに記載の環境と同じため割愛する。
SQL*Loaderでロードを行う。まずは、コンベンショナルモードを使う。1000件毎にコミットとなるよう、rowsとbindsizeを設定する。
sqlldr scott/xxx@oradb control=b10tbl.ctl log=b10tblc.log rows=1000,bindsize=1000000,silent=errors,feedback sqlldr scott/xxx@oradb control=b50tbl.ctl log=b50tblc.log rows=1000,bindsize=1000000,silent=errors,feedback sqlldr scott/xxx@oradb control=b100tbl.ctl log=b100tblc.log rows=1000,bindsize=1000000,silent=errors,feedback
続いて、ダイレクトパス(direct=true)でデータロードを行う。1000件毎の処理となるよう、columnarrayrowsを設定する。
sqlldr scott/xxx@oradb control=b10tbl.ctl log=b10tbld.log direct=true, columnarrayrows=1000, silent=errors,feedback sqlldr scott/xxx@oradb control=b50tbl.ctl log=b50tbld.log direct=true, columnarrayrows=1000, silent=errors,feedback sqlldr scott/xxx@oradb control=b100tbl.ctl log=b100tbld.log direct=true, columnarrayrows=1000, silent=errors,feedback
5.測定結果
測定結果のサマリは下表の通り。
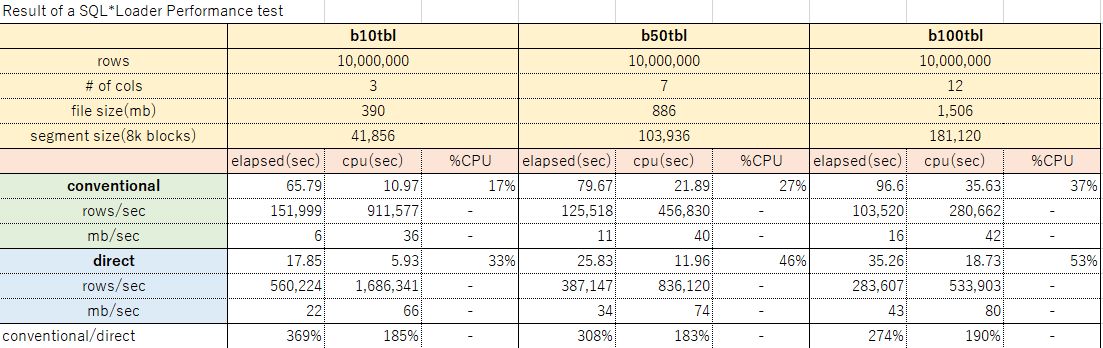
上記結果から、平均行長とロード性能の関係をグラフにすると、下図の通りとなった。行長が大きくなると線形に処理時間が伸びているように見えるため、ここから任意の平均行長について10,000,000件をロードする近似式を作ることができる。
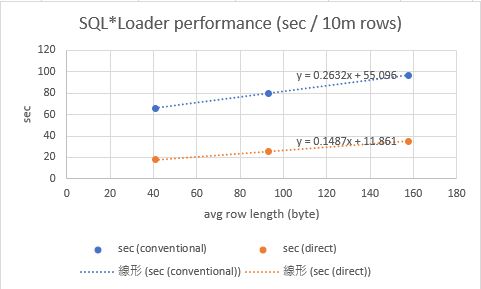
上記近似式で得られた結果から、単位行数あたりのロード時間が求まるので、下図のように任意の行数を時間を見積もる式が得られる。例えば、平均行長223バイト、5,000,000件のb200tblの場合は、コンベンショナルは57秒、ダイレクトパスロードは23秒と見積もることができる。

答え合わせのため、実際に平均行長223バイト、5,000,000件で測定したところ、コンベンショナルの見積もり57秒に対し54秒、ダイレクトパスの見積もり23秒に対し28秒となった。若干ブレはあるものの、まずまずの値が見積もれることがわかった。
SQL> !ls -l /u01/app/oracle/dump/scott/b200tbl.csv
-rw-r--r-- 1 oracle oinstall 1113888896 Feb 20 07:36 /u01/app/oracle/dump/scott/b200tbl.csv
SQL> select 1113888896/5000000 from dual;
222.777779 →平均カラム長223バイト
SQL> !wc -l /u01/app/oracle/dump/scott/b200tbl.csv
5000000 /u01/app/oracle/dump/scott/b200tbl.csv →5,000,000件
[oracle@oradbvm1 ldrtest]$ grep Elapsed b200tbld.log
Elapsed time was: 00:00:28.24 →ダイレクトパス
[oracle@oradbvm1 ldrtest]$ grep Elapsed b200tblc.log
Elapsed time was: 00:00:54.42 →コンベンショナル
[oracle@oradbvm1 ldrtest]$
7.まとめ
本稿では、SQL*Loaderの性能を、実機の基礎性能を用いて、任意の行長、行数のロード性能(コンベンショナル、ダイレクト)を見積もる方法について考察した。性能の結果はあくまで一例で、実際は入力ファイルの要件に応じてLoaderのパラメータは実際の利用シーンにより適宜変更が必要だろう。なお、平均行長が伸びると、線形に処理時間も伸びる、という仮定は一定の範囲を超えると誤差が大きくなるかもしれない。ブロックサイズ(今回の環境では8KB、PCTFREE10%)に対して、平均行長が極端に大きい場合は誤差が大きくなる可能性があるので、大きな行長を扱う場合は基礎性能モデルの作り方に注意が必要だろう。
◆参考
[1]測定結果詳細:20240218_sqlldrPerfTest_v2.xlsx
2024-02-20 06:47


