OCI BaseDBの19cから23cへのデータ移行(DataPump編) [OCI]
1.はじめに
OCI上で19cから23cの環境へデータを移行する検証をしたので備忘までメモを残しておく。具体的なシナリオとしては、19cの環境でexpdpでエクスポートしたダンプファイルを、新規に23cの環境にimpdpでインポートする。ダンプファイルはノーマル(平文)と、TDEの暗号鍵で暗号化したもの(encryption_mode = transparent)の2種類を用いる。後者のインポートのために、19c環境のTDEのマスタ暗号鍵を23c環境へインポートすることも行う。
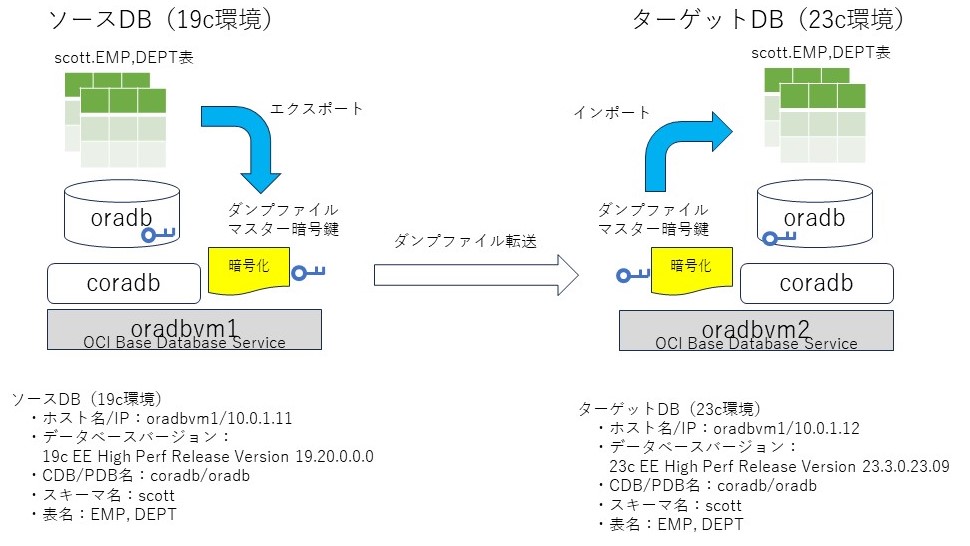
手順の概要は以下の通り。
2.環境準備
・ソースDB
データ移行の対象となる表の状態確認をする。EMP表100万件、DEPT表10万件、セグメントサイズは合計77MB程度である。
[oracle@oradbvm1 ~]$ sqlplus scott/XXX@oradb
SQL> select count(*) from emp;
COUNT(*)
----------
1000000
SQL> select count(*) from dept;
COUNT(*)
----------
100000
SQL> select segment_name, bytes/1024/1024 mb from user_segments;
SEGMENT_NAME MB
_______________ _____
DEPT 5 ★
EMP 72 ★
IDX1_EMP 23
PK_DEPT 2
PK_EMP 16
SQL>
Base Database Serviceでは/u01配下に150GB程度の領域がある。この配下にディレクトリオブジェクトを作成する。
[oracle@oradbvm1 ~]$ df -h Filesystem Size Used Avail Use% Mounted on ・・・ /dev/sdg 196G 42G 145G 23% /u01 ★ [oracle@oradbvm1 ~]$ mkdir -p /u01/app/oracle/dump/scott [oracle@oradbvm1 ~]$ chmod 777 /u01/app/oracle/dump/scott [oracle@oradbvm1 ~]$ ls -ld /u01/app/oracle/dump/scott drwxrwxrwx 2 oracle oinstall 4096 Nov 21 06:11 /u01/app/oracle/dump/scott [oracle@oradbvm1 ~]$ sqlplus sys/XXX@oradb as sysdba SQL> CREATE DIRECTORY expdir AS '/u01/app/oracle/dump/scott'; Directory created. SQL> grant read, write on directory expdir to scott; Grant succeeded.
・ターゲットDB
OCIコンソールからソースDBと同じセグメントに新規インスタンスを作成する。この際、DBバージョンは23c、エディションはEE HPを選択する(詳細な手順については[1]を参照)。プロビジョニング完了後、以下設定を行う。
- OSのoracleユーザのパスワードを設定する(sshのファイル転送のため)
- tnsnames.oraにPDBへの接続エントリを追加する
- ソースDBと同じスキーマ(scott)を作成、必要な権限を付与する
ディレクトリオブジェクトの作成はソースと同じ手順を実施する。表はソース側のEMP・DEPT表のDDL(参考[2]参照)を実行する。
3.エクスポート
・(ソースDB)マスタ暗号鍵のエクスポート
ソースDBのPDBの管理者で接続し、以下のようにマスタ暗号鍵をエクスポートする。
[oracle@oradbvm1 ~]$ sqlplus sys/XXX@oradb as sysdba SQL*Plus: Release 19.0.0.0.0 - Production on Wed Nov 22 09:21:03 2023 Version 19.20.0.0.0 Copyright (c) 1982, 2022, Oracle. All rights reserved. Connected to: Oracle Database 19c EE High Perf Release 19.0.0.0.0 - Production Version 19.20.0.0.0 SQL> administer key management export encryption keys with secret "XXX" to '/home/oracle/ewallet_oradbmv1_oradb.p12' force keystore identified by "XXX"; keystore altered. SQL> !ls -l total 6108 -rw-r--r-- 1 oracle asmadmin 2612 Nov 22 09:21 ewallet_oradbmv1_oradb.p12 ★ SQL>
・(ソースDB)データのエクスポート
はじめにノーマル(平文)のエクスポートを実行する。平文でエクスポートされたことを示すORA-39173が出力されるが、処理は正常終了する。
[oracle@oradbvm1 scott]$ expdp scott/XXX@oradb schemas=scott directory=expdir dumpfile=scott.dmp logfile=expdpscott.log content=data_only Export: Release 19.0.0.0.0 - Production on Sun Nov 12 16:20:46 2023 Version 19.20.0.0.0 Copyright (c) 1982, 2019, Oracle and/or its affiliates. All rights reserved. Connected to: Oracle Database 19c EE High Perf Release 19.0.0.0.0 - Production FLASHBACK automatically enabled to preserve database integrity. Starting "SCOTT"."SYS_EXPORT_SCHEMA_01": scott/********@oradb schemas=scott directory=expdir dumpfile=scott.dmp logfile=expdpscott.log content=data_only Processing object type SCHEMA_EXPORT/TABLE/TABLE_DATA . . exported "SCOTT"."EMP" 55.15 MB 1000000 rows . . exported "SCOTT"."DEPT" 3.619 MB 100000 rows ★=~59MB ORA-39173: Encrypted data has been stored unencrypted in dump file set. ★暗号化されてない Master table "SCOTT"."SYS_EXPORT_SCHEMA_01" successfully loaded/unloaded ****************************************************************************** Dump file set for SCOTT.SYS_EXPORT_SCHEMA_01 is: /u01/app/oracle/dump/scott/scott.dmp Job "SCOTT"."SYS_EXPORT_SCHEMA_01" successfully completed at Sun Nov 12 16:20:51 2023 elapsed 0 00:00:04 ★正常終了
続いて暗号化エクスポートを実行する。encryption=data_onlyと指定する。encryption_modeは指定していないが、TDEのウォレットがオープン状態なので、デフォルトでtransparent、つまりTDEのマスタ暗号鍵を利用して暗号化を行うこととなる。ORA-39173は発生しないので、暗号化されていることがわかる。
[oracle@oradbvm1 scott]$ expdp scott/XXX@oradb schemas=scott directory=expdir dumpfile=scotte.dmp logfile=expdpscotte.log content=data_only encryption=data_only Export: Release 19.0.0.0.0 - Production on Sun Nov 12 16:52:47 2023 Version 19.20.0.0.0 Copyright (c) 1982, 2019, Oracle and/or its affiliates. All rights reserved. Connected to: Oracle Database 19c EE High Perf Release 19.0.0.0.0 - Production FLASHBACK automatically enabled to preserve database integrity. Starting "SCOTT"."SYS_EXPORT_SCHEMA_01": scott/********@oradb schemas=scott directory=expdir dumpfile=scotte.dmp logfile=expdpscotte.log content=data_only encryption=data_only Processing object type SCHEMA_EXPORT/TABLE/TABLE_DATA . . exported "SCOTT"."EMP" 55.15 MB 1000000 rows . . exported "SCOTT"."DEPT" 3.619 MB 100000 rows ★=~59MB Master table "SCOTT"."SYS_EXPORT_SCHEMA_01" successfully loaded/unloaded ****************************************************************************** Dump file set for SCOTT.SYS_EXPORT_SCHEMA_01 is: /u01/app/oracle/dump/scott/scotte.dmp Job "SCOTT"."SYS_EXPORT_SCHEMA_01" successfully completed at Sun Nov 12 16:52:52 2023 elapsed 0 00:00:04 ★正常終了
ディレクトリオブジェクトのファイルを確認すると、以下のように2つのダンプファイルが作成されていることがわかる。暗号化してもファイルサイズに変化はない。
[oracle@oradbvm1 scott]$ ll total 120936 -rw-r--r-- 1 oracle asmadmin 1056 Nov 12 16:52 expdpscotte.log -rw-r--r-- 1 oracle asmadmin 1104 Nov 12 16:48 expdpscott.log -rw-r----- 1 oracle asmadmin 61911040 Nov 12 16:48 scott.dmp ★ノーマル(平文) -rw-r----- 1 oracle asmadmin 61911040 Nov 12 16:52 scotte.dmp ★暗号化 [oracle@oradbvm1 scott]$
4.ダンプファイル転送
・マスタ暗号鍵の転送
ソースDBからマスタ暗号鍵をscp転送する
[oracle@oradbvm1 ~]$ cd ~/ [oracle@oradbvm1 ~]$ scp ewallet_oradbmv1_oradb.p12 10.0.1.12:~/ oracle@10.0.1.12's password: ewallet_oradbmv1_oradb.p12 100% 2612 5.4MB/s 00:00
・ダンプファイルの転送
ソースDBからダンプファイルをscp転送する。
[oracle@oradbvm1 ~]$ cd /u01/app/oracle/dump/scott [oracle@oradbvm1 scott]$ scp *.dmp 10.0.1.12:/u01/app/oracle/dump/scott oracle@10.0.1.12's password: scott.dmp 100% 59MB 100.0MB/s 00:00 scotte.dmp 100% 59MB 98.0MB/s 00:00 [oracle@oradbvm1 scott]$
ターゲットDBにて、ダンプファイルを確認する。
[oracle@oradbvm2 scott]$ ll -rw-r----- 1 oracle oinstall 61911040 Nov 21 07:12 scott.dmp -rw-r----- 1 oracle oinstall 61911040 Nov 21 07:12 scotte.dmp
5.インポート
・(ターゲットDB)データのインポート(ノーマル)
ターゲットDBにて、インポートを行う。EMP表からDEPT表への参照整合性制約を無効にしてからインポートを行うと、問題なくインポートできる。
[oracle@oradbvm2 ~]$ sqlplus scott/XXX@oradb SQL> alter table emp disable constraint fk_deptno; [oracle@oradbvm2 ~]$ impdp scott/XXX@oradb schemas=scott directory=expdir dumpfile=scott.dmp logfile=impdpscott.log content=data_only table_exists_action=truncate Import: Release 23.0.0.0.0 - Production on Fri Nov 24 09:55:25 2023 Version 23.3.0.23.09 Copyright (c) 1982, 2023, Oracle and/or its affiliates. All rights reserved. Connected to: Oracle Database 23c EE High Perf Release 23.0.0.0.0 - Production Master table "SCOTT"."SYS_IMPORT_SCHEMA_01" successfully loaded/unloaded Starting "SCOTT"."SYS_IMPORT_SCHEMA_01": scott/********@oradb schemas=scott directory=expdir dumpfile=scott.dmp logfile=impdpscott.log content=data_only table_exists_action=truncate Processing object type SCHEMA_EXPORT/TABLE/TABLE_DATA . . imported "SCOTT"."EMP" 55.15 MB 1000000 rows . . imported "SCOTT"."DEPT" 3.619 MB 100000 rows Job "SCOTT"."SYS_IMPORT_SCHEMA_01" successfully completed at Fri Nov 24 09:56:09 2023 elapsed 0 00:00:35 ★成功
ここで試しに、暗号化したダンプファイルをインポートしようとすると、複合化に必要なマスタ暗号鍵が見つからないため、ORA-28362のエラーでインポートすることができない。このため、ソースDBのPDBのマスタ暗号鍵のインポートが必要となる。
SQL> !impdp scott/XXX@oradb schemas=scott directory=expdir dumpfile=scotte.dmp logfile=impdpscotte.log content=data_only table_exists_action=truncate Import: Release 23.0.0.0.0 - Production on Fri Nov 24 09:56:52 2023 Version 23.3.0.23.09 Copyright (c) 1982, 2023, Oracle and/or its affiliates. All rights reserved. Connected to: Oracle Database 23c EE High Perf Release 23.0.0.0.0 - Production ORA-39002: invalid operation ORA-39189: unable to decrypt dump file set ORA-28362: master key not found ★エラーとなる
・(ターゲットDB)マスタ暗号鍵のインポート
ターゲットDBにて、ソースDBのPDBのマスタ暗号鍵をインポートする。インポートはコンテナDBに接続して実行する(PDBではインポートできない)。v$encryption_keysでインポートされていることを確認する。
[oracle@oradbvm2 ~]$ ll total 12 -rw-r--r-- 1 oracle oinstall 2612 Nov 22 09:22 ewallet_oradbmv1_oradb.p12 ★ [oracle@oradbvm2 ~]$ sqlplus / as sysdba SQL*Plus: Release 23.0.0.0.0 - Production on Wed Nov 22 09:26:27 2023 Version 23.3.0.23.09 Copyright (c) 1982, 2023, Oracle. All rights reserved. Connected to: Oracle Database 23c EE High Perf Release 23.0.0.0.0 - Production Version 23.3.0.23.09 SQL> administer key management import keys with secret "XXX" from '/home/oracle/ewallet_oradbmv1_oradb.p12' force keystore identified by "XXX" with backup; keystore altered. SQL> select key_id, creation_time, creator_dbname, activating_pdbname, con_id from v$encryption_keys; KEY_ID CREATION_TIME CREATOR_DBNAME ACTIVATING_PDBNAME CON_ID _______________________________________________________ _________________________________________ __________________ _____________________ _________ AXTVRRDA8U+uv9W09+9PuAIAAAAAAAAAAAAAAAAAAAAAAAAAAAAA 19-APR-23 10.54.29.632286000 PM GMT coradb_oradbvm1 ORADB 3★PDBのマスタ暗号鍵 ARq4NDRE80+SvwxzekrKJbAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA 23-NOV-23 05.20.41.789397000 PM -07:00 coradb_oradbvm2 CDB$ROOT 1 AYpmGS1/Gk9Ev1QZZYcswd4AAAAAAAAAAAAAAAAAAAAAAAAAAAAA 23-NOV-23 05.27.18.895760000 PM -07:00 coradb_oradbvm2 ORADB 3 SQL>
・(ターゲットDB)データのインポート(暗号化)
暗号化されたダンプファイルをインポートする。正常にインポートされたら、参照整合性制約を有効にする。
[oracle@oradbvm2 ~]$ impdp scott/XXX@oradb schemas=scott directory=expdir dumpfile=scotte.dmp logfile=impdpscotte.log content=data_only table_exists_action=truncate Import: Release 23.0.0.0.0 - Production on Fri Nov 24 10:15:06 2023 Version 23.3.0.23.09 Copyright (c) 1982, 2023, Oracle and/or its affiliates. All rights reserved. Connected to: Oracle Database 23c EE High Perf Release 23.0.0.0.0 - Production Master table "SCOTT"."SYS_IMPORT_SCHEMA_01" successfully loaded/unloaded Starting "SCOTT"."SYS_IMPORT_SCHEMA_01": scott/********@oradb schemas=scott directory=expdir dumpfile=scotte.dmp logfile=impdpscotte.log content=data_only table_exists_action=truncate Processing object type SCHEMA_EXPORT/TABLE/TABLE_DATA . . imported "SCOTT"."EMP" 55.15 MB 1000000 rows . . imported "SCOTT"."DEPT" 3.619 MB 100000 rows Job "SCOTT"."SYS_IMPORT_SCHEMA_01" successfully completed at Fri Nov 24 10:15:32 2023 elapsed 0 00:00:24 ★成功 [oracle@oradbvm2 ~]$ sqlplus scott/XXX@oradb SQL> alter table emp enable constraint fk_deptno;
6.まとめ
本稿では、OCI上で19cの環境からデータをexpdp/impdpで23cの環境へ移行する手順について記載した。
実際問題、今回のケースのようにOCIの内部でダンプの暗号化までする必要はないだろう。しかし、実際はファイルサイズが大きくなると、オブジェクトストレージや媒体を介した転送が必要なケースもあり、そのような場合に暗号化が必要になることが考えられる。暗号化の方法にはパスワードを設定する方法(encryption_mode=password)もあるが、インポートの際に毎回パスワードを設定するのも煩わしい。OCIでEE High Performance以上を使っているなら、advanced securityのダンプファイルの暗号化機能が利用できるため、元のPDBのマスタ暗号鍵をターゲットとなるDBにインポートすることで、透過的に暗号化ダンプファイルのエクスポート・インポートが可能となる。
参考
[1]ベースデータベース コンソールを使用したDBシステムの作成
https://docs.public.oneportal.content.oci.oraclecloud.com/ja-jp/iaas/dbcs/doc/create-db-system-using-console.html#DBSCB-GUID-624EFC8F-CF53-4A88-B9AB-2F45F2B9A546
[2]検証用DDL
drop table emp cascade constraints; drop table dept cascade constraints; create table dept( deptno number(7,0), dname varchar2(14), loc varchar2(13), constraint pk_dept primary key (deptno) ); create table emp( empno number(7,0), ename varchar2(10), job varchar2(9), mgr number(7,0), hiredate date, sal number(7,2), comm number(7,2), deptno number(7,0), constraint pk_emp primary key (empno), constraint fk_deptno foreign key (deptno) references dept (deptno) ); create index idx1_emp on emp ( deptno );
2023-11-25 10:10
UNION ALLを使ったMVIEWの制約について [SQL・DDL]
1.はじめに
最近、MVIEWでUNION ALLを使った場合の制約について調査したので、備忘までメモを残しておきたい。
MVIEWとは実体のあるビューであり、ある断面のデータを複製してビューをあたかもローカルの表のようにして使う機能である。MVIEWは大規模なテーブルを集計する処理において、VIEW経由でアクセスされる度に計算するのではなく、あらかじめ集計結果を実体として保持しておくことにより、参照時に高価な処理を何度も行うことを回避できるメリットがある。
ソースとなる表が更新されることにより、レプリカであるMVIEWの更新が必要となるが、高速リフレッシュという機能を使うことにより、ソース側表の更新履歴(MLOGという)だけをMVIEWに反映することがで、差分更新が可能である。
高速リフレッシュが可能なクエリには制約がある。一般的に、結合や集計処理を含む複雑なクエリになるほど制約を意識する必要がある。また、MVIEWの定義にはDBLINKを利用できるため、(複数の)リモートDBからDBLINK経由でMVIEWを構成することができるが、これにも制約がある。実現したいビューがMVIEWで構成できるかどうかは、上記の複雑な制約の網をくぐり抜ける必要があるため、実機での確認がかかせない。
ここでは、スキーマ分割された表(定義は同一)を別データベースにMVIEWで1つにUNION ALLでまとめて参照したい、という要件について、実機でMVIEW の実現可否や運用上の制約事項を調べてみよう。。
2.検証モデル
検証のモデルとして、下図のような構成を考える。
- PDBは2つ(k3,k5)でその間にリモートMVIEW用のDBLINK(k5tok3)を構成する
- MVIEWのソースとなるPDB(k3)には3つのスキーマ(a,b,c)を作成し、それぞれemp表を作成する。データは主キーが重複しないように入れる
- EMP表には、それぞれ高速リフレッシュ用のMLOGを作成する
- MVIEWのターゲットであるPDB(k5)に3つのEMP表をUNION ALLしたMVIEWを作成する(MF_EMP_UNION)
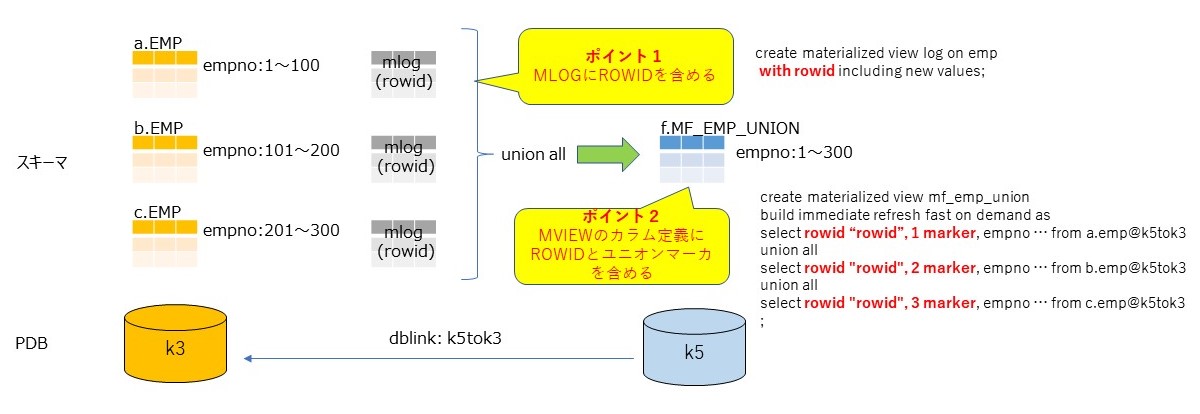
この構成で特筆すべき点は2つある。1つはMLOGにROWIDを含めることである。ROWIDはソース表の行を特定する物理アドレスであり、これを更新ログに記録する。もう一つはMVIEWのカラム定義に、ROWIDとユニオンマーカ(ユニオンのソースとなる表を一位に特定するカラム)を含めることである。
以下に、手元のVirtual BoxのOracle19.11の環境を用いて、このモデルを実際に作成してみよう。まず表を作成する。以下の表定義をソースのPDBの3つのスキーマで実行する。
drop table emp cascade constraints; drop table dept cascade constraints; create table dept( deptno number(7,0), dname varchar2(14), loc varchar2(13), constraint pk_dept primary key (deptno) ); create table emp( empno number(7,0), ename varchar2(10), job varchar2(9), mgr number(7,0), hiredate date, sal number(7,2), comm number(7,2), deptno number(7,0), constraint pk_emp primary key (empno), constraint fk_deptno foreign key (deptno) references dept (deptno) ); create index idx1_emp on emp ( deptno );
次にデータを挿入する。a、b、cのスキーマでempnoが100ずつずれるようにして挿入する。
conn b/b@k3
@creemp
insert into dept select
rownum+10 deptno,
dbms_random.string('u',14) dname,
dbms_random.string('u',13) loc
from dual connect by level <=10;
commit;
insert into emp select
rownum+100 empno,
dbms_random.string('u',10) ename,
dbms_random.string('u',9) job,
dbms_random.value(1,100)+100 mgr,
sysdate - dbms_random.value(1,5000) hiredate,
dbms_random.value(3000,9999) sal,
dbms_random.value(3000,9999) comm,
dbms_random.value(1,10)+10 deptno
from dual connect by level <=100;
commit;
exec dbms_stats.gather_table_stats('b','dept');
exec dbms_stats.gather_table_stats('b','emp');
conn c/c@k3
@creemp
insert into dept select
rownum+20 deptno,
dbms_random.string('u',14) dname,
dbms_random.string('u',13) loc
from dual connect by level <=10;
commit;
insert into emp select
rownum+200 empno,
dbms_random.string('u',10) ename,
dbms_random.string('u',9) job,
dbms_random.value(1,100)+200 mgr,
sysdate - dbms_random.value(1,5000) hiredate,
dbms_random.value(3000,9999) sal,
dbms_random.value(3000,9999) comm,
dbms_random.value(1,10)+20 deptno
from dual connect by level <=100;
commit;
exec dbms_stats.gather_table_stats('c','dept');
exec dbms_stats.gather_table_stats('c','emp');
挿入された行を各表毎3行ずつサンプルで確認する。
SQL> select empno, ename from a.emp where rownum <= 3
2 union all
3 select empno, ename from b.emp where rownum <= 3
4 union all
5* select empno, ename from c.emp where rownum <= 3;
EMPNO ENAME
________ _____________
1 WANOZRAMAP
2 GMREPEQFIN
3 SKWBNXLCNF
101 GVXUEOOQJM
102 XGLASIZISR
103 UVODELRDCI
201 LKCFXEGPPE
202 JKKFUPAHXM
203 VGMJJTAVUN
9 rows selected.
次にソース側PDB(k3)で各EMP表に対してMLOGを作成する。MLOGはROWIDを使って作成していることに留意する。
SQL> conn a/a@k3 Connected. SQL> create materialized view log on emp with rowid including new values; Materialized view log EMP created. SQL> conn b/b@k3 Connected. SQL> create materialized view log on emp with rowid including new values; Materialized view log EMP created. SQL> conn c/c@k3 Connected. SQL> create materialized view log on emp with rowid including new values; Materialized view log EMP created.
以上でソース側の準備が完了したため、リモート側のPDB(k5)でMVIEWを作成する。高速リフレッシュを使うため、refresh fastを指定し、各selectのカラムにrowid列とユニオンマーカとなるmarker列を含めていることに留意する。
SQL> conn f/f@k5 Connected. SQL> create materialized view mf_emp_union 2 build immediate refresh fast on demand as 3 select rowid "rowid", 1 marker, empno,ename,job,mgr,hiredate,sal,comm,deptno from a.emp@k5tok3 4 union all 5 select rowid "rowid", 2 marker, empno,ename,job,mgr,hiredate,sal,comm,deptno from b.emp@k5tok3 6 union all 7 select rowid "rowid", 3 marker, empno,ename,job,mgr,hiredate,sal,comm,deptno from c.emp@k5tok3 8* ; alter table mf_emp_union add constraint pk_mf_emp_union primary key (empno); Materialized view MF_EMP_UNION created. SQL> alter table mf_emp_union add constraint pk_mf_emp_union primary key (empno); Table MF_EMP_UNION altered.
MVIEWが作成され、同期されていることが確認する。
SQL> select empno,ename from mf_emp_union where empno in (1,2,3,101,102,103,201,202,203);
EMPNO ENAME
________ _____________
1 WANOZRAMAP
2 GMREPEQFIN
3 SKWBNXLCNF
101 GVXUEOOQJM
102 XGLASIZISR
103 UVODELRDCI
201 LKCFXEGPPE
202 JKKFUPAHXM
203 VGMJJTAVUN
9 rows selected.
以上で準備は完了である。
3.検証
ここでは以下3つのシナリオで高速リフレッシュの動作検証を行う。
(1)c.EMPに全件UPDATE、c.EMPに1件INSERTを行い、高速リフレッシュ
(2)c.EMPをalter table moveし、高速リフレッシュ
(3)c.EMPをトランケートし、高速リフレッシュ
期待される結果は、(1)は正常に同期される。(2)(3)は高速リフレッシュがエラーとなり、復旧に完全リフレッシュが必要となるはずである。以下、それぞれについて結果を確認していこう。
(1)c.EMPに全件UPDATE、c.EMPに1件INSERTを行い、高速リフレッシュ
c.EMPにUPDATEと1件INSERTを行う。
SQL> conn c/c@k3 Connected. SQL> update emp set ename='ZZZ'; 100 rows updated. SQL> commit; Commit complete. SQL> insert into emp values(997, 'KING', 'PRESIDENT', null, sysdate, 5000, null, 21); 1 row inserted. SQL> commit; Commit complete.
ターゲットPDB(k5)にて、高速リフレッシュを実行する。高速リフレッシュ後に、MVIEWに正しくenameの更新、および1件INSERTされたことが確認できる。
SQL> conn f/f@k5
Connected.
SQL> select empno,ename from mf_emp_union where empno in (1,2,3,101,102,103,201,202,203);
EMPNO ENAME
________ _____________
1 WANOZRAMAP
2 GMREPEQFIN
3 SKWBNXLCNF
101 GVXUEOOQJM
102 XGLASIZISR
103 UVODELRDCI
201 LKCFXEGPPE
202 JKKFUPAHXM
203 VGMJJTAVUN
9 rows selected.
SQL> select empno,ename from mf_emp_union where empno=997;
no rows selected
SQL> EXECUTE DBMS_MVIEW.REFRESH('mf_emp_union', 'f');
PL/SQL procedure successfully completed.
SQL> select empno,ename from mf_emp_union where empno in (1,2,3,101,102,103,201,202,203);
EMPNO ENAME
________ _____________
1 WANOZRAMAP
2 GMREPEQFIN
3 SKWBNXLCNF
101 GVXUEOOQJM
102 XGLASIZISR
103 UVODELRDCI
201 ZZZ
202 ZZZ
203 ZZZ
9 rows selected.
SQL> select empno,ename from mf_emp_union where empno=997;
EMPNO ENAME
________ ________
997 KING
SQL>
(2)c.EMPをalter table moveし、高速リフレッシュ
ソースPDB(k3)のc.EMPをalter table moveし、ROWIDを全て更新する。合わせて索引もリビルドする。これは典型的な表の断片化解消のシナリオである。
SQL> conn c/c@k3
Connected.
SQL> select empno,ename,rowid from emp where empno in (1,2,3,101,102,103,201,202,203);
EMPNO ENAME ROWID
________ ________ _____________________
201 ZZZ AAASCEAASAAAFbtAAA
202 ZZZ AAASCEAASAAAFbtAAB
203 ZZZ AAASCEAASAAAFbtAAC
SQL> alter table emp move;
select empno,ename,rowid from emp where empno in (1,2,3,101,102,103,201,202,203);
Table EMP altered.
SQL> select empno,ename,rowid from emp where empno in (1,2,3,101,102,103,201,202,203);
EMPNO ENAME ROWID
________ ________ _____________________
201 ZZZ AAASCiAASAAAFbzAAB
202 ZZZ AAASCiAASAAAFbzAAC
203 ZZZ AAASCiAASAAAFbzAAD
select index_name,status from user_indexes where index_name like '%EMP%';
SQL> select index_name,status from user_indexes where index_name like '%EMP%';
INDEX_NAME STATUS
_______________________ ___________
SYS_C_SNAP$_23PK_EMP VALID
I_MLOG$_EMP VALID
IDX1_EMP UNUSABLE
PK_EMP UNUSABLE
alter index pk_emp rebuild;
SQL> alter index pk_emp rebuild;
Index PK_EMP altered.
SQL> alter index idx1_emp rebuild;
Index IDX1_EMP altered.
SQL> select index_name,status from user_indexes where index_name like '%EMP%';
INDEX_NAME STATUS
_______________________ _________
SYS_C_SNAP$_23PK_EMP VALID
PK_EMP VALID
IDX1_EMP VALID
I_MLOG$_EMP VALID
ターゲットPDB(k5)にて、高速リフレッシュを実行する。高速リフレッシュはORA-12034エラーとなる。完全リフレッシュにより、正しい同期状態にすることができていることがわかる。
SQL> conn f/f@k5
Connected.
SQL> select empno,ename,rowid from mf_emp_union where empno in (1,2,3,101,102,103,201,202,203);
EMPNO ENAME ROWID
________ _____________ _____________________
1 WANOZRAMAP AAASBTAAWAAAAD7AAA
2 GMREPEQFIN AAASBTAAWAAAAD7AAB
3 SKWBNXLCNF AAASBTAAWAAAAD7AAC
101 GVXUEOOQJM AAASBTAAWAAAAD7ABk
102 XGLASIZISR AAASBTAAWAAAAD7ABl
103 UVODELRDCI AAASBTAAWAAAAD7ABm
201 ZZZ AAASBTAAWAAAAD9ACA
202 ZZZ AAASBTAAWAAAAD9ABk
203 ZZZ AAASBTAAWAAAAD9AC4
9 rows selected.
SQL> EXECUTE DBMS_MVIEW.REFRESH('mf_emp_union', 'f'); --★高速リフレッシュ
Error starting at line : 1 in command -
BEGIN DBMS_MVIEW.REFRESH('mf_emp_union', 'f'); END;
Error report -
ORA-12034: materialized view log on "C"."EMP" younger than last refresh
ORA-06512: at "SYS.DBMS_SNAPSHOT_KKXRCA", line 3020
ORA-06512: at "SYS.DBMS_SNAPSHOT_KKXRCA", line 2432
ORA-06512: at "SYS.DBMS_SNAPSHOT_KKXRCA", line 88
ORA-06512: at "SYS.DBMS_SNAPSHOT_KKXRCA", line 253
ORA-06512: at "SYS.DBMS_SNAPSHOT_KKXRCA", line 2413
ORA-06512: at "SYS.DBMS_SNAPSHOT_KKXRCA", line 2976
ORA-06512: at "SYS.DBMS_SNAPSHOT_KKXRCA", line 3263
ORA-06512: at "SYS.DBMS_SNAPSHOT_KKXRCA", line 3295
ORA-06512: at "SYS.DBMS_SNAPSHOT", line 16
ORA-06512: at line 1
12034. 0000 - "materialized view log on \"%s\".\"%s\" younger than last refresh"
*Cause: The materialized view log was younger than the last refresh.
*Action: A complete refresh is required before the next fast refresh.
SQL> EXECUTE DBMS_MVIEW.REFRESH('mf_emp_union', 'c'); --★完全リフレッシュ
PL/SQL procedure successfully completed.
SQL> select empno,ename,rowid from mf_emp_union where empno in (1,2,3,101,102,103,201,202,203);
EMPNO ENAME ROWID
________ _____________ _____________________
1 WANOZRAMAP AAASBTAAWAAAAD8ABo
2 GMREPEQFIN AAASBTAAWAAAAD8ABp
3 SKWBNXLCNF AAASBTAAWAAAAD8ABq
101 GVXUEOOQJM AAASBTAAWAAAAD8ABm
102 XGLASIZISR AAASBTAAWAAAAD8ABn
103 UVODELRDCI AAASBTAAWAAAAD9AAA
201 ZZZ AAASBTAAWAAAAD7ABr
202 ZZZ AAASBTAAWAAAAD7ABs
203 ZZZ AAASBTAAWAAAAD7ABt
9 rows selected.
(3)c.EMPをトランケートし、高速リフレッシュ
ソースPDB(k3)のc.EMPをトランケートで全件削除する。
SQL> conn c/c@k3 Connected. SQL> truncate table emp; Table EMP truncated.
ターゲットPDB(k5)にて、高速リフレッシュを実行する。高速リフレッシュはORA-12034エラーとなる。完全リフレッシュにより、正しい同期状態にすることができていることがわかる。
SQL> conn f/f@k5
Connected.
SQL> select empno,ename from mf_emp_union where empno in (1,2,3,101,102,103,201,202,203);
EMPNO ENAME
1 WANOZRAMAP
2 GMREPEQFIN
3 SKWBNXLCNF
101 GVXUEOOQJM
102 XGLASIZISR
103 UVODELRDCI
201 ZZZ
202 ZZZ
203 ZZZ
9 rows selected.
SQL> EXECUTE DBMS_MVIEW.REFRESH('mf_emp_union', 'f'); --★高速リフレッシュ
Error starting at line : 1 in command -
BEGIN DBMS_MVIEW.REFRESH('mf_emp_union', 'f'); END;
Error report -
ORA-12034: materialized view log on "C"."EMP" younger than last refresh
ORA-06512: at "SYS.DBMS_SNAPSHOT_KKXRCA", line 3020
ORA-06512: at "SYS.DBMS_SNAPSHOT_KKXRCA", line 2432
ORA-06512: at "SYS.DBMS_SNAPSHOT_KKXRCA", line 88
ORA-06512: at "SYS.DBMS_SNAPSHOT_KKXRCA", line 253
ORA-06512: at "SYS.DBMS_SNAPSHOT_KKXRCA", line 2413
ORA-06512: at "SYS.DBMS_SNAPSHOT_KKXRCA", line 2976
ORA-06512: at "SYS.DBMS_SNAPSHOT_KKXRCA", line 3263
ORA-06512: at "SYS.DBMS_SNAPSHOT_KKXRCA", line 3295
ORA-06512: at "SYS.DBMS_SNAPSHOT", line 16
ORA-06512: at line 1
12034. 0000 - "materialized view log on \"%s\".\"%s\" younger than last refresh"
*Cause: The materialized view log was younger than the last refresh.
*Action: A complete refresh is required before the next fast refresh.
SQL> EXECUTE DBMS_MVIEW.REFRESH('mf_emp_union', 'c'); --★完全リフレッシュ
PL/SQL procedure successfully completed.
SQL> select empno,ename from mf_emp_union where empno in (1,2,3,101,102,103,201,202,203);
EMPNO ENAME
________ _____________
1 WANOZRAMAP
2 GMREPEQFIN
3 SKWBNXLCNF
101 GVXUEOOQJM
102 XGLASIZISR
103 UVODELRDCI
6 rows selected.
4.まとめ
今回の調査、検証を踏まえ、明らかになったことはは以下の通り。
- UNION ALLで複数表をまとめたMVIEWを作成することは可能
- 高速リフレッシュを使うには、MLOGにROWIDを含め、かつ表の定義にROWIDおよびマーカーを追加する必要がある
- ソース表でROWIDを変更する操作(例えば、ソース表の断片化解消のためのMOVEやインポートなど)をすると、高速リフレッシュはエラーとなる(完全リフレッシュが必要)
- トランケートをすると、高速リフレッシュはエラーとなる(完全リフレッシュが必要)
MLOGおよびMVIEWにROWIDを含める必要があるという制約は、UNION ALLを使うMVIEWではソースの行をPKだけでは特定できないからと思われる(複数のソース表の主キーの重複が想定されるため)。
なお、今回検証結果は示していないが、MVIEW側でPKを定義すると、重複データが発生した場合にMVIEWのリフレッシュが一意制約違反で失敗するようにすることもできる。復旧のためには、重複データを特定しソース側で削除した後、完全リフレッシュが必要であることは言うまでもない。
参考
[1]Oracle Database データ・ウェアハウス・ガイド 19c
以上
2023-05-16 06:58
コメント(0)
Oracle 23c freeのオプティマイザ関連パラメータを調べる [オプティマイザ]
1.はじめに
4/5未明のOracle ACE向けアナウンスで、オラクル社のGerald Venzl氏からOracle Database 23c Freeがリリースされたとの説明があった(参考[1])。これは開発者向けの無償版で、従来Xeと呼ばれていたものに相当するそうだ。正式な23cは現在ベータテスト中である中、開発者向けを無償で先にリリースするのは、23cのDeveloper firstの姿勢の本気度を感じさせられる。RACやDataGuardのような機能は使えないが、JSON等の新機能を試したりすることができるのは開発者に取って朗報だろう。正式なサポートはないが、Oracle Forumにスレッドがあるので活用するとよいだろう(参考[2])。
23cのリリースでまず一番私が確認したかったのは、オプティマイザに影響を与えるパラメータである。デフォルト値が変更されたものや、新機能として追加されたものを把握することは、いずれ必要となる19cからの移行作業で必ず必要となるためである。本稿では、23cのオプティマイザ関連のパラメータについて、その調査方法と結果ついて共有したい。
なお、Oracle Database 23c Freeの導入方法については、すでに日本語で紹介したブログもあるので、ここで特筆する必要はないだろう。ちなみに、私はVirtual Box VMのイメージを使ったが、特段難しいことはなく利用することができた。
2.オプティマイザのパラメータ確認方法
オプティマイザに影響を与えるパラメータの確認方法はいくつかあるが、私が個人的に最も信頼しているのは10053トレースである。10053トレースの取得方法は以下の通り。今回の場合SQLはなんでも良いので、select 1 from dualとした。
-- to enable the 10053 trace alter session set events '10053 trace name context forever'; execute any SQL -- stop tracing alter session set events '10053 trace name context off';
結果は以下のようにtraceディレクトリ配下にSID_ora_PID.trcという名前で出力される。
[oracle@localhost trace]$ ls -ltr /opt/oracle/diag/rdbms/free/FREE/trace/ | tail -rw-r-----. 1 oracle oinstall 7077 Apr 5 20:23 FREE_dbrm_1924.trm -rw-r-----. 1 oracle oinstall 37378 Apr 5 20:23 FREE_dbrm_1924.trc -rw-r-----. 1 oracle oinstall 68439 Apr 5 20:23 FREE_ora_12524.trm -rw-r-----. 1 oracle oinstall 126447 Apr 5 20:23 FREE_ora_12524.trc ★ -rw-r-----. 1 oracle oinstall 1731 Apr 5 20:27 FREE_gcr2_12649.trm
トレースファイルの中を確認すると、以下のようにPARAMETERS USED BY THE OPTIMIZERというセクションがあり、そこにオプティマイザに影響を与える(隠し)初期化パラメータが出力される。PARAMETERS WITH ALTERED VALUESはデフォルト値から変更されたパラメータ、PARAMETERS WITH DEFAULT VALUESはデフォルト値から変更のないパラメータを表す。
Trace file /opt/oracle/diag/rdbms/free/FREE/trace/FREE_ora_12524.trc Oracle Database 23c Free, Release 23.0.0.0.0 - Developer-Release Version 23.2.0.0.0 ... *************************************** PARAMETERS USED BY THE OPTIMIZER ******************************** ************************************* PARAMETERS WITH ALTERED VALUES ****************************** Compilation Environment Dump _swat_ver_mv_knob = 0 Bug Fix Control Environment ************************************* PARAMETERS WITH DEFAULT VALUES ****************************** Compilation Environment Dump optimizer_mode_hinted = false optimizer_features_hinted = 0.0.0 parallel_execution_enabled = false parallel_query_forced_dop = 0 parallel_dml_forced_dop = 0 parallel_ddl_forced_degree = 0 parallel_ddl_forced_instances = 0 _query_rewrite_fudge = 90 optimizer_features_enable = 23.1.0
多くの初期化パラメータは_(アンダースコア)が接頭辞となる隠しパラメータであり、マニュアルには記載されていない。このため、以下のSQLでそれぞれのパラメータの説明を取得する(x$ksppi.ksppdescに初期化パラメータの説明がある)。簡単な説明しかないものの、概ねどのような機能を持つのかくらいのことはわかるだろう。
set markup csv on
spool /tmp/initparam19c.csv
SELECT a.ksppinm "Parameter", b.KSPPSTDF "Default Value", a.KSPPDESC "DESCRIPTION",
b.ksppstvl "Session Value",
c.ksppstvl "Instance Value",
decode(bitand(a.ksppiflg/256,1),1,'TRUE','FALSE') IS_SESSION_MODIFIABLE,
decode(bitand(a.ksppiflg/65536,3),1,'IMMEDIATE',2,'DEFERRED',3,'IMMEDIATE','FALSE') IS_SYSTEM_MODIFIABLE
FROM x$ksppi a,
x$ksppcv b,
x$ksppsv c
WHERE a.indx = b.indx
AND a.indx = c.indx
order by 1
/
3.取得結果
上記の確認方法を使って、Oracle Database 23c Freeと、Oracle 19.11.0(EE)とで比較を行った。比較結果の詳細を確認したい場合は、参考[3]を参照されたい。ここでは主な変更点について記載しておきたい。
まず全体のパラメータ数は、23cが658個に対して、19cは613個と45増えている。具体的には以下の通り、23cの新規パラメータは46個あり、19cにあって23cにないパラメータが1つ存在した。19cからの移行においては、新しいオプティマイザの機能追加が想定しない挙動(実行計画)となる可能性があるため、必要に応じて見直しする対象となるだろう(具体的には値がtrueとなっているものは、機能を無効とするためにfalseに変更するといった対処など)。
◇23cのオプティマイザ関連の新規パラメータ
| # | 23.2.0 | value | description |
| 10 | _ansi_join_mv_rewrite_enabled | true | enable/disable ansi join mv rewrite |
| 17 | _autoptn_costing | false | DBMS_AUTO_PARTITION is compiling query for cost estimates |
| 40 | _cell_index_scan_enabled | true | enable CELL processing of index FFS |
| 41 | _cell_iot_scan_enabled | true | enable CELL processing of IOT FFS |
| 44 | _cell_metadata_compression | AUTO | Cell metadata compression strategy |
| 62 | _cross_con_remove_pushed_preds | false | remove pushed predicates from query fetching across containers |
| 82 | _enable_columnar_cache | 1 | enable 12g bigfile tablespace |
| 109 | _groupby_orderby_combine | 5000 | groupby/orderby don't combine threshold |
| 123 | _inmemory_hpk4sql_flags | 0 | In-Memory HPK4SQL flags |
| 129 | _json_qryovergen_rewrite | true | enable/disable JSON query over generation function rewrite |
| 160 | _obsolete_result_cache_mode | MANUAL | USERS SHOULD NOT SET THIS! Used for old qksced parameterof result_cache_mode |
| 232 | _optimizer_exists_to_any_rewrite | true | consider exists-to-any rewrite of subqueries |
| 286 | _optimizer_nested_loop_join | on | favor/unfavor nested loop join |
| 303 | _optimizer_push_gby_into_union_all | true | consider pushing down group-by into union-all branches |
| 323 | _optimizer_subsume_vw_sq | on | consider subsumption of views or subqueries |
| 341 | _optimizer_use_stats_models | false | use optimizer statistics extrapolation models |
| 353 | _optimizer_wc_filter_pushdown | true | enable/disable with clause filter predicate pushdown |
| 387 | _px_adaptive_dist_nij_enabled | on | enable adaptive distribution methods for left non-inner joins |
| 399 | _px_extended_join_skew_handling | true | enables extended skew handling for parallel joins |
| 424 | _px_parallelize_non_native_datatype | true | enable parallelization for non-native datatypes |
| 427 | _px_partition_load_skew_handling | on | enable partition load skew handling |
| 428 | _px_partition_load_skew_threshold | 3 | partition loads bigger than threshold times average are skewed |
| 446 | _px_window_skew_handling | true | enable window function skew handling |
| 447 | _qa_lrg_type | 0 | Oracle internal parameter to specify QA lrg type |
| 491 | _rowsets_use_work_heap_buffer | true | allow/disallow use of work heap buffer for values for rowsets |
| 497 | _slave_mapping_skew_handling | true | enables skew handling for slave mapping plans |
| 516 | _sqlexec_hash_based_distagg_ser_civ_enabled | true | enable hash based distinct aggregation in serial/CIV queries |
| 518 | _sqlexec_hash_based_set_operation_enabled | true | enable/disable hash based set operation |
| 519 | _sqlexec_hash_rollup_enabled | true | enable hash rollup |
| 523 | _sqlexec_use_delayed_unpacking | true | enable/disable the usage of delayed unpacking |
| 526 | _sqlexec_window_function_settings | 63 | execution settings for window functions |
| 531 | _swat_ver_mv_knob | 0 | Knob to control MV/REWRITE behavior |
| 542 | _use_dirty_reads | 0 | enable the use of column statistics for DDP functions |
| 553 | _zonemap_refresh_within_load | true | Control the refresh of basic zonemaps during/after data load |
| 574 | escrow_dirty_cursor | 0 | whether to encrypt newly created tablespaces |
| 575 | escrow_internal_cursor | 0 | whether to encrypt newly created tablespaces |
| 578 | group_by_position_enabled | false | enable/disable group by position |
| 579 | gwr_trigger_enabled | 0 | enable/disable group by position |
| 589 | json_expression_check | off | enable/disable JSON query statement check |
| 591 | memoptimize_writes | HINT | write data to IGA without memoptimize_write hint |
| 597 | optimizer_cross_shard_resiliency | false | enables resilient execution of cross shard queries |
| 614 | optimizer_use_sql_quarantine | true | enable use of sql quarantine |
| 644 | shard_enable_raft_follower_read | true | enable read from follower replications units in a shard |
| 645 | shard_queries_restricted_by_key | false | add shard key predicates to the query |
| 656 | translate_table_name_hash | 0 | number of active transactions per rollback segment |
| 658 | valid_shard_session_key | 0 | User process dump directory |
◇23cで廃止されたオプティマイザ関連の新規パラメータ
| 19.11.0 | value | description |
| _optimizer_quarantine_sql | true | enable use of sql quarantine |
次に、同じパラメータであるが値が異なるものを調べたところ、27個あった。この27のうち、19cで私が意図的に変更したものや、バージョンや環境に依存するもの(CPU数やメモリサイズ等)を除くと、以下の4つのパラメータが残った。これらデフォルト値が変わっているものもオプティマイザの挙動に影響を与えるため、移行時は留意する必要がある。
◇19cと23cでデフォルト値が変更されたオプティマイザ系パラメータ
| # | 23.2.0 | value | description |
| 36 | _cdb_special_old_xplan | false | display old-style plan for CDB special fixed table |
| 275 | _optimizer_key_vector_payload_dim_aggs | true | enables or disables dimension payloading of aggregates in VT |
| 515 | _sqlexec_hash_based_distagg_enabled | true | enable hash based distinct aggregation for gby queries |
| 626 | parallel_execution_enabled | false | policy used to compute the degree of parallelism (MANUAL/LIMITED/AUTO/ADAPTIVE) |
4.おわりに
本稿では23cのOracle Database Freeと、19.11.0(EE)のオプティマイザ関連パラメータを、10053トレースを取得し比較した。Developer EditionとEEではそもそも異なる設定もあるだろうし、そもそも23cのEE版はベータテスト中という状況であるので、この結果を直接どうこう議論できるものではないだろう。実際の移行においては、23cが正式にリリースされた後、同様の方法でオプティマイザの挙動に影響するパラメータを洗い出す必要があるだろう。それでも、23cと19cでどの程度の変更があるのかの感覚を掴むことはできたと思う。
以上
参考
[1]:Introducing Oracle Database 23c Free - Developer Release, Oracle Database Insider, Gerald Venzl
[2]:Oracle Database Free - Developer Release, Oracle Forum
[3]:オプティマイザ関連初期化パラメータの差分確認結果(23cと19c)(OptimizerParameter23vs19.xlsx)
2023-04-09 13:04
コメント(0)


