UTL_FILEがNLS_LANGで結果不正 [アーキテクチャ]
先日、業務チームからUTL_FILEで出力したファイルがおかしいという問い合わせがあった。調べてみると、最後の文字がなくなったり、不要な改行が追加されている部分があり、それも文字の種類によって規則性がある、というものであった。環境はOracle19c(Exadata)、データベースのキャラクタセットはJA16SJISである。
結論から言うと、この事象の原因はDBインスタンスを構成する各種プロセスのNLS_LANG環境変数がデフォルトのAMERICAN_AMERICA.US7ASCIIとなっていたことであった。DBサーバのoracleやgridユーザのNLS_LANGをSJISに設定し忘れた訳ではない。以下のように、Grid Infrastructure(GI)にNLS_LANGを設定することにより、当該事象は回避できた。この設定はOCRに書き込まれるので永続的、ただし反映にはインスタンスの再起動が必要である(マルチテナントの場合はPDBではなくコンテナの再起動が必要)。
srvctl setenv database -d dbname -t "NLS_LANG=Japanese_Japan.JA16SJIS"
さて、以下この事象についてもう少し詳しく記載する。UTL_FILEのマニュアルの以下の記述を読んでほしい(特に最後の一文)。
---
PL/SQL Packages and Types Reference, 255.2 UTL_FILE Operational Notes
UTL_FILE expects that files opened by UTL_FILE.FOPEN in text mode are encoded in the database character set. It expects that files opened by UTL_FILE.FOPEN_NCHAR in text mode are encoded in the UTF8 character set. If an opened file is not encoded in the expected character set, the result of an attempt to read the file is indeterminate. When data encoded in one character set is read and Globalization Support is told (such as by means of NLS_LANG) that it is encoded in another character set, the result is indeterminate. If NLS_LANG is set, it should therefore be the same as the database character set.
---
UTL_FILEを使う場合は、NLS_LANGはデータベースのキャラクタセットと一致させる必要がある。そうでない場合の結果は不定(indeterminate)ということである。つまりこれはUTL_FILEの仕様、ということになる。
問題は、ここでいうNLS_LANGとは何か、ということである。例えばsqlplusのクライアントがリスナー経由でDBサーバへ接続し、PL/SQLの無名ブロックでUTL_FILE.PUT_LINE等でファイル出力するケースを考えよう。この場合、実体としてはDBサーバ上のサーバプロセスがファイル出力するため、このサーバプロセスのNLS_LANGを指すと思われる。では、このNLS_LANGはどこから来るのだろうか。普通に考えるとクライアントからの接続要求はリスナーを経由し、リスナーがこのサーバプロセスを生成することから、このリスナーのNLS_LANGが引き継がれると考えられる。リスナーを起動するOSユーザがoracleユーザであれば、その環境変数に指定されたNLS_LANGであると考えられる。11gR2まではGIが無かったので、多くの場合はOSのoracleユーザのNLS_LANGにより、Oracleのプロセス群に設定されるNLS_LANGが決定されていたはずである。そのため、UTL_FILEの上記仕様の制限を意識する必要性はあまりなかったと思われる。
しかし、11gR2以降では話は異なる。多くの場合、DBインスタンスやリスナー等のDBリソースはGIにより管理される。DBインスタンスはsrvctlにより起動停止を制御し、リスナーはGIにより自動起動される。この場合注意が必要なのは、これらのプロセスは、oracleやgridユーザのNLS_LANGの設定如何にかかわらず、デフォルトではAMERICAN_AMERICA.US7ASCIIが設定されるということである。例えoracleユーザやgridユーザのNLS_LANGにJapanese_Japan.JA16SJISしても、DBインスタンスを構成するプロセス、リスナーはNLS_LANG=AMERICAN_AMERICA.US7ASCIIになる、ということである。この状態でUTL_FILEを使うと、上記制約に引っかかる、という訳である。
この事象の回避方法は、上記で述べたとおりsrvctl setenvでDB毎にNLS_LANGを設定するしかないだろう。DBインスタンスの再起動を伴うためそれなりにインパクトがあるが、受け入れるしかない。残念ながら、試した限りではsrvctl setenv listenerだけではこの事象は回避できない(もしかすると単純にリスナープロセスのNLS_LANGだけが原因、ということではないのかもしれない)。上記設定によりDBサーバのプロセス郡のNLS_LANGが変更されることに不安を覚えるかもしれないが、クライアント側に返却される結果についてはクライアント側のNLS_LANGに依存するため、DBサーバのNLS_LANGの影響を受けない。また、リスナー経由しないDB接続(DBサーバでoracleユーザから直接sqlplus / as sysdbaで接続するなど)は、サーバプロセスもoracleユーザで起動されるため、結果そのユーザのNLS_LANGが引き継がれるため影響を受けない。とはいえ、運用中のシステムに対しこれを変更するのは勇気がいることには変わりない。
なお、DBインスタンスを構成する各種バックグラウンドプロセスが出力するalert.logやトレースファイル、これらの文字コードや言語はNLS_LANGと一切関係なく、データベースキャラクタセットと初期化パラメータNLS_LANGUAGEに依存する。そう考えると、そもそもUTL_FILEが何故DBインスタンスを構成するプロセスのNLS_LANGに依存した作りになっているのか理解に苦しむ。単純にデータベースキャラクタセットと同じ文字コードでファイル出力する、という仕様にすれば良いだけの話である。特にエラーが出る訳でもなく、文字コードの組み合わせによっては事象が顕在化しない場合もあるため、顕在化した際の業務的なインパクトが計り知れない。せめて、設定の矛盾をalert.logに出力するなど、気付くきっかけくらいは考えてくれてもよいのではないか。そう考えると、このUTL_FILEの仕様は極めて不親切であり、どちらかというと、ワークアラウンドが確立されたため修正される見込みのない不具合ではないか、という気すらする。
今回の件を通し、先のUTL_FILEの仕様を読み、それを咀嚼してOracleの環境設計に取り込めるOracle技術者はどれほど存在するだろうか、と考えさせられた。このUTL_FILEの仕様は古く9i時代にさかのぼるらしいが、11gR2からのGIの登場によりより問題として顕在化し易くなったのではないだろうか。世の中的にはあるあるネタで知っている人は多いかもしれないが、少し不安に思った方は自分の身を守るために今一度ご自身の環境をチェックされては如何だろうか。
以上
結論から言うと、この事象の原因はDBインスタンスを構成する各種プロセスのNLS_LANG環境変数がデフォルトのAMERICAN_AMERICA.US7ASCIIとなっていたことであった。DBサーバのoracleやgridユーザのNLS_LANGをSJISに設定し忘れた訳ではない。以下のように、Grid Infrastructure(GI)にNLS_LANGを設定することにより、当該事象は回避できた。この設定はOCRに書き込まれるので永続的、ただし反映にはインスタンスの再起動が必要である(マルチテナントの場合はPDBではなくコンテナの再起動が必要)。
srvctl setenv database -d dbname -t "NLS_LANG=Japanese_Japan.JA16SJIS"
さて、以下この事象についてもう少し詳しく記載する。UTL_FILEのマニュアルの以下の記述を読んでほしい(特に最後の一文)。
---
PL/SQL Packages and Types Reference, 255.2 UTL_FILE Operational Notes
UTL_FILE expects that files opened by UTL_FILE.FOPEN in text mode are encoded in the database character set. It expects that files opened by UTL_FILE.FOPEN_NCHAR in text mode are encoded in the UTF8 character set. If an opened file is not encoded in the expected character set, the result of an attempt to read the file is indeterminate. When data encoded in one character set is read and Globalization Support is told (such as by means of NLS_LANG) that it is encoded in another character set, the result is indeterminate. If NLS_LANG is set, it should therefore be the same as the database character set.
---
UTL_FILEを使う場合は、NLS_LANGはデータベースのキャラクタセットと一致させる必要がある。そうでない場合の結果は不定(indeterminate)ということである。つまりこれはUTL_FILEの仕様、ということになる。
問題は、ここでいうNLS_LANGとは何か、ということである。例えばsqlplusのクライアントがリスナー経由でDBサーバへ接続し、PL/SQLの無名ブロックでUTL_FILE.PUT_LINE等でファイル出力するケースを考えよう。この場合、実体としてはDBサーバ上のサーバプロセスがファイル出力するため、このサーバプロセスのNLS_LANGを指すと思われる。では、このNLS_LANGはどこから来るのだろうか。普通に考えるとクライアントからの接続要求はリスナーを経由し、リスナーがこのサーバプロセスを生成することから、このリスナーのNLS_LANGが引き継がれると考えられる。リスナーを起動するOSユーザがoracleユーザであれば、その環境変数に指定されたNLS_LANGであると考えられる。11gR2まではGIが無かったので、多くの場合はOSのoracleユーザのNLS_LANGにより、Oracleのプロセス群に設定されるNLS_LANGが決定されていたはずである。そのため、UTL_FILEの上記仕様の制限を意識する必要性はあまりなかったと思われる。
しかし、11gR2以降では話は異なる。多くの場合、DBインスタンスやリスナー等のDBリソースはGIにより管理される。DBインスタンスはsrvctlにより起動停止を制御し、リスナーはGIにより自動起動される。この場合注意が必要なのは、これらのプロセスは、oracleやgridユーザのNLS_LANGの設定如何にかかわらず、デフォルトではAMERICAN_AMERICA.US7ASCIIが設定されるということである。例えoracleユーザやgridユーザのNLS_LANGにJapanese_Japan.JA16SJISしても、DBインスタンスを構成するプロセス、リスナーはNLS_LANG=AMERICAN_AMERICA.US7ASCIIになる、ということである。この状態でUTL_FILEを使うと、上記制約に引っかかる、という訳である。
この事象の回避方法は、上記で述べたとおりsrvctl setenvでDB毎にNLS_LANGを設定するしかないだろう。DBインスタンスの再起動を伴うためそれなりにインパクトがあるが、受け入れるしかない。残念ながら、試した限りではsrvctl setenv listenerだけではこの事象は回避できない(もしかすると単純にリスナープロセスのNLS_LANGだけが原因、ということではないのかもしれない)。上記設定によりDBサーバのプロセス郡のNLS_LANGが変更されることに不安を覚えるかもしれないが、クライアント側に返却される結果についてはクライアント側のNLS_LANGに依存するため、DBサーバのNLS_LANGの影響を受けない。また、リスナー経由しないDB接続(DBサーバでoracleユーザから直接sqlplus / as sysdbaで接続するなど)は、サーバプロセスもoracleユーザで起動されるため、結果そのユーザのNLS_LANGが引き継がれるため影響を受けない。とはいえ、運用中のシステムに対しこれを変更するのは勇気がいることには変わりない。
なお、DBインスタンスを構成する各種バックグラウンドプロセスが出力するalert.logやトレースファイル、これらの文字コードや言語はNLS_LANGと一切関係なく、データベースキャラクタセットと初期化パラメータNLS_LANGUAGEに依存する。そう考えると、そもそもUTL_FILEが何故DBインスタンスを構成するプロセスのNLS_LANGに依存した作りになっているのか理解に苦しむ。単純にデータベースキャラクタセットと同じ文字コードでファイル出力する、という仕様にすれば良いだけの話である。特にエラーが出る訳でもなく、文字コードの組み合わせによっては事象が顕在化しない場合もあるため、顕在化した際の業務的なインパクトが計り知れない。せめて、設定の矛盾をalert.logに出力するなど、気付くきっかけくらいは考えてくれてもよいのではないか。そう考えると、このUTL_FILEの仕様は極めて不親切であり、どちらかというと、ワークアラウンドが確立されたため修正される見込みのない不具合ではないか、という気すらする。
今回の件を通し、先のUTL_FILEの仕様を読み、それを咀嚼してOracleの環境設計に取り込めるOracle技術者はどれほど存在するだろうか、と考えさせられた。このUTL_FILEの仕様は古く9i時代にさかのぼるらしいが、11gR2からのGIの登場によりより問題として顕在化し易くなったのではないだろうか。世の中的にはあるあるネタで知っている人は多いかもしれないが、少し不安に思った方は自分の身を守るために今一度ご自身の環境をチェックされては如何だろうか。
以上
exadataと遅延ブロッククリーンアウトとシングルブロックリード [アーキテクチャ]
exadataにおいて、フルスキャンで読み取り一貫性を発生させない(つまりUNDOへの読み込みを発生させない)ことが遅延対策のポイントになるのは言うまでも無いが、それ以外にも遅延ブロッククリーンアウトが遅延の原因となるケースに遭遇したのでメモしておく。
事象としては、1GB程度のテーブルをcsvに出力する処理(夜間バッチ)が50分(SQLレポートのelapsed time)かかったのである。クエリは単純な1テーブルへアクセスするもので母体の件数は600万件、WHERE句でフラグでフィルタしているので、出力は500万件程度。SQLトレースを取得すると、大量のシングルブロックリード(20GB以上)が発生しており、ASHからUNDO表領域へのアクセスであることが判明した。日中帯に同じSQLを実行したら16秒程度(sqlplusからautotrace traceonlyで測定)で完了する。このときスマートスキャンが発生していた(SQLトレースから確認)していたため、通常であればそもそもシングルブロックリードが発生するはずがない。このテーブルは事前にトランケート・インサートされた後にこのクエリが走るだけで、他のトランザクションはないため、読み取り一貫性によるUNDOへのアクセスが発生していた可能性はない。しかも母体のテーブルサイズをはるかに上回るUNDO量である。これは一体どういうことか。。。
一般的なOracle(非Exadata)ではFTSはマルチブロックで読み込んだブロックに対して読み取り一貫性のため必要なUNDOを読み込みCRブロックを生成する。スマートスキャンの恩恵は受けられないが、IOはマルチブロックリードにより効率的に行われる。一方、exadataではFTSはスマートスキャンとなることがあり、その場合は各ストレージサーバへFTSの処理がオフロードされる。このとき、各ストレージサーバはCRブロックを返却する必要があるが、各ストレージサーバは各ブロックが「CRブロックである」ことを認識し、ストレージサーバ毎に独立してプレディケートフィルタやカラムプロジェクションを行うのである。しかし、「CRブロックでない」、つまり読み取り一貫性の為にUNDOを読み込む必要があると、ストレージサーバはスマートスキャンを諦めてシングルブロックを返却する。そして、DBサーバ上のバッファキャッシュ上で必要なUNDOブロックを読み込み(シングルブロックリード)CRブロックを生成することを繰り返す。スマートスキャンの恩恵を受けるため、他トランザクションからの更新を避けるのはこのためである。
実はこの挙動は遅延ブロッククリーンアウトでも発生する。遅延ブロッククリーンアウトは、簡単に言うと最新化されていない未コミット状態のブロックをコミット時ではなく、後でコミット済みに変更するメカニズムである。これが発生すると、ブロック読み込み時に、そのブロックがコミット済みかどうかを確認するために、ITLに記録されるトランザクションID(xid)から、UNDOセグメントヘッダのトランザクション表へアクセスする。コミット済みであることが確認できれば、そのブロックのITLをコミットSCNとあわせてコミット済みに変更する。ブロックへの変更が発生するため、(たとえSELECTであっても)REDOが発生する。
また、UNDOセグメント毎のトランザクション表のスロット数はOracleのバージョンやオプションにより決まる(34,48,96個等)。また、1つのUNDO表領域上に作成できるUNDOセグメント数にも上限があることから、必然的にトランザクション表のスロットは上書きされてしまう。このため、コミット時のSCNを確認するため、トランザクション表への読み取り一貫性、つまりUNDOをたどって過去のSCNを確認するという挙動が発生することもある。これらUNDOへのアクセスは、すべてDBサーバからシングルブロックリードが必要である。
ストレージサーバはCRブロックであることをどのように判断するのだろうか。各ブロックのITLにはそのブロックにアクセスするトランザクション(xid)とその状態(コミット済みがどうか等)、コミット済みSCN、関連するUNDOブロックアドレスが記録されている。したがって、オフロードされたクエリのSCNがコミットSCNより新しければ、そのブロックはCRブロックと判別できるはずである。未コミットのトランザクションがある場合、またはコミット済みでもクエリのSCNがコミットSCNより古い場合はUNDOブロックを読む必要があるので、シングルブロックを返却する流れとなる。実際はもっと複雑な流れだとは思うが、おおまかにはこんなところだろう。
では、遅延ブロッククリーンアウトの状況ではどうだろうか。遅延ブロッククリーンアウトは、コミット済みであるにもかかわらず、ブロックは未コミット状態となっている状況である。上記ロジックが正しいとすれば、この状況は必ずUNDOの読み込みが必要となるため、スマートスキャンはできなく、シングルブロックを返却する流れとなることは容易に想像がつく。
遅延ブロッククリーンアウトが発生する要因の一つは、バッファキャッシュの枯渇である。未コミットのダーティブロックが、トランザクション完了(コミット)前にDBWRによりパージされてしまうと、トランザクション完了してもディスク上には未コミット状態のままとなる。このため、更新時のバッファキャッシュを増加させれば発生頻度を減らすことが可能である。もちろん、コミット間隔を小さくすることも対策として有効だろう。また、UNDOへのアクセスを減らすという意味では、トランザクション表(のスロット)が上書きされなければ、トランザクション表に対するUNDO読み込みは不要となる可能性があるため、更新直後に読み込む、という対処も有効なはずである。
あくまで仮設であるが、今回の遅延事象は、INSERT時(2000件単位でコンベンショナルINSERT・コミット)のバッファキャッシュ上のブロックが、他処理との並走によりバッファキャッシュが不足し、未コミット状態でディスクに反映されたものが増えた。また、コミット後からクエリまで2時間程度経過していたことから、トランザクション表が上書きされ、コミットSCNを確認するためにトランザクション表のUNDOを読み込む必要がある状態になっていた。このため、後続のフルスキャンで遅延ブロッククリーンアウトが発生し、UNDOへの読み込みが必要なことからスマートスキャンは効かず、UNDOへのシングルブロックリードを発生させたのではないか、と考えた。実際、バッファキャッシュを2倍程度に変更することで、50分かかっていたクエリが10秒以下にすることができた。簡単に2つの処理の違いを比べると、如何にExadataにおいて遅延ブロッククリーンアウトの際のオーバーヘッドが大きいかわかる。
◆通常のスマートスキャンの挙動
フルスキャン→ダイレクトパスリード→スマートスキャン(マルチブロックリード)→ストレージオフロードによりフィルタ済みブロックのみ返却→結果セット
◆遅延ブロッククリーンアウトの際の挙動
フルスキャン→ダイレクトパスリード→スマートスキャン→ITLが未コミットなのでシングルブロックで返却→UNDOセグメントヘッダ読み込み→コミットSCN確認のためトランザクション表のUNDO読み込み→コミットクリーンアウト→UNDO変更のREDOチェンジベクター生成→バッファキャッシュ上でフィルタ処理→結果セット
遅延ブロッククリーンアウトが発生したことを示すことは一般的に難しいとされる。今回はAWRやASHから得られる情報から消去法的に仮設を作り上げた。ただ、それでもなお、今回なぜこれだけの量のUNDOを読む必要があるのかまでは追いきれなかった。この事象を通して遅延ブロッククリーンアウトについて改めて理解を深めることができたのは、やはりJonathan Lewis氏のOracle Coreによることが大きい。Exadataや最新のOracleバージョンには記載はないが、根本のアーキテクチャは変わらないものである。
わかればわかるほど、わからないことを知る、ということを感じる今日この頃である。
以上
◆参考
")
事象としては、1GB程度のテーブルをcsvに出力する処理(夜間バッチ)が50分(SQLレポートのelapsed time)かかったのである。クエリは単純な1テーブルへアクセスするもので母体の件数は600万件、WHERE句でフラグでフィルタしているので、出力は500万件程度。SQLトレースを取得すると、大量のシングルブロックリード(20GB以上)が発生しており、ASHからUNDO表領域へのアクセスであることが判明した。日中帯に同じSQLを実行したら16秒程度(sqlplusからautotrace traceonlyで測定)で完了する。このときスマートスキャンが発生していた(SQLトレースから確認)していたため、通常であればそもそもシングルブロックリードが発生するはずがない。このテーブルは事前にトランケート・インサートされた後にこのクエリが走るだけで、他のトランザクションはないため、読み取り一貫性によるUNDOへのアクセスが発生していた可能性はない。しかも母体のテーブルサイズをはるかに上回るUNDO量である。これは一体どういうことか。。。
一般的なOracle(非Exadata)ではFTSはマルチブロックで読み込んだブロックに対して読み取り一貫性のため必要なUNDOを読み込みCRブロックを生成する。スマートスキャンの恩恵は受けられないが、IOはマルチブロックリードにより効率的に行われる。一方、exadataではFTSはスマートスキャンとなることがあり、その場合は各ストレージサーバへFTSの処理がオフロードされる。このとき、各ストレージサーバはCRブロックを返却する必要があるが、各ストレージサーバは各ブロックが「CRブロックである」ことを認識し、ストレージサーバ毎に独立してプレディケートフィルタやカラムプロジェクションを行うのである。しかし、「CRブロックでない」、つまり読み取り一貫性の為にUNDOを読み込む必要があると、ストレージサーバはスマートスキャンを諦めてシングルブロックを返却する。そして、DBサーバ上のバッファキャッシュ上で必要なUNDOブロックを読み込み(シングルブロックリード)CRブロックを生成することを繰り返す。スマートスキャンの恩恵を受けるため、他トランザクションからの更新を避けるのはこのためである。
実はこの挙動は遅延ブロッククリーンアウトでも発生する。遅延ブロッククリーンアウトは、簡単に言うと最新化されていない未コミット状態のブロックをコミット時ではなく、後でコミット済みに変更するメカニズムである。これが発生すると、ブロック読み込み時に、そのブロックがコミット済みかどうかを確認するために、ITLに記録されるトランザクションID(xid)から、UNDOセグメントヘッダのトランザクション表へアクセスする。コミット済みであることが確認できれば、そのブロックのITLをコミットSCNとあわせてコミット済みに変更する。ブロックへの変更が発生するため、(たとえSELECTであっても)REDOが発生する。
また、UNDOセグメント毎のトランザクション表のスロット数はOracleのバージョンやオプションにより決まる(34,48,96個等)。また、1つのUNDO表領域上に作成できるUNDOセグメント数にも上限があることから、必然的にトランザクション表のスロットは上書きされてしまう。このため、コミット時のSCNを確認するため、トランザクション表への読み取り一貫性、つまりUNDOをたどって過去のSCNを確認するという挙動が発生することもある。これらUNDOへのアクセスは、すべてDBサーバからシングルブロックリードが必要である。
ストレージサーバはCRブロックであることをどのように判断するのだろうか。各ブロックのITLにはそのブロックにアクセスするトランザクション(xid)とその状態(コミット済みがどうか等)、コミット済みSCN、関連するUNDOブロックアドレスが記録されている。したがって、オフロードされたクエリのSCNがコミットSCNより新しければ、そのブロックはCRブロックと判別できるはずである。未コミットのトランザクションがある場合、またはコミット済みでもクエリのSCNがコミットSCNより古い場合はUNDOブロックを読む必要があるので、シングルブロックを返却する流れとなる。実際はもっと複雑な流れだとは思うが、おおまかにはこんなところだろう。
では、遅延ブロッククリーンアウトの状況ではどうだろうか。遅延ブロッククリーンアウトは、コミット済みであるにもかかわらず、ブロックは未コミット状態となっている状況である。上記ロジックが正しいとすれば、この状況は必ずUNDOの読み込みが必要となるため、スマートスキャンはできなく、シングルブロックを返却する流れとなることは容易に想像がつく。
遅延ブロッククリーンアウトが発生する要因の一つは、バッファキャッシュの枯渇である。未コミットのダーティブロックが、トランザクション完了(コミット)前にDBWRによりパージされてしまうと、トランザクション完了してもディスク上には未コミット状態のままとなる。このため、更新時のバッファキャッシュを増加させれば発生頻度を減らすことが可能である。もちろん、コミット間隔を小さくすることも対策として有効だろう。また、UNDOへのアクセスを減らすという意味では、トランザクション表(のスロット)が上書きされなければ、トランザクション表に対するUNDO読み込みは不要となる可能性があるため、更新直後に読み込む、という対処も有効なはずである。
あくまで仮設であるが、今回の遅延事象は、INSERT時(2000件単位でコンベンショナルINSERT・コミット)のバッファキャッシュ上のブロックが、他処理との並走によりバッファキャッシュが不足し、未コミット状態でディスクに反映されたものが増えた。また、コミット後からクエリまで2時間程度経過していたことから、トランザクション表が上書きされ、コミットSCNを確認するためにトランザクション表のUNDOを読み込む必要がある状態になっていた。このため、後続のフルスキャンで遅延ブロッククリーンアウトが発生し、UNDOへの読み込みが必要なことからスマートスキャンは効かず、UNDOへのシングルブロックリードを発生させたのではないか、と考えた。実際、バッファキャッシュを2倍程度に変更することで、50分かかっていたクエリが10秒以下にすることができた。簡単に2つの処理の違いを比べると、如何にExadataにおいて遅延ブロッククリーンアウトの際のオーバーヘッドが大きいかわかる。
◆通常のスマートスキャンの挙動
フルスキャン→ダイレクトパスリード→スマートスキャン(マルチブロックリード)→ストレージオフロードによりフィルタ済みブロックのみ返却→結果セット
◆遅延ブロッククリーンアウトの際の挙動
フルスキャン→ダイレクトパスリード→スマートスキャン→ITLが未コミットなのでシングルブロックで返却→UNDOセグメントヘッダ読み込み→コミットSCN確認のためトランザクション表のUNDO読み込み→コミットクリーンアウト→UNDO変更のREDOチェンジベクター生成→バッファキャッシュ上でフィルタ処理→結果セット
遅延ブロッククリーンアウトが発生したことを示すことは一般的に難しいとされる。今回はAWRやASHから得られる情報から消去法的に仮設を作り上げた。ただ、それでもなお、今回なぜこれだけの量のUNDOを読む必要があるのかまでは追いきれなかった。この事象を通して遅延ブロッククリーンアウトについて改めて理解を深めることができたのは、やはりJonathan Lewis氏のOracle Coreによることが大きい。Exadataや最新のOracleバージョンには記載はないが、根本のアーキテクチャは変わらないものである。
わかればわかるほど、わからないことを知る、ということを感じる今日この頃である。
以上
◆参考
Oracle Core: Essential Internals for DBAs and Developers (Expert's Voice in Databases)
- 作者: Jonathan Lewis
- 出版社/メーカー: Apress
- 発売日: 2011/12/06
- メディア: ペーパーバック
REDOとUNDOその3 [アーキテクチャ]
前回に続きJonathan Lewis氏の著書、Oracle Coreの中のREDOとUNDOに関する部分をメモしておく。
REDOの単純さ
REDOは単純にREDOレコードのストリームを連続的に出力し、共有プールのREDOログバッファになるべく早く詰め込む。Oracleはこれをディスクに書き込まなければならないが、運用的な理由で小さなオンラインREDOログファイルに書き込む。オンラインREDOログファイルの数は限られているので、ラウンドロビンで再利用しなければならない。
オンラインREDOログファイルの内容を長い期間保護するために、アーカイブREDOログファイルにコピーを作成sる。一度REDOレコードがREDOログ(バッファ)に書き込まれたら、基本的にはインスタンスは再度これを読み込むことはなく、「書き込み、忘れる」アプローチというシンプルなメカニズムになっている。
ただ、1つだけ複雑な部分がある。REDOの生成の唯一のボトルネックは、REDOログバッファにREDOのコピーを書き込むところである。10gより前、すべてのセッションに対してREDOログバッファは1つしかなかった。これに対し、1つのセッションは短時間に大量のREDOレコードを生成するかもしれないし、複数セッションが並列に動いているかもしれない。
共有プールに排他制御の仕組みを作ることは簡単だ。redo allocation latchを使ってOracleがREDOログバッファの制御を行っていることはよく知られている。プロセスはこのラッチを獲得し始めてログバッファに書き込むことができるので、複数プロセスにより同じ共有プールの領域(ログバッファ)を上書きすることを防げる。しかし、たくさんのプロセスがあると、競合によりリソースを大量に使ったり(ラッチスピンによるCPUリソース)、ラッチ獲得に失敗した後のスリープが大量に発生したりすることが起こりうる。
古いOracleのバージョンでは、データベースはそれほど忙しくなくREDO生成量もずっと少なかったので、1つの変更=1つのレコード=1つの領域確保、といった方式でほとんどのシステムで十分だった。しかし、システムが大きくなり高い並列度で領域確保を行う要件を満たすためには(特にOLTPといったシステム)、よりスケーラブルな方式が必要となる。そこで、10gで新しいメカニズムである「プライベートREDO」と「インメモリUNDO」が登場したのである。
これにより、プロセスはトランザクション全体を通して、生成したすべてのチェンジベクターをプライベートなREDOログバッファのペアに格納することができるようになった。トランザクションが完了すると、プロセスはすべてのプライベートなREDOをパブリックなREDOログバッファにコピーする。このとき、従来のログバッファ処理に戻る。つまり、プロセスはトランザクション毎にパブリックのredo allocation latchを1回獲得すればよいことになる。
...
UNDOの複雑さ
UNDOはREDOより複雑である。特に重要なのは、いかなるプロセスもまだ見るべきでないデータ項目を隠すために、原則的には、いかなる時点のUNDOにアクセスする必要がある、ということである。この要件を効率的に満たすために、OracleはUNDOレコードをデータベース内の特別な表領域(UNDO表領域)に格納している。そして、プロセスが必要なUNDOレコードを見つけるには、どこを探せばよいかわかるように、UNDOレコードへのさまざまなポインタを維持している。UNDO情報をデータベース内の通常のデータファイルに格納する利点は、UNDOブロックも通常のブロックと全く同じようにバッファリングされ、書き込みされ、リカバリされるということである。UNDOを管理する基本的なコードは、他の通常のブロックを扱うコードと同じになるのである。
プロセスがUNDOレコードを読まなければならない理由は3つあるので、UNDO表領域上のポインタを手繰る方法も3通りある。これらは3章で詳しく述べるが、ここでは簡単に最も一般的な2つについて述べておく。
読み取り一貫性
まず、最も一般的なUNDOの利用方法は、読み取り一貫性である。UNDOの存在により、セッションはまだデータの新しい状態を見るべきでないときは、そのデータの古いバージョンを見ることができる。
読み取り一貫性の要件が意味するのは、ブロックは変更を取り消すためのUNDOレコードへのポインタを持っていなければならないということである。しかし、実際は膨大な数の変更を取り消す必要があるかもしれないし、1つのブロックが保持できるポインタ数にも限りがある。そこで、Oracleは各ブロックに決められた数のポインタ(ブロックに関与する並列トランザクション毎に1つ)だけを保持し、これをブロックのITLエントリに格納する。プロセスがUNDOレコードを生成するとき、(通常)これらの中の1つのポインタを上書きし、前の値をUNDOレコードの一部として記録しておくのである。
あるUNDOレコードのブロックダンプを見ると、op: C uba: 0x0080009a.09d4.0dと記録されている部分がある。op: Cは、同じトランザクションによる前の更新の続きのレコードであることを示している。これによりOracleは、uba: 0x0080009a.09d4.0dがブロックの古いバージョンを作るために使う情報であることを知ることができる。このUNDOレコードに記録された更新前の情報をブロックの特定の行・カラムに反映すると共に、uba: 0x0080009a.09d4.0dをブロックのITLの特定のエントリに欠き戻す。
もちろん、Oracleはこのステップでブロックの古いバージョンを再構成した後、さらに古いバージョンが必要であると気がつくかもしれない。しかし、このブロックのITLスロットには、適用すべき次のUNDOレコードへのポインタがあり、そのUNDOレコードには更新前レコードの情報と共に、ITLエントリをさらにその前の状態にするための情報が含まれているのである。
ロールバック
次に、UNDOがよく使われるケースがロールバックである。具体的には、明示的なロールバック(セーブポイントへも含む)やトランザクションの途中で何らかのエラーが発生し、Oracleが暗黙的にステートメントレベルのロールバックを行うというケースである。
読み取り一貫性はシングルブロック、つまりあるブロックに対して関連するUNDOレコードをリンクされたリストから探す処理である。これに対し、ロールバックトランザクションの履歴、つまりトランザクションの実行(逆)順にUNDOレコードをリンクされたリストから探す処理である。
UNDOレコードを見てみると、リンクされたリストの痕跡があることがわかる。ダンプにあるエントリrci 0x0eの部分である。これは、このUNDOレコードの直前に生成されたUNDOレコードは同じUNDOブロック内の14番目(0x0e)にあることを示している。もちろん、直前のレコードが別のブロックにある可能性はある。その場合はrciエントリは0となり、rdba:エントリがその前のブロックアドレスを示す。前のブロックに戻る場合、通常はそのブロックの最終レコードが要求されるレコードである。もっとも、技術的にはirb:エントリによりレコードは特定することができる。しかし、irb:エントリが最後のレコードを指さない場合は、rollback to savepointした場合である。
読み取り一貫性とロールバックには重要な違いがある。読み取り一貫性は、データブロックのコピーをメモリ上に作成し、UNDOレコードを適用する。そしてこれは使い終わったらすぐに削除してしまってかまわないコピーなのである。しかしロールバックでは、カレントブロックを獲得しそれにUNDOレコードを適用する。これには3つの重要な効果がある。
・データブロックはカレントブロックであること。すなわち、最終的にはディスクに記録されなければならないブロックのバージョンである
・カレントブロックであるので、この変更にはREDOが生成される(たとえそれが元に戻す変更だとしても)
・Oracleのクラッシュリカバリのメカニズムにより安全に障害をリカバリするために、UNDOレコードを適用しながら「UNDO適用済み」とマークしていく必要がある。これによりさらにREDOが生成される。
ロールバックは大変な作業である。また、元の変更にかけたトランザクションと同じくらいの時間がかかり、REDOも同程度生成される可能性がある。ここで覚えておかなければならないのは、ロールバックはデータブロックを変更する作業であるということだ。つまり、ブロックを再び獲得し、変更し、書き込み、REDOにその変更を書き込む必要がある。さらに、もしトランザクションが大きく時間のかかるものであれば、いくつかのブロックはキャッシュから溢れてディスクへ書き込まれてしまうかもしれない。ロールバックするには、再びそれらをディスクから読み込まなければならないだろう!
他にもロールバックにより発生するオーバーヘッドがある。セッションがUNDOレコードを生成するとき、あるUNDOブロックを獲得し、pinし、それを埋めていく。ロールバックするときは、UNDOブロックから一度に1レコードずつ取り出す。つまり、1レコードずつ、ブロックの開放と獲得を繰り返すのである。これにより、初期の変更よりロールバックのときの方が、UNDOブロックに対するバッファアクセスが多くなる。しかも、OracleがUNDOレコードを獲得する際、毎回UNDO表領域がONLINEであるか調べる。これがdictionary cache(具体的にはdc_tablespaceキャッシュ)へのgetとして現れる。
---
実際の本には上記の内容に加えてブロックダンプや図があるので、もっと理解し易いと思う。また、UNDOの3つ目の使い方~遅延ブロッククリーンアウト~については、機会があれば紹介したいと思う。
◆参考文献
")
REDOの単純さ
REDOは単純にREDOレコードのストリームを連続的に出力し、共有プールのREDOログバッファになるべく早く詰め込む。Oracleはこれをディスクに書き込まなければならないが、運用的な理由で小さなオンラインREDOログファイルに書き込む。オンラインREDOログファイルの数は限られているので、ラウンドロビンで再利用しなければならない。
オンラインREDOログファイルの内容を長い期間保護するために、アーカイブREDOログファイルにコピーを作成sる。一度REDOレコードがREDOログ(バッファ)に書き込まれたら、基本的にはインスタンスは再度これを読み込むことはなく、「書き込み、忘れる」アプローチというシンプルなメカニズムになっている。
ただ、1つだけ複雑な部分がある。REDOの生成の唯一のボトルネックは、REDOログバッファにREDOのコピーを書き込むところである。10gより前、すべてのセッションに対してREDOログバッファは1つしかなかった。これに対し、1つのセッションは短時間に大量のREDOレコードを生成するかもしれないし、複数セッションが並列に動いているかもしれない。
共有プールに排他制御の仕組みを作ることは簡単だ。redo allocation latchを使ってOracleがREDOログバッファの制御を行っていることはよく知られている。プロセスはこのラッチを獲得し始めてログバッファに書き込むことができるので、複数プロセスにより同じ共有プールの領域(ログバッファ)を上書きすることを防げる。しかし、たくさんのプロセスがあると、競合によりリソースを大量に使ったり(ラッチスピンによるCPUリソース)、ラッチ獲得に失敗した後のスリープが大量に発生したりすることが起こりうる。
古いOracleのバージョンでは、データベースはそれほど忙しくなくREDO生成量もずっと少なかったので、1つの変更=1つのレコード=1つの領域確保、といった方式でほとんどのシステムで十分だった。しかし、システムが大きくなり高い並列度で領域確保を行う要件を満たすためには(特にOLTPといったシステム)、よりスケーラブルな方式が必要となる。そこで、10gで新しいメカニズムである「プライベートREDO」と「インメモリUNDO」が登場したのである。
これにより、プロセスはトランザクション全体を通して、生成したすべてのチェンジベクターをプライベートなREDOログバッファのペアに格納することができるようになった。トランザクションが完了すると、プロセスはすべてのプライベートなREDOをパブリックなREDOログバッファにコピーする。このとき、従来のログバッファ処理に戻る。つまり、プロセスはトランザクション毎にパブリックのredo allocation latchを1回獲得すればよいことになる。
...
UNDOの複雑さ
UNDOはREDOより複雑である。特に重要なのは、いかなるプロセスもまだ見るべきでないデータ項目を隠すために、原則的には、いかなる時点のUNDOにアクセスする必要がある、ということである。この要件を効率的に満たすために、OracleはUNDOレコードをデータベース内の特別な表領域(UNDO表領域)に格納している。そして、プロセスが必要なUNDOレコードを見つけるには、どこを探せばよいかわかるように、UNDOレコードへのさまざまなポインタを維持している。UNDO情報をデータベース内の通常のデータファイルに格納する利点は、UNDOブロックも通常のブロックと全く同じようにバッファリングされ、書き込みされ、リカバリされるということである。UNDOを管理する基本的なコードは、他の通常のブロックを扱うコードと同じになるのである。
プロセスがUNDOレコードを読まなければならない理由は3つあるので、UNDO表領域上のポインタを手繰る方法も3通りある。これらは3章で詳しく述べるが、ここでは簡単に最も一般的な2つについて述べておく。
読み取り一貫性
まず、最も一般的なUNDOの利用方法は、読み取り一貫性である。UNDOの存在により、セッションはまだデータの新しい状態を見るべきでないときは、そのデータの古いバージョンを見ることができる。
読み取り一貫性の要件が意味するのは、ブロックは変更を取り消すためのUNDOレコードへのポインタを持っていなければならないということである。しかし、実際は膨大な数の変更を取り消す必要があるかもしれないし、1つのブロックが保持できるポインタ数にも限りがある。そこで、Oracleは各ブロックに決められた数のポインタ(ブロックに関与する並列トランザクション毎に1つ)だけを保持し、これをブロックのITLエントリに格納する。プロセスがUNDOレコードを生成するとき、(通常)これらの中の1つのポインタを上書きし、前の値をUNDOレコードの一部として記録しておくのである。
あるUNDOレコードのブロックダンプを見ると、op: C uba: 0x0080009a.09d4.0dと記録されている部分がある。op: Cは、同じトランザクションによる前の更新の続きのレコードであることを示している。これによりOracleは、uba: 0x0080009a.09d4.0dがブロックの古いバージョンを作るために使う情報であることを知ることができる。このUNDOレコードに記録された更新前の情報をブロックの特定の行・カラムに反映すると共に、uba: 0x0080009a.09d4.0dをブロックのITLの特定のエントリに欠き戻す。
もちろん、Oracleはこのステップでブロックの古いバージョンを再構成した後、さらに古いバージョンが必要であると気がつくかもしれない。しかし、このブロックのITLスロットには、適用すべき次のUNDOレコードへのポインタがあり、そのUNDOレコードには更新前レコードの情報と共に、ITLエントリをさらにその前の状態にするための情報が含まれているのである。
ロールバック
次に、UNDOがよく使われるケースがロールバックである。具体的には、明示的なロールバック(セーブポイントへも含む)やトランザクションの途中で何らかのエラーが発生し、Oracleが暗黙的にステートメントレベルのロールバックを行うというケースである。
読み取り一貫性はシングルブロック、つまりあるブロックに対して関連するUNDOレコードをリンクされたリストから探す処理である。これに対し、ロールバックトランザクションの履歴、つまりトランザクションの実行(逆)順にUNDOレコードをリンクされたリストから探す処理である。
UNDOレコードを見てみると、リンクされたリストの痕跡があることがわかる。ダンプにあるエントリrci 0x0eの部分である。これは、このUNDOレコードの直前に生成されたUNDOレコードは同じUNDOブロック内の14番目(0x0e)にあることを示している。もちろん、直前のレコードが別のブロックにある可能性はある。その場合はrciエントリは0となり、rdba:エントリがその前のブロックアドレスを示す。前のブロックに戻る場合、通常はそのブロックの最終レコードが要求されるレコードである。もっとも、技術的にはirb:エントリによりレコードは特定することができる。しかし、irb:エントリが最後のレコードを指さない場合は、rollback to savepointした場合である。
読み取り一貫性とロールバックには重要な違いがある。読み取り一貫性は、データブロックのコピーをメモリ上に作成し、UNDOレコードを適用する。そしてこれは使い終わったらすぐに削除してしまってかまわないコピーなのである。しかしロールバックでは、カレントブロックを獲得しそれにUNDOレコードを適用する。これには3つの重要な効果がある。
・データブロックはカレントブロックであること。すなわち、最終的にはディスクに記録されなければならないブロックのバージョンである
・カレントブロックであるので、この変更にはREDOが生成される(たとえそれが元に戻す変更だとしても)
・Oracleのクラッシュリカバリのメカニズムにより安全に障害をリカバリするために、UNDOレコードを適用しながら「UNDO適用済み」とマークしていく必要がある。これによりさらにREDOが生成される。
ロールバックは大変な作業である。また、元の変更にかけたトランザクションと同じくらいの時間がかかり、REDOも同程度生成される可能性がある。ここで覚えておかなければならないのは、ロールバックはデータブロックを変更する作業であるということだ。つまり、ブロックを再び獲得し、変更し、書き込み、REDOにその変更を書き込む必要がある。さらに、もしトランザクションが大きく時間のかかるものであれば、いくつかのブロックはキャッシュから溢れてディスクへ書き込まれてしまうかもしれない。ロールバックするには、再びそれらをディスクから読み込まなければならないだろう!
他にもロールバックにより発生するオーバーヘッドがある。セッションがUNDOレコードを生成するとき、あるUNDOブロックを獲得し、pinし、それを埋めていく。ロールバックするときは、UNDOブロックから一度に1レコードずつ取り出す。つまり、1レコードずつ、ブロックの開放と獲得を繰り返すのである。これにより、初期の変更よりロールバックのときの方が、UNDOブロックに対するバッファアクセスが多くなる。しかも、OracleがUNDOレコードを獲得する際、毎回UNDO表領域がONLINEであるか調べる。これがdictionary cache(具体的にはdc_tablespaceキャッシュ)へのgetとして現れる。
---
実際の本には上記の内容に加えてブロックダンプや図があるので、もっと理解し易いと思う。また、UNDOの3つ目の使い方~遅延ブロッククリーンアウト~については、機会があれば紹介したいと思う。
◆参考文献
Oracle Core: Essential Internals for DBAs and Developers (Expert's Voice in Databases)
- 作者: Jonathan Lewis
- 出版社/メーカー: Apress
- 発売日: 2011/12/06
- メディア: ペーパーバック
REDOとUNDOその2 [アーキテクチャ]
前回に引き続きREDOとUNDOについて、別の書籍(参考文献 2章のRedo and Undo)の内容をメモしておく。こちらは敬愛するJonathan Lewis氏の書籍である。
---
私の意見では、Oracleの唯一最も重要な機能は、バージョン6で登場した「チェンジベクター」である。これは、データブロックへの変更を表現するメカニズムであり、REDOとUNDOの核心である。この技術により、データが安全に確保され、読み込みと書き込みの競合を最小限に抑え、さらにインスタンスリカバリやメディアリカバリ、スタンバイ技術(データガード)、フラッシュバックメカニズム、変更データのキャプチャやストリームが可能となっているのである。...
基本的なデータの変更
Oracleデータベースの不思議なところは同じデータを2回記録するところである。1つはデータファイルに存在するデータであり、これは概ね最新になっているがup-to-dateの状態はメモリ上に存在しやがてディスクへ反映されるのを待っている。もう1つはREDOログファイル内に一連の説明として存在しており、これによりどのようにデータの内容をゼロから再生成するかがわかる。
アプローチ
あるデータ項目を更新するような命令を発行したとき、Oracleはデータを変更するためにすぐにデータファイル(あるいはメモリ上のデータブロック)を探して変更するようなアプローチはとらない。Oracleは以下のような手順を踏んで変更を行う。
1. データブロックを変更するためのREDOチェンジベクターを生成する
2. UNDO表領域のUNDOブロックにインサートするためのUNDOレコードを生成する
3. UNDOブロックを変更するためのREDOチェンジベクターを生成する
4. データブロックを変更する
実際のところ正確なステップ順や技術的な詳細は、Oracleのバージョンやトランザクションの特性、トランザクションのどこまで実行したか、命令が実行される前の様々なデータベースブロックの状態、トランザクションの始めの変更を見るのかどうか、等に依存する。
例
はじめに簡単なデータを変更する例から始める。1つの行をOLTPトランザクションの中で更新するときの動きである。実際、一般的な状況において、ステップ順は上記で述べたものとは異なる。実際は3-1-2-4の順となり、2つのREDOチェンジベクターはまとめて1つのREDO変更レコードとなりログバッファにコピーされる。この処理は、UNDOブロックとデータブロックが(この順に)変更される前に行われる。つまり、もう少し正確な順にすると、以下のようになる。
1. UNDOブロックをインサートするためのREDOチェンジベクターを生成する
2. データブロックを変更するためのREDOチェンジベクターを生成する
3. 上記2つのREDOチェンジベクターを1つのREDOレコードとして、ログバッファに書き込む
4. UNDOレコードをUNDOブロックにインサートする
5. データブロックを変更する
振り返り
データブロックを更新するとき、OracleはUNDOレコードをUNDOブロックにインサートし、変更をどのように戻すかを記録する。しかし、データベース上のブロックに対するすべての変更について、Oracleはどのようにその変更を行うかを説明するREDOチェンジベクターを生成する。そして、そのベクターの生成は実際の変更の前である。歴史的に、UNDOチェンジベクターを先に生成し、その後、進めるチェンジベクターを生成する。したがって、以下のイベントが順に発生する。
1. UNDOレコードのチェンジベクターを生成する
2. データブロックのチェンジベクターを生成する
3. チェンジベクターをまとめて、REDOレコードをREDOログ(バッファ)に書き込む
4. UNDOレコードをUNDOブロックに書き込む
5. データブロックに変更を行う
始めの2つのステップは必ずしも正確と信じる明確な理由はない。いままでに説明したことやダンプの結果から、この順になることは示すことはできない。...
まとめ
データファイルにおいて、すべての変更はUNDOレコードの生成とマッチする(これもデータファイルへの変更の一部であるが)。同時にOracleはREDOログに、どのようにわれわれの変更を行うか、どのようにそれ自身の変更を行うかを記録する。
1点留意すべきは、データは「その場(in place)」で変更できるため、特定の1レコードに対して無限の更新を行うことができると思うかもしれない。しかし、無限のUNDOレコードを記録することは、UNDO表領域のデータファイルの増加なしでできないし、REDOログに無限に変更を記録することは、新たなログファイルを追加せずに行うことはできない。事を単純化するために、今の時点ではこの無限更新の問題は先送りにして、必要なだけUNDOとREDOレコードを記録できると考えよう。
---
Oracleコミュニティでたびたび投稿を見ることがあるが、いつも内容の思慮深さと謙虚さに関心させられる。これ程簡潔に、Oracleのアーキテクチャの本質を解説した本は他に見たことがない。もう一歩、Oracleの深い世界を体験させてくれる一冊である。
◆参考文献
---
私の意見では、Oracleの唯一最も重要な機能は、バージョン6で登場した「チェンジベクター」である。これは、データブロックへの変更を表現するメカニズムであり、REDOとUNDOの核心である。この技術により、データが安全に確保され、読み込みと書き込みの競合を最小限に抑え、さらにインスタンスリカバリやメディアリカバリ、スタンバイ技術(データガード)、フラッシュバックメカニズム、変更データのキャプチャやストリームが可能となっているのである。...
基本的なデータの変更
Oracleデータベースの不思議なところは同じデータを2回記録するところである。1つはデータファイルに存在するデータであり、これは概ね最新になっているがup-to-dateの状態はメモリ上に存在しやがてディスクへ反映されるのを待っている。もう1つはREDOログファイル内に一連の説明として存在しており、これによりどのようにデータの内容をゼロから再生成するかがわかる。
アプローチ
あるデータ項目を更新するような命令を発行したとき、Oracleはデータを変更するためにすぐにデータファイル(あるいはメモリ上のデータブロック)を探して変更するようなアプローチはとらない。Oracleは以下のような手順を踏んで変更を行う。
1. データブロックを変更するためのREDOチェンジベクターを生成する
2. UNDO表領域のUNDOブロックにインサートするためのUNDOレコードを生成する
3. UNDOブロックを変更するためのREDOチェンジベクターを生成する
4. データブロックを変更する
実際のところ正確なステップ順や技術的な詳細は、Oracleのバージョンやトランザクションの特性、トランザクションのどこまで実行したか、命令が実行される前の様々なデータベースブロックの状態、トランザクションの始めの変更を見るのかどうか、等に依存する。
例
はじめに簡単なデータを変更する例から始める。1つの行をOLTPトランザクションの中で更新するときの動きである。実際、一般的な状況において、ステップ順は上記で述べたものとは異なる。実際は3-1-2-4の順となり、2つのREDOチェンジベクターはまとめて1つのREDO変更レコードとなりログバッファにコピーされる。この処理は、UNDOブロックとデータブロックが(この順に)変更される前に行われる。つまり、もう少し正確な順にすると、以下のようになる。
1. UNDOブロックをインサートするためのREDOチェンジベクターを生成する
2. データブロックを変更するためのREDOチェンジベクターを生成する
3. 上記2つのREDOチェンジベクターを1つのREDOレコードとして、ログバッファに書き込む
4. UNDOレコードをUNDOブロックにインサートする
5. データブロックを変更する
振り返り
データブロックを更新するとき、OracleはUNDOレコードをUNDOブロックにインサートし、変更をどのように戻すかを記録する。しかし、データベース上のブロックに対するすべての変更について、Oracleはどのようにその変更を行うかを説明するREDOチェンジベクターを生成する。そして、そのベクターの生成は実際の変更の前である。歴史的に、UNDOチェンジベクターを先に生成し、その後、進めるチェンジベクターを生成する。したがって、以下のイベントが順に発生する。
1. UNDOレコードのチェンジベクターを生成する
2. データブロックのチェンジベクターを生成する
3. チェンジベクターをまとめて、REDOレコードをREDOログ(バッファ)に書き込む
4. UNDOレコードをUNDOブロックに書き込む
5. データブロックに変更を行う
始めの2つのステップは必ずしも正確と信じる明確な理由はない。いままでに説明したことやダンプの結果から、この順になることは示すことはできない。...
まとめ
データファイルにおいて、すべての変更はUNDOレコードの生成とマッチする(これもデータファイルへの変更の一部であるが)。同時にOracleはREDOログに、どのようにわれわれの変更を行うか、どのようにそれ自身の変更を行うかを記録する。
1点留意すべきは、データは「その場(in place)」で変更できるため、特定の1レコードに対して無限の更新を行うことができると思うかもしれない。しかし、無限のUNDOレコードを記録することは、UNDO表領域のデータファイルの増加なしでできないし、REDOログに無限に変更を記録することは、新たなログファイルを追加せずに行うことはできない。事を単純化するために、今の時点ではこの無限更新の問題は先送りにして、必要なだけUNDOとREDOレコードを記録できると考えよう。
---
Oracleコミュニティでたびたび投稿を見ることがあるが、いつも内容の思慮深さと謙虚さに関心させられる。これ程簡潔に、Oracleのアーキテクチャの本質を解説した本は他に見たことがない。もう一歩、Oracleの深い世界を体験させてくれる一冊である。
◆参考文献
Oracle Core: Essential Internals for DBAs and Developers (Expert's Voice in Databases)
- 作者: Jonathan Lewis
- 出版社/メーカー: Apress
- 発売日: 2011/12/06
- メディア: ペーパーバック
REDOとUNDO [アーキテクチャ]
最近読んでいる書籍(下記の参考文献9章 REDOとUNDO)に、Oracleデータベースの最も重要なREDOとUNDOについて詳しく記載されていたので、備忘まで要点をメモしておく。原文の英語を読みやすさを優先して意図を汲んで要約しているので、原文の正確性は損なわれているかもしれないが、そのあたりはご容赦頂きたい。
---
REDOとはトランザクションを記録したログであり、不慮の障害の場合にトランザクションを再生するためのものである。UNDOはその逆に、トランザクションをロールバックするためのものである。REDOはオンラインREDOログファイル(アーカイブログファイル)、UNDOはUNDO表領域(内のセグメント)に記録される。
REDOとUNDOはどのように動作するのか
以下のようなテーブルと索引があるとする。
create table t(x int, y int);
create index ti on t(x);
ここで、以下のトランザクションを例に考えてみる。
(1) insert into t (x,y) values (1,1);
(2) update t set x= x+1 where x=1;
(3) delete from t where x=2;
まず(1)のINSERTのケースを考えてみる。INSERT INTO TはREDOとUNDOを生成する。このとき、バッファキャッシュ上には、テーブル、索引、UNDOセグメントのブロックがディスクから読み込まれ更新される。そして、それらブロックへの更新情報はログとしてREDOログバッファに記録される。
さて、COMMIT前にDBに何らかの障害が発生しサーバがダウンしたとしよう。このとき、なんら問題はない。SGA上のREDOログバッファ、バッファキャッシュ上のダーティブロックはディスクに記録されず、DBサーバ復旧時は、あたかもトランザクションが実行される前の状態のままとなる。
次に、バッファキャッシュが一杯になったケースを考えよう。このとき、バッファキャッシュの空きを作るため、DBWnはダーティブロックをディスクに書き込む必要があるが、その前にLGWRはREDOログバッファをこれらのブロックに関連するトランザクションログをフラッシュさせる。これにより、UNDOのログがディスクに記録されるため、DB障害時に未コミットトランザクションによる変更ブロックをロールバックすることが可能となる。なお、REDOログバッファは、(1)3秒毎、(2)ログバッファの1/3に達したとき、または1MB以上に達したとき、(3)COMMITまたはROLLBACKが発行されたとき、にフラッシュされるため、通常ほとんどのREDOログバッファはフラッシュされた状態になっているはずである。つまり、未コミットの変更ブロックがバッファキャッシュ上にあり、その未コミットの変更のREDOがディスク上にある状態というのは、通常よく発生するありふれた状態なのである。
次に(2)のUPDATEのケース。UPDATEはINSERTと同様の動きをする。ただし、UNDO量はUPDATE前のイメージを保持するため大きくなる。テーブル、索引、UNDOセグメントブロックがバッファキャッシュ上にあり、ログバッファにUPDATEの更新ログが記録された状態(INSERTの更新ログはREDOログファイルに記録)である。
もしこの状態でDBがクラッシュしたらどうなるか。DBのインスタンス起動時にOracleはREDOログファイルを読み込み、このトランザクションログを見つけ、INSERTにより生成された更新ログ(UNDOブロックを含む)からロールフォワードする。UPDATEのREDOログはバッファ上にのみ存在していたので失われるが、COMMITしていないので問題ない。Oracleはクラッシュリカバリの過程でINSERTがCOMMITされていないことを検出し、(記録されたREDOログにより生成された)バッファキャッシュ上のUNDOセグメントの情報(テーブルと索引の更新前情報)からROLLBACKする。これにより、すべては元の状態となる。ディスク上のブロックはINSERTの更新が反映されているかもしれないが、更新が取り消されたバッファキャッシュがやがてフラッシュされるタイミングで反映されるので問題ない。このようにクラッシュリカバリでは2つのフェーズで行われる。始めにロールフォワードにより障害直前の状態に復旧し、その後に未COMMITトランザクションすべてをロールバックする。これによりデータファイルが整合性が取れた状態となる訳である。
ではクラッシュではなく、トランザクションをロールバックしたらどうなるか。OracleはこのトランザクションのUNDOをバッファキャッシュ上またはディスク上のUNDOセグメントを見つけ、バッファキャッシュ上の表のデータと索引にUNDO情報を適用する。もしバッファキャッシュになければディスクから読み込みUNDOを適用する。これらのブロックは後にフラッシュされディスクに反映される。ここで1点明確にしておくと、ロールバックするプロセスにおいて、REDOログは一切関与しないということである。REDOログが使われるのはリカバリとアーカイブのためだけである。ARCnがオンラインREDOログファイルを読み、LGWRが別のREDOログファイルに書き込みを行うだけに十分なデバイスがある限り、ログファイルの競合は発生しない。このようにREDOとUNDOが別となっていないデータベースでは、ログファイルをトランザクションログとして扱っており、ロールバック時にログを読み込むと同時に、ログライターが同じログに書き込みを行うため競合が発生してしまう。OracleはREDOログをシーケンシャルに書き込む。そして、書き込み中には他から読み込みが発生することはない、というアーキテクチャとなっている。
(3)のDELETEのケースでは、DELETEの結果UNDOが生成され、ブロックが更新され、REDOがログバッファに書き込まれる。UPDATEの動きと同じである。
COMMITを行うとどうなるか。OracleはREDOログバッファをディスクへフラッシュする。変更されたブロックはバッファキャッシュ上にあるが、一部はディスクにフラッシュされた状態かもしれない。しかし、重要なのは、このトランザクションを再実行するためのREDOログはディスクに書き込まれており、永続的な状態になっていることである。データファイルの個々のブロックはまだトランザクション実行前の状態かもしれないが、問題はない。障害時にはREDOログファイルにより最新のブロックの状態にすることができるからである。UNDO情報はUNDOセグメントが上書きされ再利用されるまで保持され、読み取り一貫性のために利用される。
COMMITは何をするのか?
COMMITは通常トランザクションの更新量に依存せず非常に高速に完了する。COMMITの処理時間はトランザクションのサイズにかかわらずフラットなのである。これはCOMMITの処理が本質的に少ないからである。なぜなら、COMMITに必要な以下のような処理はほとんど完了している。
・SGA上にUNDOブロックの生成
・SGA上に更新データブロックの生成
・上記2つのREDOをSGA上に生成
・上記3つのサイズと処理時間に応じてデータがディスクへフラッシュされる
・すべてのロックが獲得される
その上で、COMMITすると、残作業として以下が行われる
・このトランザクションのSCNが生成される
・LGWRがログバッファ上の(残りの)ログエントリをディスクに書き込む
・V$LOCK上のロックレコードをリリースする
・バッファキャッシュ上のダーティブロックに対してブロッククリーンアウト(ブロックヘッダ上のロック関連情報の削除)を行う
上記を見ればわかるように、COMMITの処理はほとんどすることがない。一番長い処理はI/O処理を含む、LGWRにより行われる処理である。しかしそれにしても、REDOログバッファの内容は繰り返しフラッシュされているので、その量はかなり削減されているはずである。LGWRはバックグラウンドでREDOログバッファの内容を継続的にフラッシュしていく。これによりCOMMITが長い時間待たせることを防いでいる訳である。
ROLLBACKは何をするのか?
ROLLBACKの時間は更新量に依存する。なぜならROLLBACKは実行した処理を取り消さなければならないからだ。COMMITと同様、一連の処理が実行されなければならないが、ROLLBACKが行われる前に、データベースは既に多くの処理を行っている
・UNDOセグメントのレコードをSGA上に生成する
・更新されたデータブロックをSGA上に生成する
・上記2つのREDOログをSGA上に生成する
・上記3つのサイズと処理時間に応じてデータがディスクへフラッシュされる
・すべてのロックが獲得される
ROLLBACKを行うと、以下が実行される
・すべての更新を取り消す。これはUNDOセグメントからデータブロックを読み込み実行した処理を巻き戻し、UNDOエントリを適用済みとマークする。INSERTなら削除、UPDATEならその変更を元に戻す、DELETEなら再度INSERTする
・すべてのロックをリリースする
---
なお、実際は図やサンプルスクリプトでより具体的に説明されているので、理解を深めたい方は一読をお勧めする。このレベルまで詳しく記載された書籍は日本語ではなかなかないので、この章意外についても時間があれば紹介したいと思う。
◆参考文献

---
REDOとはトランザクションを記録したログであり、不慮の障害の場合にトランザクションを再生するためのものである。UNDOはその逆に、トランザクションをロールバックするためのものである。REDOはオンラインREDOログファイル(アーカイブログファイル)、UNDOはUNDO表領域(内のセグメント)に記録される。
REDOとUNDOはどのように動作するのか
以下のようなテーブルと索引があるとする。
create table t(x int, y int);
create index ti on t(x);
ここで、以下のトランザクションを例に考えてみる。
(1) insert into t (x,y) values (1,1);
(2) update t set x= x+1 where x=1;
(3) delete from t where x=2;
まず(1)のINSERTのケースを考えてみる。INSERT INTO TはREDOとUNDOを生成する。このとき、バッファキャッシュ上には、テーブル、索引、UNDOセグメントのブロックがディスクから読み込まれ更新される。そして、それらブロックへの更新情報はログとしてREDOログバッファに記録される。
さて、COMMIT前にDBに何らかの障害が発生しサーバがダウンしたとしよう。このとき、なんら問題はない。SGA上のREDOログバッファ、バッファキャッシュ上のダーティブロックはディスクに記録されず、DBサーバ復旧時は、あたかもトランザクションが実行される前の状態のままとなる。
次に、バッファキャッシュが一杯になったケースを考えよう。このとき、バッファキャッシュの空きを作るため、DBWnはダーティブロックをディスクに書き込む必要があるが、その前にLGWRはREDOログバッファをこれらのブロックに関連するトランザクションログをフラッシュさせる。これにより、UNDOのログがディスクに記録されるため、DB障害時に未コミットトランザクションによる変更ブロックをロールバックすることが可能となる。なお、REDOログバッファは、(1)3秒毎、(2)ログバッファの1/3に達したとき、または1MB以上に達したとき、(3)COMMITまたはROLLBACKが発行されたとき、にフラッシュされるため、通常ほとんどのREDOログバッファはフラッシュされた状態になっているはずである。つまり、未コミットの変更ブロックがバッファキャッシュ上にあり、その未コミットの変更のREDOがディスク上にある状態というのは、通常よく発生するありふれた状態なのである。
次に(2)のUPDATEのケース。UPDATEはINSERTと同様の動きをする。ただし、UNDO量はUPDATE前のイメージを保持するため大きくなる。テーブル、索引、UNDOセグメントブロックがバッファキャッシュ上にあり、ログバッファにUPDATEの更新ログが記録された状態(INSERTの更新ログはREDOログファイルに記録)である。
もしこの状態でDBがクラッシュしたらどうなるか。DBのインスタンス起動時にOracleはREDOログファイルを読み込み、このトランザクションログを見つけ、INSERTにより生成された更新ログ(UNDOブロックを含む)からロールフォワードする。UPDATEのREDOログはバッファ上にのみ存在していたので失われるが、COMMITしていないので問題ない。Oracleはクラッシュリカバリの過程でINSERTがCOMMITされていないことを検出し、(記録されたREDOログにより生成された)バッファキャッシュ上のUNDOセグメントの情報(テーブルと索引の更新前情報)からROLLBACKする。これにより、すべては元の状態となる。ディスク上のブロックはINSERTの更新が反映されているかもしれないが、更新が取り消されたバッファキャッシュがやがてフラッシュされるタイミングで反映されるので問題ない。このようにクラッシュリカバリでは2つのフェーズで行われる。始めにロールフォワードにより障害直前の状態に復旧し、その後に未COMMITトランザクションすべてをロールバックする。これによりデータファイルが整合性が取れた状態となる訳である。
ではクラッシュではなく、トランザクションをロールバックしたらどうなるか。OracleはこのトランザクションのUNDOをバッファキャッシュ上またはディスク上のUNDOセグメントを見つけ、バッファキャッシュ上の表のデータと索引にUNDO情報を適用する。もしバッファキャッシュになければディスクから読み込みUNDOを適用する。これらのブロックは後にフラッシュされディスクに反映される。ここで1点明確にしておくと、ロールバックするプロセスにおいて、REDOログは一切関与しないということである。REDOログが使われるのはリカバリとアーカイブのためだけである。ARCnがオンラインREDOログファイルを読み、LGWRが別のREDOログファイルに書き込みを行うだけに十分なデバイスがある限り、ログファイルの競合は発生しない。このようにREDOとUNDOが別となっていないデータベースでは、ログファイルをトランザクションログとして扱っており、ロールバック時にログを読み込むと同時に、ログライターが同じログに書き込みを行うため競合が発生してしまう。OracleはREDOログをシーケンシャルに書き込む。そして、書き込み中には他から読み込みが発生することはない、というアーキテクチャとなっている。
(3)のDELETEのケースでは、DELETEの結果UNDOが生成され、ブロックが更新され、REDOがログバッファに書き込まれる。UPDATEの動きと同じである。
COMMITを行うとどうなるか。OracleはREDOログバッファをディスクへフラッシュする。変更されたブロックはバッファキャッシュ上にあるが、一部はディスクにフラッシュされた状態かもしれない。しかし、重要なのは、このトランザクションを再実行するためのREDOログはディスクに書き込まれており、永続的な状態になっていることである。データファイルの個々のブロックはまだトランザクション実行前の状態かもしれないが、問題はない。障害時にはREDOログファイルにより最新のブロックの状態にすることができるからである。UNDO情報はUNDOセグメントが上書きされ再利用されるまで保持され、読み取り一貫性のために利用される。
COMMITは何をするのか?
COMMITは通常トランザクションの更新量に依存せず非常に高速に完了する。COMMITの処理時間はトランザクションのサイズにかかわらずフラットなのである。これはCOMMITの処理が本質的に少ないからである。なぜなら、COMMITに必要な以下のような処理はほとんど完了している。
・SGA上にUNDOブロックの生成
・SGA上に更新データブロックの生成
・上記2つのREDOをSGA上に生成
・上記3つのサイズと処理時間に応じてデータがディスクへフラッシュされる
・すべてのロックが獲得される
その上で、COMMITすると、残作業として以下が行われる
・このトランザクションのSCNが生成される
・LGWRがログバッファ上の(残りの)ログエントリをディスクに書き込む
・V$LOCK上のロックレコードをリリースする
・バッファキャッシュ上のダーティブロックに対してブロッククリーンアウト(ブロックヘッダ上のロック関連情報の削除)を行う
上記を見ればわかるように、COMMITの処理はほとんどすることがない。一番長い処理はI/O処理を含む、LGWRにより行われる処理である。しかしそれにしても、REDOログバッファの内容は繰り返しフラッシュされているので、その量はかなり削減されているはずである。LGWRはバックグラウンドでREDOログバッファの内容を継続的にフラッシュしていく。これによりCOMMITが長い時間待たせることを防いでいる訳である。
ROLLBACKは何をするのか?
ROLLBACKの時間は更新量に依存する。なぜならROLLBACKは実行した処理を取り消さなければならないからだ。COMMITと同様、一連の処理が実行されなければならないが、ROLLBACKが行われる前に、データベースは既に多くの処理を行っている
・UNDOセグメントのレコードをSGA上に生成する
・更新されたデータブロックをSGA上に生成する
・上記2つのREDOログをSGA上に生成する
・上記3つのサイズと処理時間に応じてデータがディスクへフラッシュされる
・すべてのロックが獲得される
ROLLBACKを行うと、以下が実行される
・すべての更新を取り消す。これはUNDOセグメントからデータブロックを読み込み実行した処理を巻き戻し、UNDOエントリを適用済みとマークする。INSERTなら削除、UPDATEならその変更を元に戻す、DELETEなら再度INSERTする
・すべてのロックをリリースする
---
なお、実際は図やサンプルスクリプトでより具体的に説明されているので、理解を深めたい方は一読をお勧めする。このレベルまで詳しく記載された書籍は日本語ではなかなかないので、この章意外についても時間があれば紹介したいと思う。
◆参考文献
Expert Oracle Database Architecture
- 作者: Thomas Kyte
- 出版社/メーカー: Apress
- 発売日: 2014/11/14
- メディア: ペーパーバック
Exadataのメモリ使用率の考え方 [アーキテクチャ]
性能試験等でExadataのDBサーバのメモリの利用状況をvmstat等OSのコマンドから確認するが、SGAの領域はHugePageを使うため、その分を考慮して評価する必要がある。よく聞かれることが多いので、ExadataのDBサーバのメモリ使用率について、vmstatの結果からの確認方法のメモを残しておく。
1.OSのメモリ利用状況の確認方法について
一般的にLinuxのメモリ使用率を確認するためにfreeコマンドを使う。数値の単位はKBである。
[oracle@db01 ~]$ free
total used free shared buffers cached
Mem: 790788832 738741596 52047236 6554056 763312 226434384
-/+ buffers/cache: 511543900 279244932
Swap: 25165820 0 25165820
OSから認識されるメモリ全体量はtotal。この例では755GB程度(実際の物理メモリは768GBなので若干少なくなる)。total=used+freeの関係になっているが、このusedが使用済みメモリという訳ではない点に注意が必要である。このusedのうち、buffers+cached: 227197696KB(217GB)はアクティブプロセスで使われていない領域を示す。従って、実質的な空きメモリと使用メモリのサイズは以下の式で求めることができる。
・空きメモリサイズ=free+ buffers + cached ※この例では279244932(266GB)
・使用メモリサイズ=used-(buffers + cached) ※この例では511543900(488GB)
なお、上記のtotalのサイズは/proc/meminfoのMemTotalで確認することができる。
[oracle@db01 bin]$ cat /proc/meminfo
MemTotal: 790788832 kB
2.vmstatの結果からのメモリ使用率について
vmstatの結果を見ると、下記の通りfree, buffer, cachedが確認できる(それぞれ単位はKB)ので、これらを合計したのが実質的な空きメモリサイズである。使用率を確認するにはメモリ全体量が必要だが、vmstatでは確認できないので、別途/proc/meminfo等で確認が必要である。
メモリ使用率= 1- (free+buff+cache) / MemTotal
※下記例の★部分では1- (52650176 + 763312 + 226436064) / 790788832 = 65% ...(1)
例)
[oracle@db01 ~]$ vmstat 5 10
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 0 52932476 763312 226435088 0 0 10 11 0 0 2 2 97 0 0
1 0 0 52791844 763312 226435536 0 0 0 226 13319 1140813 4 5 91 0 0
★ 2 0 0 52650176 763312 226436064 0 0 0 384 13871 1076744 4 5 91 0 0
3.Hugepageの考慮について
上記ではHugePageは考慮されていない。HugePageはSGA格納用としてOS起動時に予約されるメモリ領域である。ユーザプロセス(サーバプロセスやPGA領域)はHugePagesを使うことができないため、そもそもHugePage領域を使用率の分母に入れることに大きな意味はない。DBサーバのメモリを監視する際、個人的にはHugePage領域を考慮(除外)し監視する方が実態に合うのではないかと考える。
HugePageのサイズは/proc/meminfoで確認ができる。
例)
[oracle@db01 bin]$ cat /proc/meminfo
・・・
HugePages_Total: 230912 ・・・HugePageのブロック数
Hugepagesize: 2048 kB ・・・HugePageのブロックサイズ
HugePageの領域は実質OSでは利用できないため、実質トータルで利用可能なメモリは下記式の通りとなる。
実質トータル利用可能メモリサイズ = MemTotal - HugePageサイズ = MemTotal - HugePages_Total x Hugepagesize
ここから、結局HugePageを考慮した実質メモリ使用率は以下の式で計算できる。
HugePageを考慮した実質メモリ使用率 = 1- (free+buff+cache) / ( MemTotal - HugePages_Total x Hugepagesize )
上記例では、以下の通り分母は303GBとなるため、vmstatからfree+buff+cacheを計算するだけで、HugePageを考慮したメモリ使用率を導くことができる。
MemTotal - HugePages_Total x Hugepagesize = 790788832KB(755GB) - 230912x2048KB(451GB) = 317,881,056KB(303GB)
※下記例の★部分では1- (52650176 + 763312 + 226436064) / ( 317881056 ) =~ 12% ...(2)
例)
[oracle@db01 ~]$ vmstat 5 10
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 0 52932476 763312 226435088 0 0 10 11 0 0 2 2 97 0 0
1 0 0 52791844 763312 226435536 0 0 0 226 13319 1140813 4 5 91 0 0
★ 2 0 0 52650176 763312 226436064 0 0 0 384 13871 1076744 4 5 91 0 0
HugePageを考慮しない(1)と65%だったメモリ使用率が、考慮する(2)だと12%となる。後者の方がどの程度APが処理してメモリを消費しているか直感的に把握し易いと考える。
4.まとめ
vmstatからDBサーバの実質的なメモリ使用率を求めるためには、まず/proc/meminfoからHugePageを考慮した実質的に利用可能なメモリサイズを求め、以下の式を用いて実質メモリ使用率を求める。
HugePageを考慮した実質メモリ使用率 = 1- (free+buff+cache) / ( MemTotal - HugePages_Total x Hugepagesize )
free, buff, cache ... vmstatの値
MemTotal, HugePages_Total, Hugepagesize ... /proc/meminfoの値
以上
1.OSのメモリ利用状況の確認方法について
一般的にLinuxのメモリ使用率を確認するためにfreeコマンドを使う。数値の単位はKBである。
[oracle@db01 ~]$ free
total used free shared buffers cached
Mem: 790788832 738741596 52047236 6554056 763312 226434384
-/+ buffers/cache: 511543900 279244932
Swap: 25165820 0 25165820
OSから認識されるメモリ全体量はtotal。この例では755GB程度(実際の物理メモリは768GBなので若干少なくなる)。total=used+freeの関係になっているが、このusedが使用済みメモリという訳ではない点に注意が必要である。このusedのうち、buffers+cached: 227197696KB(217GB)はアクティブプロセスで使われていない領域を示す。従って、実質的な空きメモリと使用メモリのサイズは以下の式で求めることができる。
・空きメモリサイズ=free+ buffers + cached ※この例では279244932(266GB)
・使用メモリサイズ=used-(buffers + cached) ※この例では511543900(488GB)
なお、上記のtotalのサイズは/proc/meminfoのMemTotalで確認することができる。
[oracle@db01 bin]$ cat /proc/meminfo
MemTotal: 790788832 kB
2.vmstatの結果からのメモリ使用率について
vmstatの結果を見ると、下記の通りfree, buffer, cachedが確認できる(それぞれ単位はKB)ので、これらを合計したのが実質的な空きメモリサイズである。使用率を確認するにはメモリ全体量が必要だが、vmstatでは確認できないので、別途/proc/meminfo等で確認が必要である。
メモリ使用率= 1- (free+buff+cache) / MemTotal
※下記例の★部分では1- (52650176 + 763312 + 226436064) / 790788832 = 65% ...(1)
例)
[oracle@db01 ~]$ vmstat 5 10
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 0 52932476 763312 226435088 0 0 10 11 0 0 2 2 97 0 0
1 0 0 52791844 763312 226435536 0 0 0 226 13319 1140813 4 5 91 0 0
★ 2 0 0 52650176 763312 226436064 0 0 0 384 13871 1076744 4 5 91 0 0
3.Hugepageの考慮について
上記ではHugePageは考慮されていない。HugePageはSGA格納用としてOS起動時に予約されるメモリ領域である。ユーザプロセス(サーバプロセスやPGA領域)はHugePagesを使うことができないため、そもそもHugePage領域を使用率の分母に入れることに大きな意味はない。DBサーバのメモリを監視する際、個人的にはHugePage領域を考慮(除外)し監視する方が実態に合うのではないかと考える。
HugePageのサイズは/proc/meminfoで確認ができる。
例)
[oracle@db01 bin]$ cat /proc/meminfo
・・・
HugePages_Total: 230912 ・・・HugePageのブロック数
Hugepagesize: 2048 kB ・・・HugePageのブロックサイズ
HugePageの領域は実質OSでは利用できないため、実質トータルで利用可能なメモリは下記式の通りとなる。
実質トータル利用可能メモリサイズ = MemTotal - HugePageサイズ = MemTotal - HugePages_Total x Hugepagesize
ここから、結局HugePageを考慮した実質メモリ使用率は以下の式で計算できる。
HugePageを考慮した実質メモリ使用率 = 1- (free+buff+cache) / ( MemTotal - HugePages_Total x Hugepagesize )
上記例では、以下の通り分母は303GBとなるため、vmstatからfree+buff+cacheを計算するだけで、HugePageを考慮したメモリ使用率を導くことができる。
MemTotal - HugePages_Total x Hugepagesize = 790788832KB(755GB) - 230912x2048KB(451GB) = 317,881,056KB(303GB)
※下記例の★部分では1- (52650176 + 763312 + 226436064) / ( 317881056 ) =~ 12% ...(2)
例)
[oracle@db01 ~]$ vmstat 5 10
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 0 52932476 763312 226435088 0 0 10 11 0 0 2 2 97 0 0
1 0 0 52791844 763312 226435536 0 0 0 226 13319 1140813 4 5 91 0 0
★ 2 0 0 52650176 763312 226436064 0 0 0 384 13871 1076744 4 5 91 0 0
HugePageを考慮しない(1)と65%だったメモリ使用率が、考慮する(2)だと12%となる。後者の方がどの程度APが処理してメモリを消費しているか直感的に把握し易いと考える。
4.まとめ
vmstatからDBサーバの実質的なメモリ使用率を求めるためには、まず/proc/meminfoからHugePageを考慮した実質的に利用可能なメモリサイズを求め、以下の式を用いて実質メモリ使用率を求める。
HugePageを考慮した実質メモリ使用率 = 1- (free+buff+cache) / ( MemTotal - HugePages_Total x Hugepagesize )
free, buff, cache ... vmstatの値
MemTotal, HugePages_Total, Hugepagesize ... /proc/meminfoの値
以上
ExadataのI/O統計を整理する [アーキテクチャ]
#2019/2/27変更:図を追加
#2021/2/10変更:図を清書
花粉が飛び始めて春の気配を感じる今日この頃である。
先月、性能TmからExadata特有の統計(AWRから確認できるv$sysstatの統計)について問い合わせがあり、smart scanやflash cacheについて取得すべき統計を洗い出した。知っているつもりではあったが、1つ1つの統計を改めて眺めてみると、その示す意味が意外とよくわかっていないことに気がついたた。マニュアルとExpert Exadataを読みながら、1つ1つの統計の意味を調べてみたので、備忘までここに記しておく。
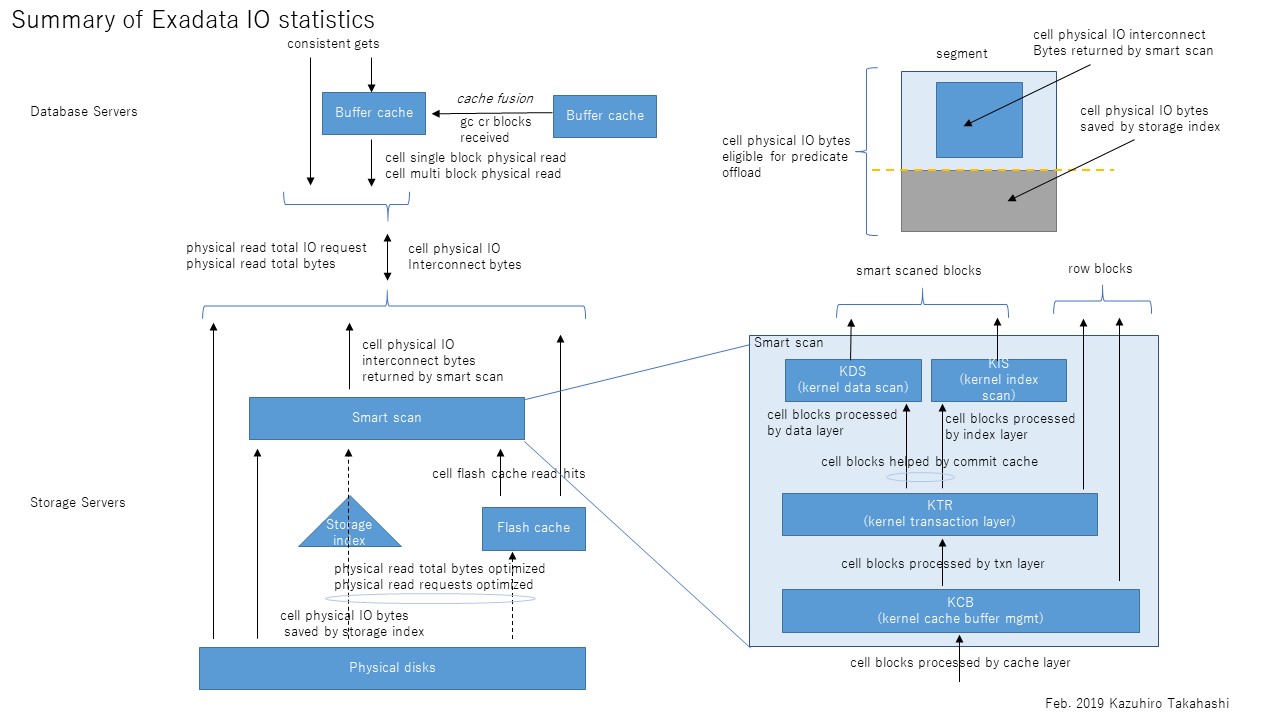
まずExadataのI/Oの全体のアーキテクチャをおさらいしておく。たぶん大体正しい図を書いてみたので、上から順に説明していく。
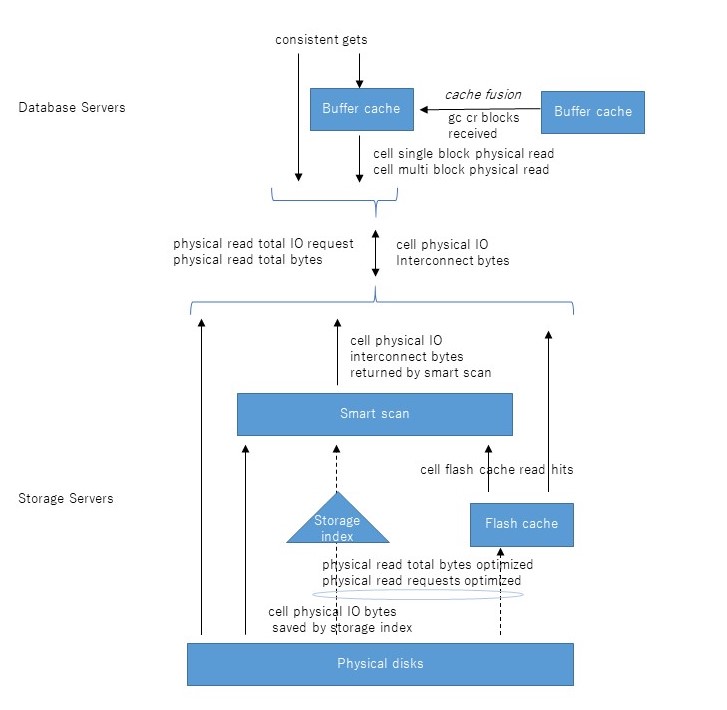
DBサーバでSELECT文を発行するとconsistent gets、すなわち読み取り一貫性を保障するブロック読み込みが発生する。これはローカルDBサーバのバッファキャッシュ上にそのブロックが存在していれば当然そこから読み取られるが、ない場合はcache fusionで他のDBサーバから転送される(gc cr received)。そこにもなければ初めて物理読み込み(physical read bytes等)が発生することとなる。一方、ダイレクトパスリードの場合はバッファキャッシュをバイパスするので、上記の流れはスキップして直接物理読み込みが発生することとなる。
さて、物理読み込みの先は複数のストレージサーバであるが、ここから先がちょっと複雑になる。まず、DBサーバとストレージサーバの間のI/Oを示すのが、cell physical IO interconnect bytesである。これは読み込みだけでなく書き込みも含む、すべてのI/Oのやりとり量を示す統計である。このうち、スマートスキャンにより返却されたI/O量がcell physical IO interconnect bytes returned by smart scanである。これはストレージインデックスやpredicate filtering、column projection等によって削減された後の量である。これらの削減される前のI/O量を示すのがcell physical IO bytes eligible for predicate offloadである。端的には、スマートスキャンがなければDBサーバに返却されたであろうセグメントの全ブロックサイズを示す。従ってスマートスキャンのI/O削減率は以下のように求めることができると考える。
スマートスキャンによるI/O削減率=1- cell physical IO interconnect bytes returned by smart scan / cell physical IO bytes eligible for predicate
これも図にするとイメージし易いだろう。
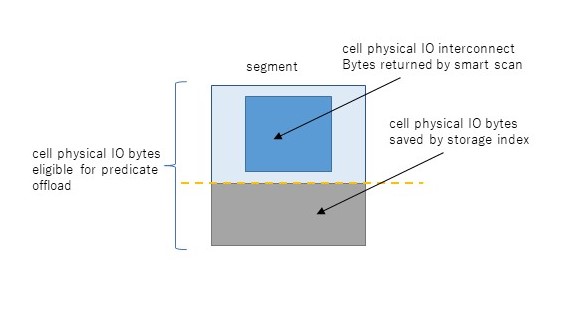
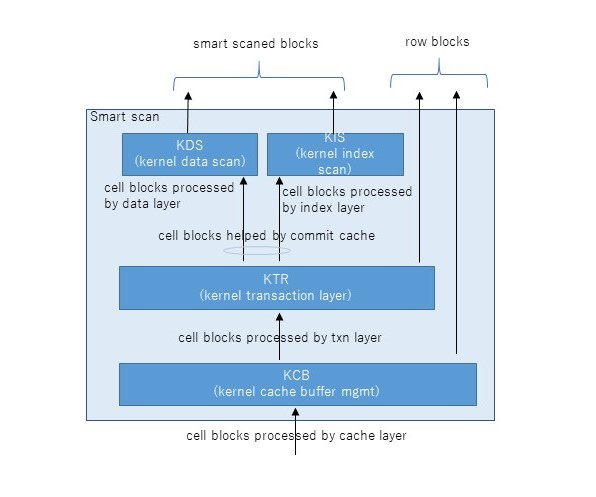
ちなみに話はそれるが、cell physical IO bytes eligible for predicate offloadが0の場合はそもそもスマートスキャンが発生していない状況であることを示す。逆に上記I/O削減率が0の場合はどう考えればよいのだろうか。実はスマートスキャンの3条件が揃っていてスマートスキャンが発生していても、スマートスキャンができずブロックをそのままDBサーバに返却することがある。これはスマートスキャンは読み取り一貫性を保障しつつ、単一ストレージサーバで処理を独立して完結しなければならないこととに関連している。例えば、読み取り一貫性を保障するためにUNDOブロックを読まなければならない場合、ストレージサーバ(cellsrv)はスマートスキャンをあきらめブロックをそのままDBサーバに返却する。同様のことが行連鎖(複数ブロックにレコードがまたがった状態)した表へのアクセスでも発生する。連鎖した先のブロックはASMによる分散で同じストレージサーバ上にある保障はないためである。これらDBサーバへブロックがそのまま返却された場合、スマートスキャンによるI/O削減率が悪化し、DBサーバから大量のsingle block physical readが発生するということが発生する。以下の図はスマートスキャンの部分の内部の流れを示したものだが、右側2つの流れがスマートスキャンにならず、DBサーバへブロックをそのまま返却する流れである。
フラッシュキャッシュにヒットしたI/O数はcell flash cache read hitsで確認できる。physical read total IO requestsに対してどの程度キャッシュヒットしたかがわかる。なお、このtotalの意味はアプリケーション(SQL)だけでなく、バックアップ、リカバリおよびその他のユーティリティを含むIOを示している。totalのないphysical read IO requestsはアプリケーション(SQL)のみのI/Oを示す。従って、フラッシュキャッシュのヒット率は以下の式で求められると考える。
フラッシュキャッシュのヒット率=cell flash cache read hits / physical read total IO requests
フラッシュキャッシュおよびストレージ索引により削減されたI/O量はphysical read total bytes optimizedで確認できる。うち、ストレージインデックス分はcell physical IO bytes saved by storage indexである。ストレージインデックスはスマートスキャンのときだけ使われるが、フラッシュキャッシュは通常のブロックI/Oでも使われる点に留意したい。
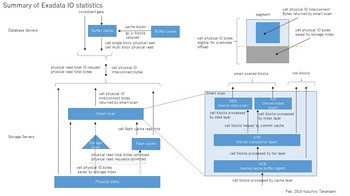
なお、上記多くの内容は以下の参考文献に記載されたものをベースに自らの考察を加えたものなので、正確性は保障できないのであしからず。下図はリファレンスとして使うために上記全体を1枚にまとめてみたものである。
参考文献

#2021/2/10変更:図を清書
花粉が飛び始めて春の気配を感じる今日この頃である。
先月、性能TmからExadata特有の統計(AWRから確認できるv$sysstatの統計)について問い合わせがあり、smart scanやflash cacheについて取得すべき統計を洗い出した。知っているつもりではあったが、1つ1つの統計を改めて眺めてみると、その示す意味が意外とよくわかっていないことに気がついたた。マニュアルとExpert Exadataを読みながら、1つ1つの統計の意味を調べてみたので、備忘までここに記しておく。
まずExadataのI/Oの全体のアーキテクチャをおさらいしておく。たぶん大体正しい図を書いてみたので、上から順に説明していく。
DBサーバでSELECT文を発行するとconsistent gets、すなわち読み取り一貫性を保障するブロック読み込みが発生する。これはローカルDBサーバのバッファキャッシュ上にそのブロックが存在していれば当然そこから読み取られるが、ない場合はcache fusionで他のDBサーバから転送される(gc cr received)。そこにもなければ初めて物理読み込み(physical read bytes等)が発生することとなる。一方、ダイレクトパスリードの場合はバッファキャッシュをバイパスするので、上記の流れはスキップして直接物理読み込みが発生することとなる。
さて、物理読み込みの先は複数のストレージサーバであるが、ここから先がちょっと複雑になる。まず、DBサーバとストレージサーバの間のI/Oを示すのが、cell physical IO interconnect bytesである。これは読み込みだけでなく書き込みも含む、すべてのI/Oのやりとり量を示す統計である。このうち、スマートスキャンにより返却されたI/O量がcell physical IO interconnect bytes returned by smart scanである。これはストレージインデックスやpredicate filtering、column projection等によって削減された後の量である。これらの削減される前のI/O量を示すのがcell physical IO bytes eligible for predicate offloadである。端的には、スマートスキャンがなければDBサーバに返却されたであろうセグメントの全ブロックサイズを示す。従ってスマートスキャンのI/O削減率は以下のように求めることができると考える。
スマートスキャンによるI/O削減率=1- cell physical IO interconnect bytes returned by smart scan / cell physical IO bytes eligible for predicate
これも図にするとイメージし易いだろう。
ちなみに話はそれるが、cell physical IO bytes eligible for predicate offloadが0の場合はそもそもスマートスキャンが発生していない状況であることを示す。逆に上記I/O削減率が0の場合はどう考えればよいのだろうか。実はスマートスキャンの3条件が揃っていてスマートスキャンが発生していても、スマートスキャンができずブロックをそのままDBサーバに返却することがある。これはスマートスキャンは読み取り一貫性を保障しつつ、単一ストレージサーバで処理を独立して完結しなければならないこととに関連している。例えば、読み取り一貫性を保障するためにUNDOブロックを読まなければならない場合、ストレージサーバ(cellsrv)はスマートスキャンをあきらめブロックをそのままDBサーバに返却する。同様のことが行連鎖(複数ブロックにレコードがまたがった状態)した表へのアクセスでも発生する。連鎖した先のブロックはASMによる分散で同じストレージサーバ上にある保障はないためである。これらDBサーバへブロックがそのまま返却された場合、スマートスキャンによるI/O削減率が悪化し、DBサーバから大量のsingle block physical readが発生するということが発生する。以下の図はスマートスキャンの部分の内部の流れを示したものだが、右側2つの流れがスマートスキャンにならず、DBサーバへブロックをそのまま返却する流れである。
フラッシュキャッシュにヒットしたI/O数はcell flash cache read hitsで確認できる。physical read total IO requestsに対してどの程度キャッシュヒットしたかがわかる。なお、このtotalの意味はアプリケーション(SQL)だけでなく、バックアップ、リカバリおよびその他のユーティリティを含むIOを示している。totalのないphysical read IO requestsはアプリケーション(SQL)のみのI/Oを示す。従って、フラッシュキャッシュのヒット率は以下の式で求められると考える。
フラッシュキャッシュのヒット率=cell flash cache read hits / physical read total IO requests
フラッシュキャッシュおよびストレージ索引により削減されたI/O量はphysical read total bytes optimizedで確認できる。うち、ストレージインデックス分はcell physical IO bytes saved by storage indexである。ストレージインデックスはスマートスキャンのときだけ使われるが、フラッシュキャッシュは通常のブロックI/Oでも使われる点に留意したい。
なお、上記多くの内容は以下の参考文献に記載されたものをベースに自らの考察を加えたものなので、正確性は保障できないのであしからず。下図はリファレンスとして使うために上記全体を1枚にまとめてみたものである。
参考文献
- 作者: Martin Bach
- 出版社/メーカー: Apress
- 発売日: 2015/08/13
- メディア: ペーパーバック
Exadataスマートスキャンの基本 [アーキテクチャ]
スマートスキャンとは、Exadata特有のクエリの高速化技術である。この挙動については非公開の部分が多く、また、ストレージサーバソフトウェアのバージョンによって挙動が異なるため、一般的な技術資料も概要レベルにとどまっていることが多い。ここでは書籍等から得られたスマートスキャンのアーキテクチャについて記載する。内容についての正確性は保証できないのであくまで参考まで。
Exadataのスマートスキャンは、もともとDWHなど大規模DBほどストーレジとDB層間のブロック転送が性能のボトルネックになるという課題から、ストレージ層でDBサーバの処理に必要なブロックを絞って転送する技術である。実際には広くはストレージ層への処理の「オフローディング」する概念であり、その中にはブロックの解凍やカラムに対する関数の計算といった機能も含まれるが、特にフルスキャン時のI/Oの最適化をスマートスキャンと呼んでいる。
スマートスキャンにより提供される基本機能は以下の3つである。
(1)Predicate Filtering
WHERE句で絞られた必要なレコードのみDBサーバへ返却する機能。ストレージサーバ層でfilter操作を行う
(2)Column Projection
SELECT句で指定されたカラムのみDBサーバへ返却する機能。ストレージサーバ層でSELECTやWHERE句の結合カラムを絞る
(3)Storage Indexes
1MBディスクブロック毎の最大・最小値の情報を利用し、ストレージサーバ層の読み込みブロック量を削減する
上記のほかに、HASH結合におけるBloomFilter、単一行関数(数値、文字列操作)やHCCブロックの解凍もストレージサーバ側にオフロードできたりする。ポイントはこれらすべての機能はスマートスキャンが動作するときに有効になる、ということである。
なお、ストレージインデックスはあまりなじみがない機能であるため、少しここで触れておこう。巣トレージインデックスはストレージサーバ上で管理する1MB毎のストレージ領域ごとに、その最小・最大・NULLの存在を格納したものである。昔は8カラム/表までしか格納できなかったらしいが、今は255までいけるらしい(前回OOWで技術者の方から直接聞いた)。この情報はストレージサーバのメモリに格納されており、スマートスキャンのときpredicate(WHERE句)がストレージインデックスに対してチェックされ、必要なブロックを絞り込む。例えば、
select * from emp where sal > 65
というクエリを発行した場合、SQLのWHERE句からsalカラムのストレージインデックスのmin/maxが検索され、sal>65を満たす1MBブロックのみが抽出されDBサーバ層に返却されることとなる。なお、比較に使える操作は決まっており、=, <, >, BETWEEN, >=, <=, IN, IS NULL, IN NOT NULLである。ストレージインデックスで削減されたブロックはcell physical IO bytes saved by storage indexから確認できる。
スマートスキャンの発生条件は以下の3つである。
(1)セグメントのフルスキャンであること(表・パーティション・索引・マテビュー)
(2)ダイレクトパスリードであること
(3)オブジェクトはExadataに格納されていること
上記条件のうち、(1)は実行計画から確認可能、(3)は自明であるが、(2)が一番わかりにくい。ダイレクトパスリードでないとならない理由は、このスマートスキャンを実現する関数(kcfis_read... kernel cache file intelligent storage)の実装がCのコールスタックにおいてダイレクトパスリードの関数(kcbldrget... kernel cache block direct read get)の下にあるからに過ぎない。ダイレクトパスリードの発動条件については以前の記事(ダイレクトパスリードについて思うこと)にある程度記載されているのでここでは割愛する。
スマートスキャンの発生を確認する方法としては、以下の4つである。
(1)SQLトレース... cell smart table scanの待機イベントを確認できる
(2)セッション性能統計... v$sesstat, v$mystat(v$statname)でcell scansの増加を確認できる
(3)v$sqlのoffload eligible bytes... IO_CELL_OFFLOAD_ELIGIBLE_BYTESでoffloadにより削減されたI/Oが確認できる
(4)SQLモニタリング(要Diagnostic Tuning packライセンス) ... DBMS_SQL_MONITOR.REPORT_SQL_MONITORのCell Offload%で実行計画のどこがスマートスキャンか確認できる(実行中・実行直後に確認が必要)
例) set long 10000 longchuksize 10000; select dbms_sql_monitor.report_sql_monitor( sql_id=> 'xxx', report_level=>'ALL', type=>'TEXT') as report from dual;
スマートスキャンを制御する上で重要な初期化パラメータは以下3つである。商用で使うかどうかは別として、検証には非常に便利であるので、押さえておきたい。
(1) cell_offload_processing (デフォルトTRUE) ... オフロード機能を制御するパラメータ。FALSEでスマートスキャンの発生を抑止できる
(2)_serial_direct_read (デフォルトAUTO) ... シリアルダイレクトパスリードを制御する。パラメータ値としては、ALWAYS, AUTO, TRUE, FALSE, NEVERであるが、12c以降であればALWAYSとNEVERで制御できる。
(3)_kcfis_storageidx_disabled (デフォルトFALSE) ... ストレージインデックス機能を制御する。TRUEにすればストレージインデックスは使われなくなる
最後にcellsrvの複雑な挙動がある点を記載しておく。いずれもいままで経験したことはないが、スマートスキャンを期待して作りこまれた処理が、突然性能遅延が発生するようなことが起こりうる。これが発生している状況にあった場合は、解析・対処はかなり難しい状況だろう。
(1)cellsrvがoffloadをやめることがある
断片化ブロックの読み込みやconsistent readのためのUNDOブロック読み込みで発生する。ストレージサーバはお互いに通信できないため、他のストレージサーバのブロックを読み込む必要があると、DBサーバにブロックを返却せざるを得ない。この場合、smart scanとなっていても待機イベントとしてはcell single block physical readが発生する。
(2)CPU負荷が高いとcellsrvが一部のオフロード処理をしないことがある
HCCの解凍処理など、ストレージサーバのCPU負荷が高い場合、圧縮された状態でDBサーバへブロックを返却してしまう。HCC使っていなければ気にすることはないだろう
(3)cellsrvがパススルーモードになることがある
ストレージサーバがパススルーモードとなると、predicate filteringをやめてすべてのブロックをDBサーバに返却するため、cell smart table scan待機が突然大きくなる。cell num smart IO sessions using passthru mode due to cellsrvに痕跡が残るらしい。
以上
◆参考
Exadataのスマートスキャンは、もともとDWHなど大規模DBほどストーレジとDB層間のブロック転送が性能のボトルネックになるという課題から、ストレージ層でDBサーバの処理に必要なブロックを絞って転送する技術である。実際には広くはストレージ層への処理の「オフローディング」する概念であり、その中にはブロックの解凍やカラムに対する関数の計算といった機能も含まれるが、特にフルスキャン時のI/Oの最適化をスマートスキャンと呼んでいる。
スマートスキャンにより提供される基本機能は以下の3つである。
(1)Predicate Filtering
WHERE句で絞られた必要なレコードのみDBサーバへ返却する機能。ストレージサーバ層でfilter操作を行う
(2)Column Projection
SELECT句で指定されたカラムのみDBサーバへ返却する機能。ストレージサーバ層でSELECTやWHERE句の結合カラムを絞る
(3)Storage Indexes
1MBディスクブロック毎の最大・最小値の情報を利用し、ストレージサーバ層の読み込みブロック量を削減する
上記のほかに、HASH結合におけるBloomFilter、単一行関数(数値、文字列操作)やHCCブロックの解凍もストレージサーバ側にオフロードできたりする。ポイントはこれらすべての機能はスマートスキャンが動作するときに有効になる、ということである。
なお、ストレージインデックスはあまりなじみがない機能であるため、少しここで触れておこう。巣トレージインデックスはストレージサーバ上で管理する1MB毎のストレージ領域ごとに、その最小・最大・NULLの存在を格納したものである。昔は8カラム/表までしか格納できなかったらしいが、今は255までいけるらしい(前回OOWで技術者の方から直接聞いた)。この情報はストレージサーバのメモリに格納されており、スマートスキャンのときpredicate(WHERE句)がストレージインデックスに対してチェックされ、必要なブロックを絞り込む。例えば、
select * from emp where sal > 65
というクエリを発行した場合、SQLのWHERE句からsalカラムのストレージインデックスのmin/maxが検索され、sal>65を満たす1MBブロックのみが抽出されDBサーバ層に返却されることとなる。なお、比較に使える操作は決まっており、=, <, >, BETWEEN, >=, <=, IN, IS NULL, IN NOT NULLである。ストレージインデックスで削減されたブロックはcell physical IO bytes saved by storage indexから確認できる。
スマートスキャンの発生条件は以下の3つである。
(1)セグメントのフルスキャンであること(表・パーティション・索引・マテビュー)
(2)ダイレクトパスリードであること
(3)オブジェクトはExadataに格納されていること
上記条件のうち、(1)は実行計画から確認可能、(3)は自明であるが、(2)が一番わかりにくい。ダイレクトパスリードでないとならない理由は、このスマートスキャンを実現する関数(kcfis_read... kernel cache file intelligent storage)の実装がCのコールスタックにおいてダイレクトパスリードの関数(kcbldrget... kernel cache block direct read get)の下にあるからに過ぎない。ダイレクトパスリードの発動条件については以前の記事(ダイレクトパスリードについて思うこと)にある程度記載されているのでここでは割愛する。
スマートスキャンの発生を確認する方法としては、以下の4つである。
(1)SQLトレース... cell smart table scanの待機イベントを確認できる
(2)セッション性能統計... v$sesstat, v$mystat(v$statname)でcell scansの増加を確認できる
(3)v$sqlのoffload eligible bytes... IO_CELL_OFFLOAD_ELIGIBLE_BYTESでoffloadにより削減されたI/Oが確認できる
(4)SQLモニタリング(要Diagnostic Tuning packライセンス) ... DBMS_SQL_MONITOR.REPORT_SQL_MONITORのCell Offload%で実行計画のどこがスマートスキャンか確認できる(実行中・実行直後に確認が必要)
例) set long 10000 longchuksize 10000; select dbms_sql_monitor.report_sql_monitor( sql_id=> 'xxx', report_level=>'ALL', type=>'TEXT') as report from dual;
スマートスキャンを制御する上で重要な初期化パラメータは以下3つである。商用で使うかどうかは別として、検証には非常に便利であるので、押さえておきたい。
(1) cell_offload_processing (デフォルトTRUE) ... オフロード機能を制御するパラメータ。FALSEでスマートスキャンの発生を抑止できる
(2)_serial_direct_read (デフォルトAUTO) ... シリアルダイレクトパスリードを制御する。パラメータ値としては、ALWAYS, AUTO, TRUE, FALSE, NEVERであるが、12c以降であればALWAYSとNEVERで制御できる。
(3)_kcfis_storageidx_disabled (デフォルトFALSE) ... ストレージインデックス機能を制御する。TRUEにすればストレージインデックスは使われなくなる
最後にcellsrvの複雑な挙動がある点を記載しておく。いずれもいままで経験したことはないが、スマートスキャンを期待して作りこまれた処理が、突然性能遅延が発生するようなことが起こりうる。これが発生している状況にあった場合は、解析・対処はかなり難しい状況だろう。
(1)cellsrvがoffloadをやめることがある
断片化ブロックの読み込みやconsistent readのためのUNDOブロック読み込みで発生する。ストレージサーバはお互いに通信できないため、他のストレージサーバのブロックを読み込む必要があると、DBサーバにブロックを返却せざるを得ない。この場合、smart scanとなっていても待機イベントとしてはcell single block physical readが発生する。
(2)CPU負荷が高いとcellsrvが一部のオフロード処理をしないことがある
HCCの解凍処理など、ストレージサーバのCPU負荷が高い場合、圧縮された状態でDBサーバへブロックを返却してしまう。HCC使っていなければ気にすることはないだろう
(3)cellsrvがパススルーモードになることがある
ストレージサーバがパススルーモードとなると、predicate filteringをやめてすべてのブロックをDBサーバに返却するため、cell smart table scan待機が突然大きくなる。cell num smart IO sessions using passthru mode due to cellsrvに痕跡が残るらしい。
以上
◆参考
- 作者: Martin Bach
- 出版社/メーカー: Apress
- 発売日: 2015/08/13
- メディア: ペーパーバック
Exadataフラッシュキャッシュの謎 [アーキテクチャ]
相変わらずExadataのフラッシュキャッシュの性能問題に悩まされている。その解析を進める中で、そもそもそのアーキテクチャを書籍等で調査したので、その内容を以下に記載する。
◆Exadataフラッシュキャッシュとは
ExadataはRACを構成する複数のDBサーバと、ASM上にディスクグループを構成する複数のストレージサーバから構成される。例えば現在のモデルであるX7-2のハーフラックではDBサーバ4台、ストレージサーバ7台という具合である。このストレージサーバは12本のHDDと4本のフラッシュキャッシュで構成される。HDDは10TBのSAS、フラッシュキャッシュは6.4TBのPCIeカードである。このフラッシュキャッシュをExadata Smart Flash Cache (ESFC)という。ここでは単にフラッシュキャッシュと記す。
このフラッシュキャッシュであるが、Exadataのモデルチェンジ毎に倍になってきている。一方、HDDの方は概ね1.5倍ずつ増加していることと比べると、フラッシュキャッシュの進化の速度の早さを感じざるを得ない。また、容量の点でも、フラッシュキャッシュと言いつつ、X7-2ハーフラックでは物理で全179TBとなり、冗長度を考慮したとしてもかなりの規模のDBならすべてフラッシュキャッシュ上に載せたままにすることが可能な状況になってきている。当然、性能(IOPS)はHDDに比べて2桁程高い(Exadataのデータシート)ため、オンライン処理などのシングルブロックリードのワークロードに高い性能を発揮できる。
X4:F80 (800GB) vs 4TB HDD
X5:F160 (1.6TB) vs 4TB HDD
X6:F320 (3.2TB) vs 8TB HDD
X7:F640 (6.4TB) vs 10TB HDD
X7-2のフラッシュキャッシュはストレージサーバからどのように認識されているかはcellclie -e list physicaldisk where disktype=flashdiskで確認できる。4枚のフラッシュキャッシュがあり、1枚のフラッシュキャッシュが2.9TBの2つのデバイスで構成されていることがわかる。従って、実際は5.8TB/毎程度なので、物理の90%程度のサイズで認識されている。
◆Exadataフラッシュキャッシュのアーキテクチャ
フラッシュキャッシュのアーキテクチャを理解する上で、ここでは2ノードRAC構成を考える。DBサーバ#1でSELECTによりシングルブロックリードを行う単純なケースを考えてみよう。Exadataでは以下のように必要なブロックを探す。
(1)ローカルのバッファキャッシュ上からブロックを探す
(2)なければ、CacheFusionでクラスタ内のグローバルキャッシュから探す
(3)なければ、ストレージサーバへブロック要求を出す
(4)ストレージサーバがフラッシュキャッシュからブロックを探す。なければディスクから読む
(5)ストレージサーバはDBサーバへブロックを返却する
(6)ブロックがフラッシュキャッシュ上にないときは、フラッシュキャッシュへブロックを配置する
ここで特筆すべきは、(6)は非同期であるということである。ディスクから読み込まれてからフラッシュキャッシュに乗るまでにタイムラグがあることである。通常のブロックデバイスのストレージキャッシュはキャッシュを「経由」するアーキテクチャであるため、Exadata特有のクセとして認識しておいた方が良いだろう。
また、I/Oの特性によりフラッシュキャッシュに乗せる・乗せないを制御している点も興味深い。例えば、RMANバックアップやexpdp、アーカイブログ等のI/Oはフラッシュキャッシュに乗らない。さらに、フラッシュキャッシュに乗せたブロックは、どのテーブルやインデックスのオブジェクトなのかストレージサーバは知っている。フラッシュキャッシュ上のブロックはdba_objectsのdata_object_idで緋付けられている。従って、data_object_idが変更されるようなalter table文などを実行するとフラッシュキャッシュから落ちる。これも特性として理解しておく必要があるだろう。
そして、上記(4)~(6)の動作を制御しているのがcellservというプロセスであることも理解しておく必要がある。ストレージサーバでのオフロード機能(smartscan等)は恐らくすべてこのcellservで実現されていると言っても過言ではないだろう。
◆WriteBackについて
ストレージサーバへの書き込みは通常、ディスクまで書き込みを行ってから制御を戻すWriteThroughモードがデフォルトの挙動である。しかし、フラッシュキャッシュをWriteBackキャッシュとして構成することが可能である。これにより、ストレージサーバへの書き込み要求はフラッシュキャッシュへの書き込みで制御を戻すことが可能となり、ディスクへの書き込みは非同期となる。これによりOracleデータファイルの書き込みI/Oのボトルネックを解消することが可能となる。
WriteBackキャッシュはASMの冗長化が必要なため、WriteThroughモードより論理容量は減る(ASM3冗長ならWriteBackは1/3の容量となる)。また、そもそもDBWRに待機が発生していないような状況では、性能向上への効果は限定的であると考えるべきであろう。通常、DBは読み込み(特にシングルブロックリード)がI/Oのネックとなり易いため、通常はフラッシュキャッシュの領域が大きいメリットを享受できるWriteThroughが良いだろう。SGAに対して十分大きなセグメントの大量更新など、Free buffer waitsなどDBWRの書き込みの待機が発生する状況においては、WriteBackの効果が得られるだろう。
なお、現在どちらのモードになっているかは、cellcli -e list cell attributes flashcachemode detailでflashCacheModeを確認すればよい。また、構成方法についてはMOSのDocID:1500257.1が参考になる。
◆CELL_FLASH_CACHEストレージ句について
セグメントのSTORAGE句CELL_FLASH_CACHEでフラッシュキャッシュに乗せるブロックの優先度を制御することが可能である。具体的に指定可能なのは以下3つである。
・NONE:フラッシュキャッシュを使わない
・DEFAULT:小さいI/O(single block read)のブロックをフラッシュキャッシュに乗せる。デフォルトの挙動
・KEEP:フルスキャンのブロックをフラッシュキャッシュに乗せる。溢れた場合、KEEPされたブロックは最後に消される
ただしストレージサーバソフトウェアのバージョンによって挙動が違うので注意が必要である。少なくともX7-2ではDEFAULTであってもフルスキャンのブロックはフラッシュキャッシュに乗る。また、昔は24時間でKEEPはexpireされるという仕様も見直されており、残り続けるらしい。このあたりの細かな挙動には謎が多く、仕様も公開されていない。OOWでExadataの開発者に話を聞いた限り、最近ではほとんどのケースにおいてDEFAULTのままで問題ないそうだ。
常識的にKEEPを多用することで、フラッシュキャッシュが溢れるような使い方をすることは好ましくない。フラッシュキャッシュはブロックの変更をするために、内部的には空きブロックを新規に確保し既存ブロックは不要マークを付けて、非同期にガベージコレクトする方式となっているらしい。このため、溢れるような状況になると性能劣化の要因となる可能性がある。KEEPを使う場合は、KEEPすべきオブジェクトの選定し、十分に収まる範囲で使うのが良いだろう。
フラッシュキャッシュが一杯になったときの挙動はまったくの謎である。恐らくLRUにより古いブロックをパージし、新しいブロックを書き込むはずであるが、実際はそんなに単純ではない。まずフラッシュキャッシュ内の構造が謎である。Default/Keepバッファ等があり、各領域の比率もなんらかの制約があるだろう。また、アクセスパターンも読み込み(HDDからフラッシュキャッシュ)、書き込み(DBサーバからフラッシュキャッシュ)によって落とし方に違いがあるかもしれない。このあたりの挙動はmetriccurrent fc_XXXの統計を追いかけない限りわからないかもしれない。
なお、CELL_FLASH_CACHEストレージ句の設定方法は簡単である。alter table/index xxx storage (cell_flash_cache keep)すればよい。DBA_SEGMENTSのCELL_FLASH_CACHEカラムで現在の設定の状態が確認できる。
◆フラッシュキャッシュの確認方法
備忘まで、確認方法のコマンドを記載しておく。cellcliはストレージサーバ側で実行すること。
・フラッシュキャッシュに乗っている容量
cellcli -e list flashcache detail | grep effect
cellcli -e list metriccurrent fc_by_allocated, fc_by_used, fc_bykeep_used
・フラッシュキャッシュに乗っているオブジェクトの確認
SQL> select data_object_id from dba_objects where object_name='xxx'; ←テーブル名など
cellcli -e list flashcachecontent detail where objectNumber=999 detail ←999が上記SQLで返却されたdata_object_id
※objectNumberがdba_objectsのdata_object_idと紐付く
以上
◆参考文献
")
◆Exadataフラッシュキャッシュとは
ExadataはRACを構成する複数のDBサーバと、ASM上にディスクグループを構成する複数のストレージサーバから構成される。例えば現在のモデルであるX7-2のハーフラックではDBサーバ4台、ストレージサーバ7台という具合である。このストレージサーバは12本のHDDと4本のフラッシュキャッシュで構成される。HDDは10TBのSAS、フラッシュキャッシュは6.4TBのPCIeカードである。このフラッシュキャッシュをExadata Smart Flash Cache (ESFC)という。ここでは単にフラッシュキャッシュと記す。
このフラッシュキャッシュであるが、Exadataのモデルチェンジ毎に倍になってきている。一方、HDDの方は概ね1.5倍ずつ増加していることと比べると、フラッシュキャッシュの進化の速度の早さを感じざるを得ない。また、容量の点でも、フラッシュキャッシュと言いつつ、X7-2ハーフラックでは物理で全179TBとなり、冗長度を考慮したとしてもかなりの規模のDBならすべてフラッシュキャッシュ上に載せたままにすることが可能な状況になってきている。当然、性能(IOPS)はHDDに比べて2桁程高い(Exadataのデータシート)ため、オンライン処理などのシングルブロックリードのワークロードに高い性能を発揮できる。
X4:F80 (800GB) vs 4TB HDD
X5:F160 (1.6TB) vs 4TB HDD
X6:F320 (3.2TB) vs 8TB HDD
X7:F640 (6.4TB) vs 10TB HDD
X7-2のフラッシュキャッシュはストレージサーバからどのように認識されているかはcellclie -e list physicaldisk where disktype=flashdiskで確認できる。4枚のフラッシュキャッシュがあり、1枚のフラッシュキャッシュが2.9TBの2つのデバイスで構成されていることがわかる。従って、実際は5.8TB/毎程度なので、物理の90%程度のサイズで認識されている。
◆Exadataフラッシュキャッシュのアーキテクチャ
フラッシュキャッシュのアーキテクチャを理解する上で、ここでは2ノードRAC構成を考える。DBサーバ#1でSELECTによりシングルブロックリードを行う単純なケースを考えてみよう。Exadataでは以下のように必要なブロックを探す。
(1)ローカルのバッファキャッシュ上からブロックを探す
(2)なければ、CacheFusionでクラスタ内のグローバルキャッシュから探す
(3)なければ、ストレージサーバへブロック要求を出す
(4)ストレージサーバがフラッシュキャッシュからブロックを探す。なければディスクから読む
(5)ストレージサーバはDBサーバへブロックを返却する
(6)ブロックがフラッシュキャッシュ上にないときは、フラッシュキャッシュへブロックを配置する
ここで特筆すべきは、(6)は非同期であるということである。ディスクから読み込まれてからフラッシュキャッシュに乗るまでにタイムラグがあることである。通常のブロックデバイスのストレージキャッシュはキャッシュを「経由」するアーキテクチャであるため、Exadata特有のクセとして認識しておいた方が良いだろう。
また、I/Oの特性によりフラッシュキャッシュに乗せる・乗せないを制御している点も興味深い。例えば、RMANバックアップやexpdp、アーカイブログ等のI/Oはフラッシュキャッシュに乗らない。さらに、フラッシュキャッシュに乗せたブロックは、どのテーブルやインデックスのオブジェクトなのかストレージサーバは知っている。フラッシュキャッシュ上のブロックはdba_objectsのdata_object_idで緋付けられている。従って、data_object_idが変更されるようなalter table文などを実行するとフラッシュキャッシュから落ちる。これも特性として理解しておく必要があるだろう。
そして、上記(4)~(6)の動作を制御しているのがcellservというプロセスであることも理解しておく必要がある。ストレージサーバでのオフロード機能(smartscan等)は恐らくすべてこのcellservで実現されていると言っても過言ではないだろう。
◆WriteBackについて
ストレージサーバへの書き込みは通常、ディスクまで書き込みを行ってから制御を戻すWriteThroughモードがデフォルトの挙動である。しかし、フラッシュキャッシュをWriteBackキャッシュとして構成することが可能である。これにより、ストレージサーバへの書き込み要求はフラッシュキャッシュへの書き込みで制御を戻すことが可能となり、ディスクへの書き込みは非同期となる。これによりOracleデータファイルの書き込みI/Oのボトルネックを解消することが可能となる。
WriteBackキャッシュはASMの冗長化が必要なため、WriteThroughモードより論理容量は減る(ASM3冗長ならWriteBackは1/3の容量となる)。また、そもそもDBWRに待機が発生していないような状況では、性能向上への効果は限定的であると考えるべきであろう。通常、DBは読み込み(特にシングルブロックリード)がI/Oのネックとなり易いため、通常はフラッシュキャッシュの領域が大きいメリットを享受できるWriteThroughが良いだろう。SGAに対して十分大きなセグメントの大量更新など、Free buffer waitsなどDBWRの書き込みの待機が発生する状況においては、WriteBackの効果が得られるだろう。
なお、現在どちらのモードになっているかは、cellcli -e list cell attributes flashcachemode detailでflashCacheModeを確認すればよい。また、構成方法についてはMOSのDocID:1500257.1が参考になる。
◆CELL_FLASH_CACHEストレージ句について
セグメントのSTORAGE句CELL_FLASH_CACHEでフラッシュキャッシュに乗せるブロックの優先度を制御することが可能である。具体的に指定可能なのは以下3つである。
・NONE:フラッシュキャッシュを使わない
・DEFAULT:小さいI/O(single block read)のブロックをフラッシュキャッシュに乗せる。デフォルトの挙動
・KEEP:フルスキャンのブロックをフラッシュキャッシュに乗せる。溢れた場合、KEEPされたブロックは最後に消される
ただしストレージサーバソフトウェアのバージョンによって挙動が違うので注意が必要である。少なくともX7-2ではDEFAULTであってもフルスキャンのブロックはフラッシュキャッシュに乗る。また、昔は24時間でKEEPはexpireされるという仕様も見直されており、残り続けるらしい。このあたりの細かな挙動には謎が多く、仕様も公開されていない。OOWでExadataの開発者に話を聞いた限り、最近ではほとんどのケースにおいてDEFAULTのままで問題ないそうだ。
常識的にKEEPを多用することで、フラッシュキャッシュが溢れるような使い方をすることは好ましくない。フラッシュキャッシュはブロックの変更をするために、内部的には空きブロックを新規に確保し既存ブロックは不要マークを付けて、非同期にガベージコレクトする方式となっているらしい。このため、溢れるような状況になると性能劣化の要因となる可能性がある。KEEPを使う場合は、KEEPすべきオブジェクトの選定し、十分に収まる範囲で使うのが良いだろう。
フラッシュキャッシュが一杯になったときの挙動はまったくの謎である。恐らくLRUにより古いブロックをパージし、新しいブロックを書き込むはずであるが、実際はそんなに単純ではない。まずフラッシュキャッシュ内の構造が謎である。Default/Keepバッファ等があり、各領域の比率もなんらかの制約があるだろう。また、アクセスパターンも読み込み(HDDからフラッシュキャッシュ)、書き込み(DBサーバからフラッシュキャッシュ)によって落とし方に違いがあるかもしれない。このあたりの挙動はmetriccurrent fc_XXXの統計を追いかけない限りわからないかもしれない。
なお、CELL_FLASH_CACHEストレージ句の設定方法は簡単である。alter table/index xxx storage (cell_flash_cache keep)すればよい。DBA_SEGMENTSのCELL_FLASH_CACHEカラムで現在の設定の状態が確認できる。
◆フラッシュキャッシュの確認方法
備忘まで、確認方法のコマンドを記載しておく。cellcliはストレージサーバ側で実行すること。
・フラッシュキャッシュに乗っている容量
cellcli -e list flashcache detail | grep effect
cellcli -e list metriccurrent fc_by_allocated, fc_by_used, fc_bykeep_used
・フラッシュキャッシュに乗っているオブジェクトの確認
SQL> select data_object_id from dba_objects where object_name='xxx'; ←テーブル名など
cellcli -e list flashcachecontent detail where objectNumber=999 detail ←999が上記SQLで返却されたdata_object_id
※objectNumberがdba_objectsのdata_object_idと紐付く
以上
◆参考文献
- 作者: Martin Bach
- 出版社/メーカー: Apress
- 発売日: 2015/08/13
- メディア: ペーパーバック
Oracle Exadata Expert's Handbook (English Edition)
- 出版社/メーカー: Addison-Wesley Professional
- 発売日: 2015/06/12
- メディア: Kindle版
12cR2のローカルUNDOがローカルになりきれない疑惑 [アーキテクチャ]
12cR2の新機能であるローカルUNDOであるが、どうやらローカルになりきっていない疑惑がある。
業務AP実行中にORA-1555が発生したため、v$undostatsでUNDOの生成量を確認したところ、どう考えてもPDBのローカルUNDO表領域の20%にも満たない量しかUNDO_RETENTION間に生成されていない。通常、tuned_undo_retentionにより、UNDO表領域が85%程度を超えると、UNDO_RETENTIONが短く自動調整され、UNEXPIREDのものもEXPIREされてUNDO表領域あふれが発生しないように調整される。そのため、UNDO生成量がUNDO表領域のサイズに対して大きくなるとORA-1555が発生しやすくなるのは理解できる。しかし、今回は20%に満たないのはおかしい。
調べているうちに気がついたのは、CDB$ROOTのUNDO表領域のサイズに影響されたのではないか、という仮説である。CDB$ROOTのUNDO表領域は特に業務APを動かす訳ではないため、PDBより小さめに設定していた。このサイズに対し、上記UNDO生成量を計算すると、ちょうど85%程度になり、つじつまが合う。おそらく、PDBのtuned_undo_retentionの動作ロジックは、CDBのUNDOのサイズを見ているままになっている可能性がある。
MOSを見ると、機知の不具合として、CDB$ROOTのUNDO表領域のAUTOEXTENDのON・OFFが、PDBのローカルUNDOのtuned_undo_retentionの挙動に影響を与えるというものがあった。少し事象は異なるが、CDBのUNDOの設定がPDBのローカルUNDOに影響を与えてしまう、という点では似ている。
業務AP実行中にORA-1555が発生したため、v$undostatsでUNDOの生成量を確認したところ、どう考えてもPDBのローカルUNDO表領域の20%にも満たない量しかUNDO_RETENTION間に生成されていない。通常、tuned_undo_retentionにより、UNDO表領域が85%程度を超えると、UNDO_RETENTIONが短く自動調整され、UNEXPIREDのものもEXPIREされてUNDO表領域あふれが発生しないように調整される。そのため、UNDO生成量がUNDO表領域のサイズに対して大きくなるとORA-1555が発生しやすくなるのは理解できる。しかし、今回は20%に満たないのはおかしい。
調べているうちに気がついたのは、CDB$ROOTのUNDO表領域のサイズに影響されたのではないか、という仮説である。CDB$ROOTのUNDO表領域は特に業務APを動かす訳ではないため、PDBより小さめに設定していた。このサイズに対し、上記UNDO生成量を計算すると、ちょうど85%程度になり、つじつまが合う。おそらく、PDBのtuned_undo_retentionの動作ロジックは、CDBのUNDOのサイズを見ているままになっている可能性がある。
MOSを見ると、機知の不具合として、CDB$ROOTのUNDO表領域のAUTOEXTENDのON・OFFが、PDBのローカルUNDOのtuned_undo_retentionの挙動に影響を与えるというものがあった。少し事象は異なるが、CDBのUNDOの設定がPDBのローカルUNDOに影響を与えてしまう、という点では似ている。
バグ 27543971 : INCORRECT V$UNDOSTAT.TUNED_UNDORETENTION VALUE IN LOCAL UNDO MODE
結局、CDB$ROOTのUNDO表領域のサイズを、PDBのUNDO表領域のサイズと同じにすることで、ORA-1555の発生は回避することができた。不具合として認められればそのうちパッチ等が提供されるかもしれないが、それまでは暫定の回避策としてCDB$ROOTのサイズをうまく調整して誤魔化すという対応が必要そうである。
2018/11/15追記
サポートとのやりとりの結果、本事象の根本原因は上記不具合と判明。パッチは当面出ないらしい(かなり大きな修正が必要なため来年の19cでも見送られ、20cになる模様)。
以上

